Toward Fully-End-to-End Listened Speech Decoding from EEG Signals

0

Sign in to get full access
Overview
- This paper explores a method for fully end-to-end decoding of listened speech from electroencephalography (EEG) signals.
- The proposed approach aims to directly translate EEG data into text, bypassing traditional speech recognition steps.
- The researchers investigate the feasibility of this direct EEG-to-text conversion using deep learning models.
Plain English Explanation
The human brain produces electrical signals, which can be measured using a technique called electroencephalography (EEG). This paper looks at whether these EEG signals could be used to directly translate what a person is hearing into written text, without going through the usual speech recognition process.
Typically, speech recognition systems first convert audio signals into a sequence of words. This paper explores whether it's possible to skip that intermediate step and go straight from the brain's electrical activity to the final text output. The researchers use deep learning models to try to make this direct EEG-to-text conversion work.
The key idea is that the brain's electrical signals might contain enough information about the speech a person is listening to that the text could be extracted directly, without needing to first process the audio. This could be useful in situations where a person can't speak, but can still hear, such as for people with certain disabilities.
Technical Explanation
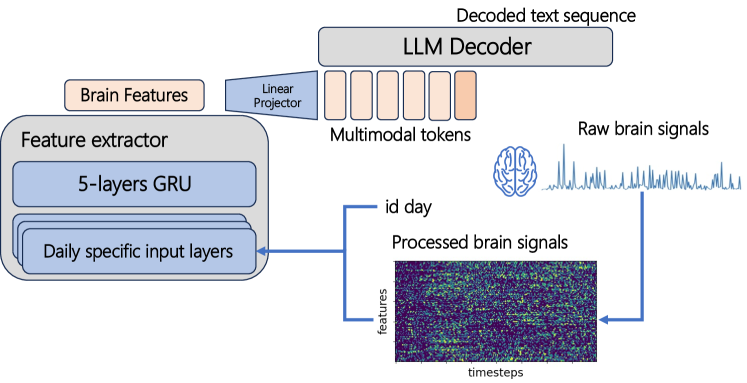
The paper proposes a fully end-to-end EEG-to-text decoding architecture that aims to directly translate EEG signals into text, without the need for intermediate speech recognition steps.
The model takes raw EEG data as input and uses a combination of convolutional and recurrent neural network layers to extract relevant features. These features are then fed into a transformer-based decoder to generate the final text output.
The researchers evaluate their approach on a dataset of EEG recordings collected while participants listened to spoken sentences. They compare the performance of their end-to-end model to a baseline system that first converts the EEG data into speech features before decoding the text.
The results suggest that the proposed end-to-end approach can achieve promising text decoding accuracy, outperforming the baseline system in certain scenarios. This indicates the feasibility of directly translating EEG signals into text, without the need for an intermediate speech recognition step.
Critical Analysis
The paper presents an interesting and ambitious approach to EEG-based speech decoding. However, the authors acknowledge several limitations and areas for further research.
One key challenge is the relatively low signal-to-noise ratio of EEG data, which can make it difficult to reliably extract the relevant information about the listened speech. The authors suggest that incorporating additional modalities, such as visual cues from lip movements, could help improve performance.
Additionally, the current model is trained and evaluated on a relatively small dataset of sentences. Scaling up to more diverse and natural speech, as well as open-vocabulary decoding, remains an important challenge for future research.
The paper also does not address the potential impact of factors like speaker variability, background noise, or individual differences in brain activity patterns. Addressing these real-world complexities will be crucial for developing robust and practical EEG-based speech decoding systems.
Conclusion
This paper presents an intriguing step towards fully end-to-end decoding of listened speech from EEG signals. The proposed deep learning-based approach shows promise in directly translating brain activity into text, bypassing the traditional speech recognition pipeline.
While further research is needed to address the current limitations, this work demonstrates the potential of using EEG data to unveil the thoughts and speech processes of the human brain. If successful, such technology could have significant implications for assistive communication systems and our understanding of the neural basis of speech perception and production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Toward Fully-End-to-End Listened Speech Decoding from EEG Signals
Jihwan Lee, Aditya Kommineni, Tiantian Feng, Kleanthis Avramidis, Xuan Shi, Sudarsana Kadiri, Shrikanth Narayanan
Speech decoding from EEG signals is a challenging task, where brain activity is modeled to estimate salient characteristics of acoustic stimuli. We propose FESDE, a novel framework for Fully-End-to-end Speech Decoding from EEG signals. Our approach aims to directly reconstruct listened speech waveforms given EEG signals, where no intermediate acoustic feature processing step is required. The proposed method consists of an EEG module and a speech module along with a connector. The EEG module learns to better represent EEG signals, while the speech module generates speech waveforms from model representations. The connector learns to bridge the distributions of the latent spaces of EEG and speech. The proposed framework is both simple and efficient, by allowing single-step inference, and outperforms prior works on objective metrics. A fine-grained phoneme analysis is conducted to unveil model characteristics of speech decoding. The source code is available here: github.com/lee-jhwn/fesde.
Read more6/14/2024
0
Towards an End-to-End Framework for Invasive Brain Signal Decoding with Large Language Models
Sheng Feng, Heyang Liu, Yu Wang, Yanfeng Wang
In this paper, we introduce a groundbreaking end-to-end (E2E) framework for decoding invasive brain signals, marking a significant advancement in the field of speech neuroprosthesis. Our methodology leverages the comprehensive reasoning abilities of large language models (LLMs) to facilitate direct decoding. By fully integrating LLMs, we achieve results comparable to the state-of-the-art cascade models. Our findings underscore the immense potential of E2E frameworks in speech neuroprosthesis, particularly as the technology behind brain-computer interfaces (BCIs) and the availability of relevant datasets continue to evolve. This work not only showcases the efficacy of combining LLMs with E2E decoding for enhancing speech neuroprosthesis but also sets a new direction for future research in BCI applications, underscoring the impact of LLMs in decoding complex neural signals for communication restoration. Code will be made available at https://github.com/FsFrancis15/BrainLLM.
Read more6/18/2024

0
Towards Linguistic Neural Representation Learning and Sentence Retrieval from Electroencephalogram Recordings
Jinzhao Zhou, Yiqun Duan, Ziyi Zhao, Yu-Cheng Chang, Yu-Kai Wang, Thomas Do, Chin-Teng Lin
Decoding linguistic information from non-invasive brain signals using EEG has gained increasing research attention due to its vast applicational potential. Recently, a number of works have adopted a generative-based framework to decode electroencephalogram (EEG) signals into sentences by utilizing the power generative capacity of pretrained large language models (LLMs). However, this approach has several drawbacks that hinder the further development of linguistic applications for brain-computer interfaces (BCIs). Specifically, the ability of the EEG encoder to learn semantic information from EEG data remains questionable, and the LLM decoder's tendency to generate sentences based on its training memory can be hard to avoid. These issues necessitate a novel approach for converting EEG signals into sentences. In this paper, we propose a novel two-step pipeline that addresses these limitations and enhances the validity of linguistic EEG decoding research. We first confirm that word-level semantic information can be learned from EEG data recorded during natural reading by training a Conformer encoder via a masked contrastive objective for word-level classification. To achieve sentence decoding results, we employ a training-free retrieval method to retrieve sentences based on the predictions from the EEG encoder. Extensive experiments and ablation studies were conducted in this paper for a comprehensive evaluation of the proposed approach. Visualization of the top prediction candidates reveals that our model effectively groups EEG segments into semantic categories with similar meanings, thereby validating its ability to learn patterns from unspoken EEG recordings. Despite the exploratory nature of this work, these results suggest that our method holds promise for providing more reliable solutions for converting EEG signals into text.
Read more8/12/2024

0
Dual-TSST: A Dual-Branch Temporal-Spectral-Spatial Transformer Model for EEG Decoding
Hongqi Li, Haodong Zhang, Yitong Chen
The decoding of electroencephalography (EEG) signals allows access to user intentions conveniently, which plays an important role in the fields of human-machine interaction. To effectively extract sufficient characteristics of the multichannel EEG, a novel decoding architecture network with a dual-branch temporal-spectral-spatial transformer (Dual-TSST) is proposed in this study. Specifically, by utilizing convolutional neural networks (CNNs) on different branches, the proposed processing network first extracts the temporal-spatial features of the original EEG and the temporal-spectral-spatial features of time-frequency domain data converted by wavelet transformation, respectively. These perceived features are then integrated by a feature fusion block, serving as the input of the transformer to capture the global long-range dependencies entailed in the non-stationary EEG, and being classified via the global average pooling and multi-layer perceptron blocks. To evaluate the efficacy of the proposed approach, the competitive experiments are conducted on three publicly available datasets of BCI IV 2a, BCI IV 2b, and SEED, with the head-to-head comparison of more than ten other state-of-the-art methods. As a result, our proposed Dual-TSST performs superiorly in various tasks, which achieves the promising EEG classification performance of average accuracy of 80.67% in BCI IV 2a, 88.64% in BCI IV 2b, and 96.65% in SEED, respectively. Extensive ablation experiments conducted between the Dual-TSST and comparative baseline model also reveal the enhanced decoding performance with each module of our proposed method. This study provides a new approach to high-performance EEG decoding, and has great potential for future CNN-Transformer based applications.
Read more9/6/2024