Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion

0
🔎
Sign in to get full access
Overview
- Camouflaged object detection (COD) aims to identify objects that blend into their surroundings.
- Deep learning-based COD relies on two key factors: a large receptive field for rich context information and an effective feature fusion strategy.
- This paper proposes a novel deep learning approach that integrates large receptive field and effective feature fusion.
Plain English Explanation
The paper presents a new method for detecting camouflaged objects, which are objects that blend into their environment. This is an important task in computer vision, as being able to spot these camouflaged objects has many applications.
The core idea is to use a deep neural network that can extract features from the image at multiple levels, from low-level details to high-level context. The network has two key components:
-
Large Receptive Field: The first part of the network uses specialized convolutional layers to capture a wide field of view, allowing it to see the broader context around potential camouflaged objects. This gives the network a better understanding of the scene.
-
Effective Feature Fusion: The second part of the network then combines these multi-level features in a smart way, using an attention mechanism to focus on the most relevant information. This allows the network to make accurate decisions about where the camouflaged objects are located.
By combining these two elements - a large receptive field and effective feature fusion - the method is able to detect camouflaged objects more accurately than previous approaches. The authors test it on standard benchmark datasets and show it outperforms the state-of-the-art.
Technical Explanation
The proposed method first extracts multi-level features from a backbone network. These features are then fed into the "dual-branch mixture convolution modules", which use a combination of asymmetric and dilated convolutional layers to capture a large receptive field and extract rich contextual information.
The features from these modules are then fused using the "multilevel interactive fusion modules". These employ an attention mechanism to selectively combine the features, focusing on the most relevant information for accurate camouflaged object detection.
The authors evaluate their method on widely-used COD benchmark datasets and show that it outperforms state-of-the-art approaches. This demonstrates the effectiveness of integrating the large receptive field and the proposed feature fusion strategy into a unified deep learning framework for COD.
Critical Analysis
The paper provides a thorough technical explanation of the proposed method and validates its performance on standard benchmarks. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, it would be helpful to understand how the method might perform on more challenging or diverse camouflage scenarios, or how sensitive it is to changes in the input data distribution. Additionally, the computational efficiency and real-time inference capabilities of the model are not explored.
Further research could also investigate the interpretability of the model's predictions, i.e., how the network arrives at its decisions for detecting camouflaged objects. This could provide valuable insights into the underlying mechanisms and lead to potential improvements.
Conclusion
This paper presents a novel deep learning method for camouflaged object detection that integrates a large receptive field and an effective feature fusion strategy. The proposed approach demonstrates state-of-the-art performance on benchmark datasets, showcasing the benefits of these key design choices.
While the technical details are well-explained, further research is needed to fully understand the limitations and potential for real-world applications of this camouflaged object detection method. Nonetheless, this work represents an important advancement in the field of computer vision and has promising implications for various domains where identifying camouflaged objects is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion
Geng Chen, Xinrui Chen, Bo Dong, Mingchen Zhuge, Yongxiong Wang, Hongbo Bi, Jian Chen, Peng Wang, Yanning Zhang
Camouflaged object detection (COD), which aims to identify the objects that conceal themselves into the surroundings, has recently drawn increasing research efforts in the field of computer vision. In practice, the success of deep learning based COD is mainly determined by two key factors, including (i) A significantly large receptive field, which provides rich context information, and (ii) An effective fusion strategy, which aggregates the rich multi-level features for accurate COD. Motivated by these observations, in this paper, we propose a novel deep learning based COD approach, which integrates the large receptive field and effective feature fusion into a unified framework. Specifically, we first extract multi-level features from a backbone network. The resulting features are then fed to the proposed dual-branch mixture convolution modules, each of which utilizes multiple asymmetric convolutional layers and two dilated convolutional layers to extract rich context features from a large receptive field. Finally, we fuse the features using specially-designed multilevel interactive fusion modules, each of which employs an attention mechanism along with feature interaction for effective feature fusion. Our method detects camouflaged objects with an effective fusion strategy, which aggregates the rich context information from a large receptive field. All of these designs meet the requirements of COD well, allowing the accurate detection of camouflaged objects. Extensive experiments on widely-used benchmark datasets demonstrate that our method is capable of accurately detecting camouflaged objects and outperforms the state-of-the-art methods.
Read more7/22/2024

0
A Survey of Camouflaged Object Detection and Beyond
Fengyang Xiao, Sujie Hu, Yuqi Shen, Chengyu Fang, Jinfa Huang, Chunming He, Longxiang Tang, Ziyun Yang, Xiu Li
Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
Read more8/28/2024
🌐
0
Depth Awakens: A Depth-perceptual Attention Fusion Network for RGB-D Camouflaged Object Detection
Xinran Liua, Lin Qia, Yuxuan Songa, Qi Wen
Camouflaged object detection (COD) presents a persistent challenge in accurately identifying objects that seamlessly blend into their surroundings. However, most existing COD models overlook the fact that visual systems operate within a genuine 3D environment. The scene depth inherent in a single 2D image provides rich spatial clues that can assist in the detection of camouflaged objects. Therefore, we propose a novel depth-perception attention fusion network that leverages the depth map as an auxiliary input to enhance the network's ability to perceive 3D information, which is typically challenging for the human eye to discern from 2D images. The network uses a trident-branch encoder to extract chromatic and depth information and their communications. Recognizing that certain regions of a depth map may not effectively highlight the camouflaged object, we introduce a depth-weighted cross-attention fusion module to dynamically adjust the fusion weights on depth and RGB feature maps. To keep the model simple without compromising effectiveness, we design a straightforward feature aggregation decoder that adaptively fuses the enhanced aggregated features. Experiments demonstrate the significant superiority of our proposed method over other states of the arts, which further validates the contribution of depth information in camouflaged object detection. The code will be available at https://github.com/xinran-liu00/DAF-Net.
Read more5/10/2024
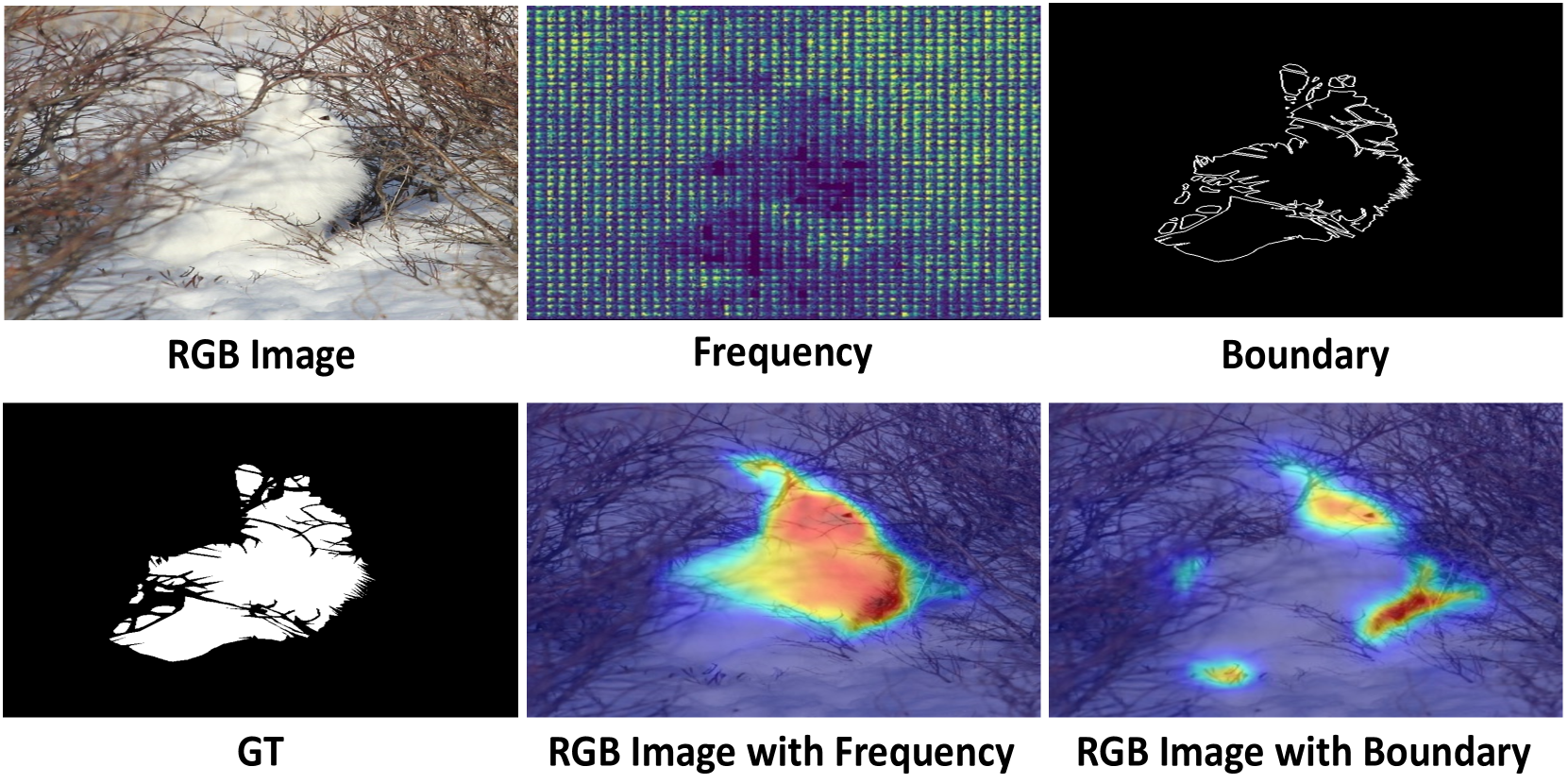
0
Adaptive Guidance Learning for Camouflaged Object Detection
Zhennan Chen, Xuying Zhang, Tian-Zhu Xiang, Ying Tai
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
Read more5/8/2024