Towards Fast Inference: Exploring and Improving Blockwise Parallel Drafts
2404.09221
0
0
Abstract
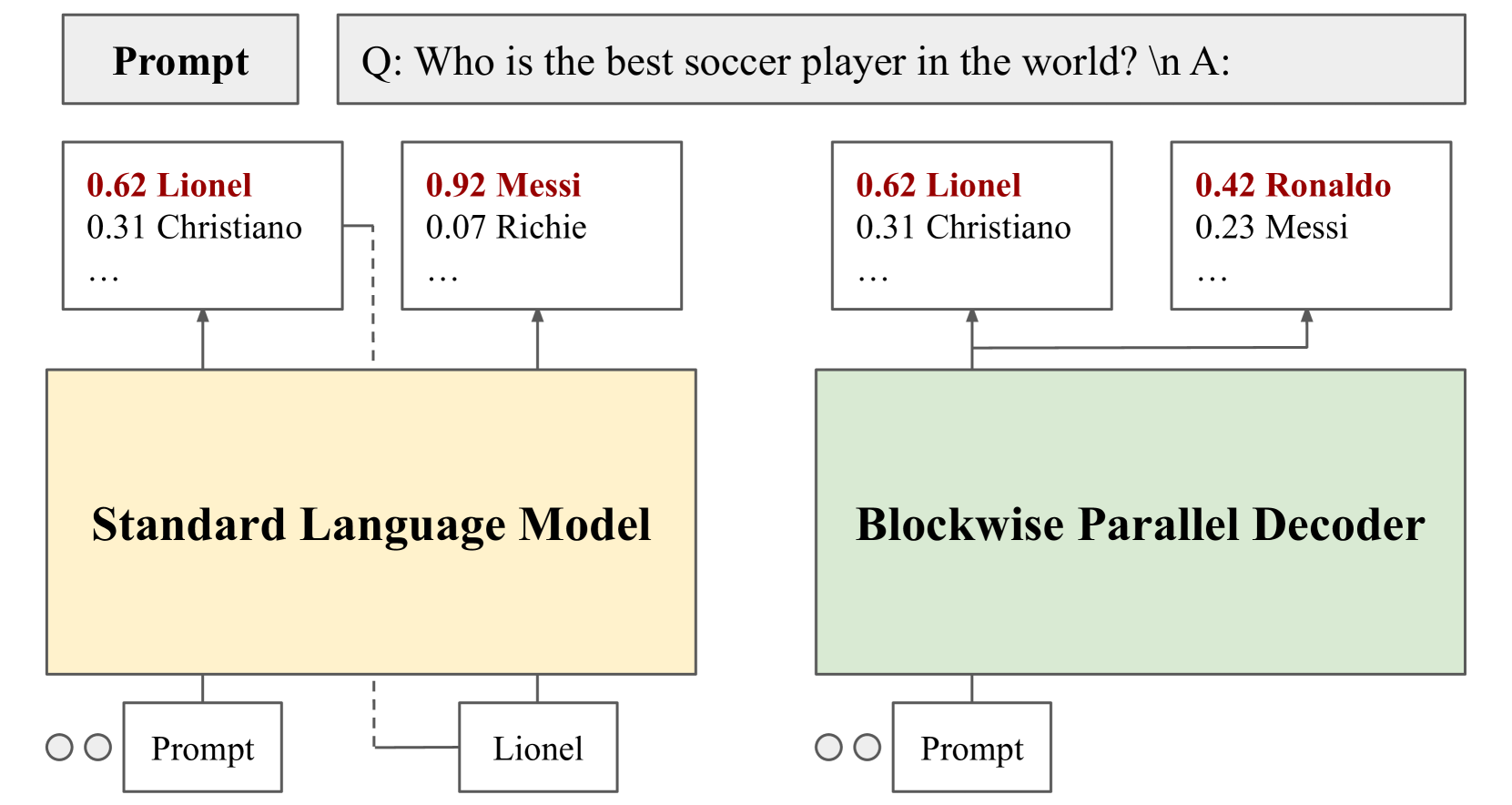
Despite the remarkable strides made by autoregressive language models, their potential is often hampered by the slow inference speeds inherent in sequential token generation. Blockwise parallel decoding (BPD) was proposed by Stern et al. (2018) as a way to improve inference speed of language models. In this paper, we make two contributions to understanding and improving BPD drafts. We first offer an analysis of the token distributions produced by the BPD prediction heads. Secondly, we use this analysis to inform algorithms to improve BPD inference speed by refining the BPD drafts using small n-gram or neural language models. We empirically show that these refined BPD drafts yield a higher average verified prefix length across tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores and improves a technique called Blockwise Parallel Drafts (BPD) to enable faster inference for large language models.
- BPD is a method that allows language models to generate text in parallel, which can significantly speed up the inference process.
- The authors analyze the behavior of BPD drafts and propose several enhancements to improve the quality and efficiency of this approach.
Plain English Explanation
Language models like GPT-3 are powerful tools for generating human-like text, but the process of generating that text can be slow, especially for long passages. The authors of this paper investigate a technique called Blockwise Parallel Drafts (BPD) that aims to speed up this inference process.
The key idea behind BPD is to break the text generation process into smaller "blocks" that can be generated in parallel, rather than sequentially. This allows the model to produce text much faster than it could by generating each word one after the other. However, the authors found that this parallel approach can sometimes result in lower-quality text, as the model may not have full context when generating each block.
To address this, the authors propose several enhancements to the BPD technique. These include using a "warmup" step to better initialize the model for each block, as well as techniques to better align the content and style of the parallel blocks. By making these improvements, the authors were able to achieve faster text generation without sacrificing too much quality.
Overall, this work explores an important challenge in making large language models more practical for real-world applications - the need for faster inference while maintaining high-quality outputs. The authors' insights and enhancements to BPD represent a step forward in this effort.
Technical Explanation
The paper begins by describing the Blockwise Parallel Drafts (BPD) technique, which allows large language models to generate text in parallel rather than sequentially. This can significantly speed up the inference process, as the model no longer has to generate each word one-by-one.
However, the authors observe that this parallel approach can sometimes lead to lower-quality text, as the model may not have full context when generating each block. To address this, they propose several enhancements to the BPD technique:
-
Warmup Initialization: Instead of initializing each block from scratch, the authors use the hidden states from the previous block as a "warmup" to better prime the model for the current block.
-
Block Alignment: The authors introduce techniques to better align the content and style of the parallel blocks, ensuring a more coherent overall output.
-
Adaptive Block Size: Rather than using a fixed block size, the authors experiment with dynamically adjusting the block size based on the complexity of the text being generated.
The authors evaluate these enhancements on a variety of language modeling tasks, including text generation, summarization, and question answering. Their results show that the improved BPD approach can achieve significant speedups (up to 2.5x) while maintaining high-quality outputs.
The paper also includes a detailed analysis of the behavior of BPD drafts, shedding light on how the parallel generation process impacts factors like repetition, consistency, and coherence.
Critical Analysis
The paper presents a compelling approach to accelerating inference for large language models, which is a critical challenge for making these models more practical and widely applicable. The authors' enhancements to the BPD technique, such as the warmup initialization and block alignment, seem well-reasoned and effective based on the reported results.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to understand how the BPD approach scales to even longer text generation tasks, or how it might perform on more open-ended generation challenges where maintaining coherence is even more difficult.
Additionally, the paper does not delve deeply into the computational and memory efficiency of the BPD approach, which could be an important consideration for real-world deployment on resource-constrained systems.
Overall, this work represents a valuable contribution to the ongoing effort to make large language models more practical and accessible. The authors' insights and techniques provide a solid foundation for further research and development in this important area.
Conclusion
This paper presents a novel approach to accelerating inference for large language models using Blockwise Parallel Drafts (BPD). The authors analyze the behavior of BPD drafts and propose several enhancements to improve the quality and efficiency of this parallel generation technique.
By introducing techniques like warmup initialization and block alignment, the authors were able to achieve significant speedups in text generation while maintaining high-quality outputs. This work represents an important step forward in making large language models more practical for real-world applications, where fast and reliable inference is a critical requirement.
While the paper does not address all potential limitations, it provides a strong foundation for further research and development in this area. As large language models continue to grow in scale and importance, techniques like those explored in this paper will be essential for unlocking their full potential.
Related Papers
Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
Jie Ou, Yueming Chen, Wenhong Tian
0
0
While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we introduce Adaptive N-gram Parallel Decoding (ANPD), an innovative and lossless approach that accelerates inference by allowing the simultaneous generation of multiple tokens. ANPD incorporates a two-stage approach: it begins with a rapid drafting phase that employs an N-gram module, which adapts based on the current interactive context, followed by a verification phase, during which the original LLM assesses and confirms the proposed tokens. Consequently, ANPD preserves the integrity of the LLM's original output while enhancing processing speed. We further leverage a multi-level architecture for the N-gram module to enhance the precision of the initial draft, consequently reducing inference latency. ANPD eliminates the need for retraining or extra GPU memory, making it an efficient and plug-and-play enhancement. In our experiments, models such as LLaMA and its fine-tuned variants have shown speed improvements up to 3.67x, validating the effectiveness of our proposed ANPD.
4/16/2024
🛸
Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Hanling Yi, Feng Lin, Hongbin Li, Peiyang Ning, Xiaotian Yu, Rong Xiao
0
0
This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose textbf{S}mart textbf{P}arallel textbf{A}uto-textbf{C}orrect dtextbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
4/17/2024
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
4/16/2024
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Pengfei Wu, Jiahao Liu, Zhuocheng Gong, Qifan Wang, Jinpeng Li, Jingang Wang, Xunliang Cai, Dongyan Zhao
0
0
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
4/19/2024