Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
2404.08698
130
0
Abstract
While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we introduce Adaptive N-gram Parallel Decoding (ANPD), an innovative and lossless approach that accelerates inference by allowing the simultaneous generation of multiple tokens. ANPD incorporates a two-stage approach: it begins with a rapid drafting phase that employs an N-gram module, which adapts based on the current interactive context, followed by a verification phase, during which the original LLM assesses and confirms the proposed tokens. Consequently, ANPD preserves the integrity of the LLM's original output while enhancing processing speed. We further leverage a multi-level architecture for the N-gram module to enhance the precision of the initial draft, consequently reducing inference latency. ANPD eliminates the need for retraining or extra GPU memory, making it an efficient and plug-and-play enhancement. In our experiments, models such as LLaMA and its fine-tuned variants have shown speed improvements up to 3.67x, validating the effectiveness of our proposed ANPD.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel technique called "Adaptive N-gram Parallel Decoding" to accelerate the inference of large language models without compromising their performance.
- The key idea is to leverage the parallel processing capabilities of modern hardware by splitting the language model's output into smaller chunks and processing them simultaneously, while adaptively adjusting the chunk size to maintain high accuracy.
- The authors demonstrate the effectiveness of their approach on various language models, including GPT-3, showcasing significant speedups without any loss in quality.
Plain English Explanation
The paper introduces a new way to speed up the process of generating text using large, powerful language models like GPT-3 without sacrificing the quality of the output. Large language models are highly capable at tasks like answering questions, generating coherent text, and understanding natural language. However, running these models can be computationally expensive and time-consuming.
The researchers' solution is to split the language model's output into smaller chunks and process them in parallel. This allows them to take advantage of the parallel processing capabilities of modern hardware, like GPUs, to generate the text much faster. Crucially, they also have a way to adaptively adjust the size of these chunks to maintain the high accuracy and quality of the output, even as the model is running faster.
The authors show that their "Adaptive N-gram Parallel Decoding" approach can significantly speed up the inference of large language models, including GPT-3, without any loss in the quality of the generated text. This is an important development, as it could make these powerful models more accessible and practical to use in a wider range of applications, from chatbots to content generation.
Technical Explanation
The key innovation of this paper is the "Adaptive N-gram Parallel Decoding" (ANPD) technique, which is designed to accelerate the inference of large language models. The core idea is to split the language model's output into smaller chunks and process them in parallel, leveraging the parallel processing capabilities of modern hardware.
To maintain the high accuracy of the language model, the researchers developed an adaptive mechanism to adjust the size of these chunks. Specifically, they use a speculative decoding approach to generate multiple candidate chunks in parallel, and then select the optimal chunk size based on the resulting quality and consistency.
The authors also introduce several novel techniques to improve the efficiency of this parallel decoding process. For example, they use a boosting approach to combine the outputs of the parallel chunks, and they investigate ways to enhance the inference efficiency of the language model itself.
Through extensive experiments on various language models, including GPT-3, the researchers demonstrate that their ANPD approach can achieve significant speedups (up to 4x) without any loss in the quality of the generated text.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to accelerating the inference of large language models. The authors have clearly put a lot of thought into addressing the key challenges, such as maintaining accuracy while exploiting parallel processing, and their proposed techniques seem to be effective.
One potential limitation of the ANPD approach is that it may not be as beneficial for shorter sequences or tasks that require very low latency, as the overhead of the parallel processing and adaptive chunk size selection could outweigh the speedup. The authors acknowledge this and suggest that their method is better suited for longer-form text generation tasks.
Additionally, the paper does not explore the impact of the ANPD approach on the broader safety and robustness of the language models. While the authors demonstrate that the quality of the generated text is maintained, there may be other considerations, such as the model's ability to handle out-of-distribution inputs or its susceptibility to adversarial attacks, that could be affected by the parallel decoding process.
Overall, this paper presents a promising and well-executed technique for accelerating large language models, and the authors have done a commendable job of rigorously evaluating its performance. However, further research may be needed to fully understand the broader implications and potential limitations of the ANPD approach.
Conclusion
This paper introduces a novel technique called "Adaptive N-gram Parallel Decoding" that can significantly speed up the inference of large language models, such as GPT-3, without compromising the quality of the generated text. By leveraging the parallel processing capabilities of modern hardware and using an adaptive mechanism to maintain accuracy, the authors demonstrate impressive speedups of up to 4x on various benchmarks.
This work represents an important step forward in making these powerful language models more accessible and practical for a wider range of applications. As large language models continue to advance and become more widely adopted, techniques like ANPD will be increasingly valuable in ensuring they can be deployed efficiently and effectively. The critical analysis suggests that there may be some limitations to the approach, but the overall contribution of this paper is a significant and impactful one for the field of natural language processing.
Related Papers
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Pengfei Wu, Jiahao Liu, Zhuocheng Gong, Qifan Wang, Jinpeng Li, Jingang Wang, Xunliang Cai, Dongyan Zhao
0
0
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
4/19/2024
🛸
Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Hanling Yi, Feng Lin, Hongbin Li, Peiyang Ning, Xiaotian Yu, Rong Xiao
0
0
This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose textbf{S}mart textbf{P}arallel textbf{A}uto-textbf{C}orrect dtextbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
4/17/2024
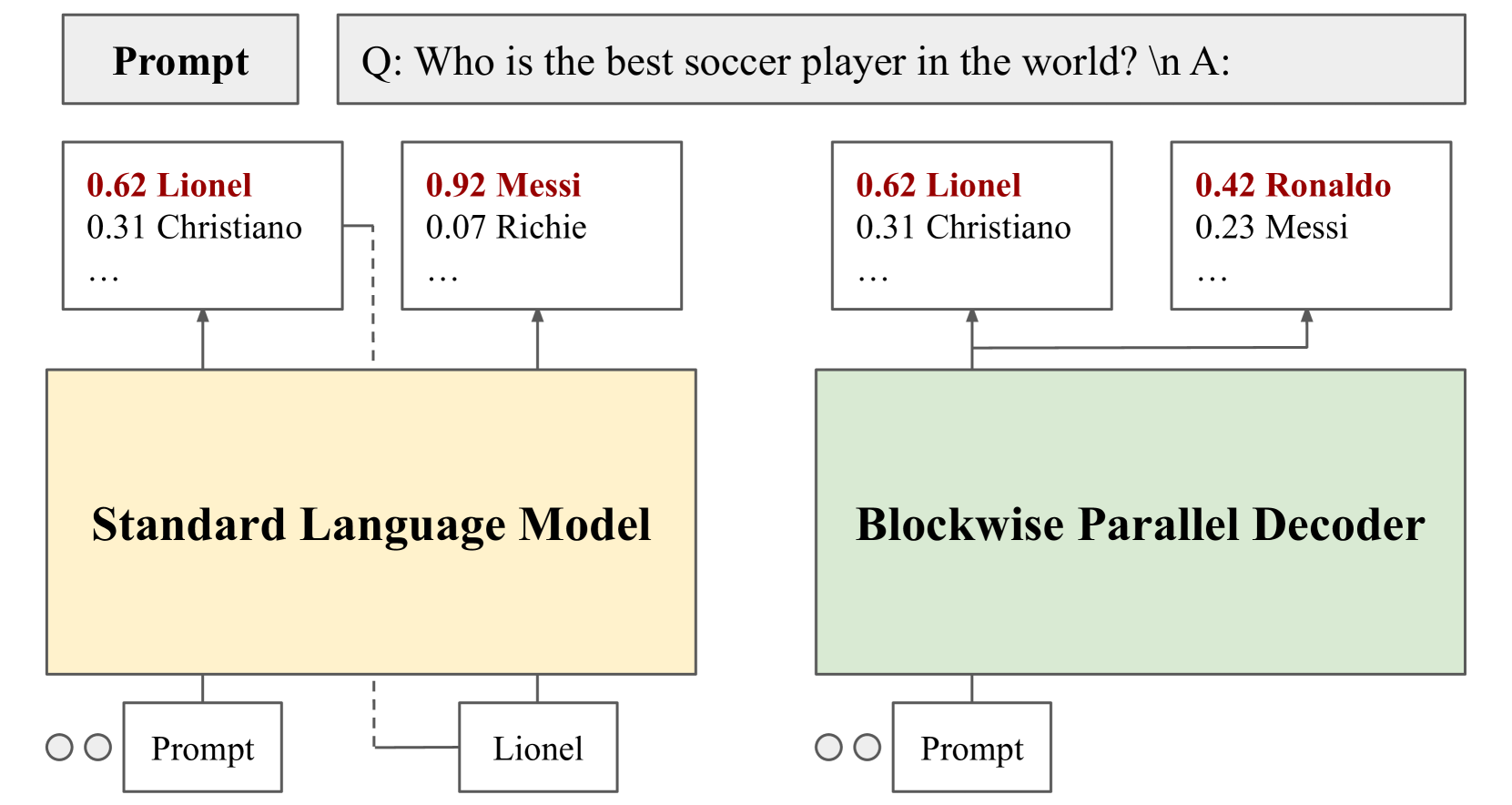
Towards Fast Inference: Exploring and Improving Blockwise Parallel Drafts
Taehyeon Kim, Ananda Theertha Suresh, Kishore Papineni, Michael Riley, Sanjiv Kumar, Adrian Benton
0
0
Despite the remarkable strides made by autoregressive language models, their potential is often hampered by the slow inference speeds inherent in sequential token generation. Blockwise parallel decoding (BPD) was proposed by Stern et al. (2018) as a way to improve inference speed of language models. In this paper, we make two contributions to understanding and improving BPD drafts. We first offer an analysis of the token distributions produced by the BPD prediction heads. Secondly, we use this analysis to inform algorithms to improve BPD inference speed by refining the BPD drafts using small n-gram or neural language models. We empirically show that these refined BPD drafts yield a higher average verified prefix length across tasks.
4/16/2024
💬
When Life gives you LLMs, make LLM-ADE: Large Language Models with Adaptive Data Engineering
Stephen Choi, William Gazeley
0
0
This paper presents the LLM-ADE framework, a novel methodology for continued pre-training of large language models (LLMs) that addresses the challenges of catastrophic forgetting and double descent. LLM-ADE employs dynamic architectural adjustments, including selective block freezing and expansion, tailored to specific datasets. This strategy enhances model adaptability to new data while preserving previously acquired knowledge. We demonstrate LLM-ADE's effectiveness on the TinyLlama model across various general knowledge benchmarks, showing significant performance improvements without the drawbacks of traditional continuous training methods. This approach promises a more versatile and robust way to keep LLMs current and efficient in real-world applications.
4/22/2024