On Speculative Decoding for Multimodal Large Language Models
2404.08856
0
0
Abstract
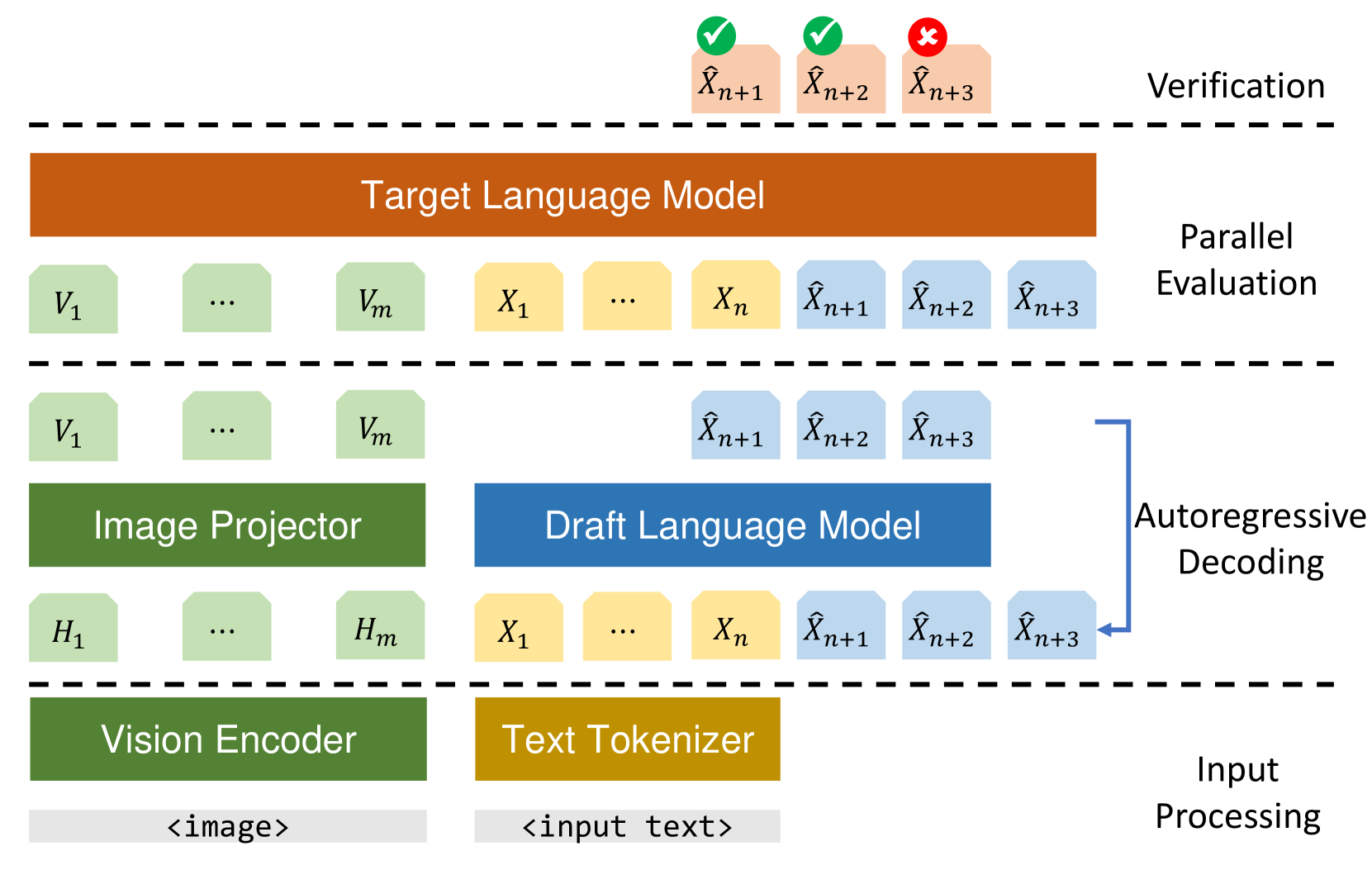
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores the use of speculative decoding for improving the efficiency of multimodal large language models
- Proposes a method to leverage speculative decoding to accelerate inference without compromising performance
- Evaluates the approach on various multimodal tasks and finds significant speedups while maintaining quality
Plain English Explanation
Large language models are powerful AI systems that can process and generate human-like text. However, running these models can be computationally expensive, making them challenging to use in real-world applications. The paper explores a technique called "speculative decoding" to address this issue.
Speculative decoding is a method that allows the model to make multiple predictions at once, rather than waiting to generate a single output. This can potentially speed up the inference process, as the model doesn't have to wait for a complete output before moving on to the next step.
The researchers apply speculative decoding to multimodal large language models, which are models that can process both text and other types of data, such as images or speech. By using speculative decoding, the researchers were able to significantly speed up the inference process for these multimodal models without compromising their performance on various tasks.
Metric-aware LLM inference and large language models for spoken language understanding are related areas of research that also aim to improve the efficiency of large language models.
Technical Explanation
The paper proposes a method for applying speculative decoding to multimodal large language models. The key idea is to generate multiple candidate outputs simultaneously, instead of waiting for a single output to be generated. This can significantly speed up the inference process, as the model doesn't have to wait for a complete output before moving on to the next step.
To implement this, the researchers modify the model's decoder to generate multiple output sequences in parallel, with each sequence representing a potential prediction. They then use a scoring mechanism to select the most promising output, which is then used as the final prediction.
The researchers evaluate their approach on a variety of multimodal tasks, including image captioning, visual question answering, and multimodal dialogue. They find that their speculative decoding approach can achieve significant speedups, often reducing inference time by 30-50%, while maintaining the same level of performance as the baseline models.
The paper also discusses the implications of their findings, including the potential for speculative decoding to be used in a wide range of applications that require fast and efficient inference, such as real-time language translation or conversational AI systems.
Critical Analysis
The paper presents a compelling approach for improving the efficiency of multimodal large language models, and the experimental results are quite promising. However, there are a few potential limitations and areas for further research that could be considered:
-
Generalizability: The paper focuses on a specific set of multimodal tasks, and it's not clear how well the speculative decoding approach would generalize to a wider range of applications or model architectures. Further research could explore the technique's performance on a more diverse set of tasks and models.
-
Tradeoffs: While the paper demonstrates significant speedups, it's possible that there could be other tradeoffs, such as increased memory usage or reduced model robustness. The researchers could explore these potential tradeoffs in more detail.
-
Interpretability: Speculative decoding introduces an additional layer of complexity to the model, which could make it more challenging to understand and interpret the model's decision-making process. Exploring ways to improve the interpretability of the speculative decoding approach could be a valuable area of research.
-
Practical Deployment: The paper focuses on the technical aspects of the approach, but there may be practical challenges in deploying speculative decoding in real-world systems, such as integration with existing infrastructure or handling dynamic input data. Addressing these practical considerations could help bridge the gap between research and practical application.
Overall, the paper presents a promising approach for improving the efficiency of multimodal large language models, and the researchers have done a commendable job in evaluating their method and discussing its implications. By addressing the potential limitations and expanding the research to a wider range of applications, the technique could have significant impact on the field of natural language processing and multimodal AI.
Conclusion
The paper demonstrates that speculative decoding can be an effective technique for improving the efficiency of multimodal large language models, achieving significant speedups without compromising performance. This has important implications for a wide range of applications that require fast and efficient inference, such as real-time language translation, conversational AI, and other multimodal tasks.
The researchers have provided a solid foundation for further research in this area, and addressing the potential limitations and practical challenges could help unlock the full potential of speculative decoding in real-world deployments. As large language models continue to play an increasingly important role in the field of AI, advancements in techniques like speculative decoding will be crucial for making these powerful models more accessible and practical for a wide range of applications.
Related Papers
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
0
0
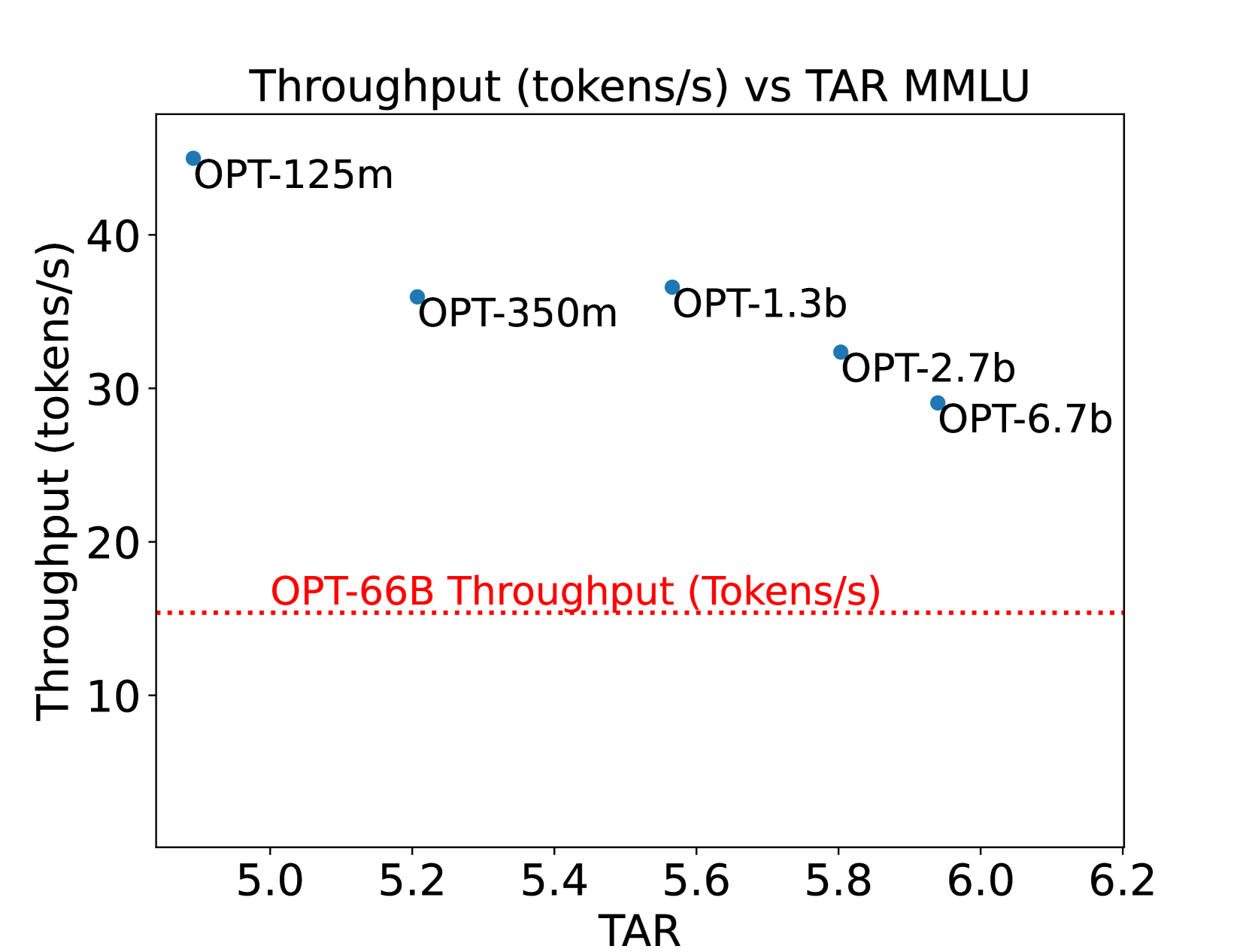
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 60% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
4/29/2024
💬
Beyond the Speculative Game: A Survey of Speculative Execution in Large Language Models
Chen Zhang, Zhuorui Liu, Dawei Song
0
0
With the increasingly giant scales of (causal) large language models (LLMs), the inference efficiency comes as one of the core concerns along the improved performance. In contrast to the memory footprint, the latency bottleneck seems to be of greater importance as there can be billions of requests to a LLM (e.g., GPT-4) per day. The bottleneck is mainly due to the autoregressive innateness of LLMs, where tokens can only be generated sequentially during decoding. To alleviate the bottleneck, the idea of speculative execution, which originates from the field of computer architecture, is introduced to LLM decoding in a textit{draft-then-verify} style. Under this regime, a sequence of tokens will be drafted in a fast pace by utilizing some heuristics, and then the tokens shall be verified in parallel by the LLM. As the costly sequential inference is parallelized, LLM decoding speed can be significantly boosted. Driven by the success of LLMs in recent couple of years, a growing literature in this direction has emerged. Yet, there lacks a position survey to summarize the current landscape and draw a roadmap for future development of this promising area. To meet this demand, we present the very first survey paper that reviews and unifies literature of speculative execution in LLMs (e.g., blockwise parallel decoding, speculative decoding, etc.) in a comprehensive framework and a systematic taxonomy. Based on the taxonomy, we present a critical review and comparative analysis of the current arts. Finally we highlight various key challenges and future directions to further develop the area.
4/24/2024
Accelerating Production LLMs with Combined Token/Embedding Speculators
Davis Wertheimer, Joshua Rosenkranz, Thomas Parnell, Sahil Suneja, Pavithra Ranganathan, Raghu Ganti, Mudhakar Srivatsa
0
0
This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
5/1/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
4/23/2024