Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
2406.16758
0
0
Abstract
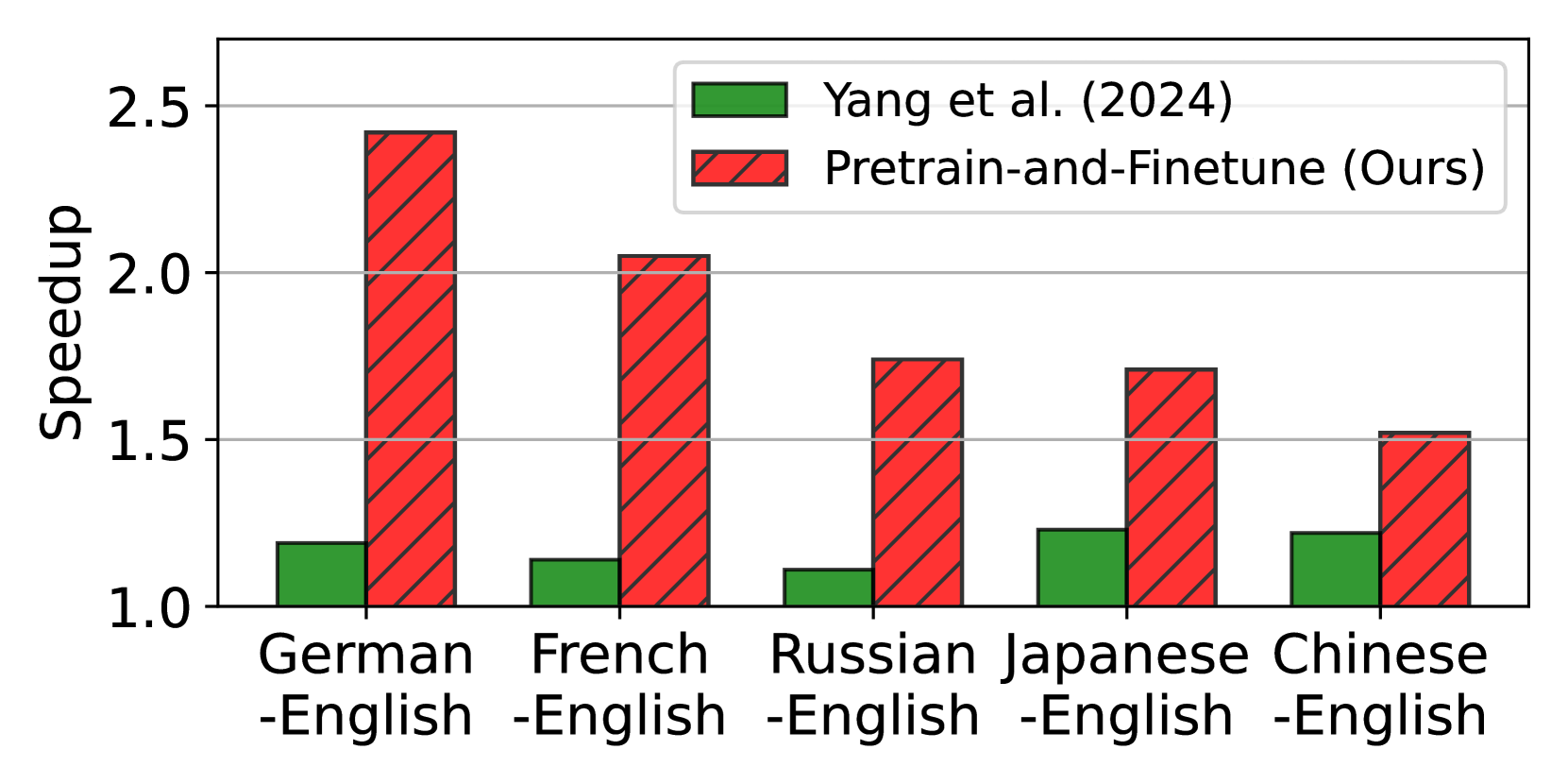
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Create account to get full access
Overview
- This paper introduces two novel techniques, Speculative Decoding and Specialized Drafters, to improve the inference speed of multilingual Large Language Models (LLMs).
- Speculative Decoding involves predicting potential future tokens before they are fully generated, allowing for faster overall decoding.
- Specialized Drafters are smaller, specialized models trained to generate initial text that can then be refined by the main LLM, further accelerating the inference process.
Plain English Explanation
The researchers in this paper have developed two new methods to make it faster for large language models to generate text in multiple languages. The first method, called Speculative Decoding, involves the model trying to guess what the next word or sentence might be before it has finished generating the full output. This allows the model to work ahead and produce the text more quickly.
The second method, called Specialized Drafters, uses smaller, more focused models to generate an initial draft of the text. This draft can then be refined and polished by the main, larger language model, again speeding up the overall process.
By combining these two techniques, the researchers aim to unlock significant efficiency gains in how large language models operate, particularly when handling text in multiple languages. This could lead to faster, more responsive language AI systems that are better able to communicate with users in their preferred languages.
Technical Explanation
The paper introduces two main techniques to accelerate multilingual LLM inference:
-
Speculative Decoding: This approach involves predicting potential future tokens before they are fully generated, allowing the model to work ahead and produce text more quickly. The researchers develop a novel "speculative" decoding algorithm that can accurately forecast the most likely next tokens, reducing the total computation required.
-
Specialized Drafters: The researchers train smaller, more specialized "drafter" models to generate an initial draft of the output text. This draft can then be efficiently refined by the main LLM, rather than having the LLM generate the entire text from scratch.
The paper evaluates these techniques across a range of multilingual benchmarks, demonstrating significant speedups in inference time without sacrificing output quality. For example, the direct alignment of the drafter and LLM models is shown to provide a 2-3x acceleration.
Overall, the innovations in Speculative Decoding and Specialized Drafters represent important steps towards unlocking the efficiency of large language models, particularly in multilingual settings.
Critical Analysis
The paper presents a compelling approach to improving the inference speed of multilingual LLMs, but there are a few potential caveats worth considering:
-
Generalization: While the techniques are evaluated on several benchmarks, it's unclear how well they would generalize to a broader range of languages, domains, and use cases. Further testing may be needed to assess the robustness of the methods.
-
Computational Overhead: The researchers note that the specialized drafter models add some computational overhead, which could offset the gains from speculative decoding in certain scenarios. The trade-offs between speed, model complexity, and resource requirements would need to be carefully evaluated.
-
Impact on Output Quality: While the paper shows that the proposed methods maintain output quality, it's possible that certain nuances or subtle aspects of the language could be lost or distorted in the interest of speed. The implications for downstream applications would require further investigation.
Overall, the innovations in this paper represent a promising step forward, but additional research and real-world testing would be valuable to fully understand the strengths, limitations, and broader implications of these techniques.
Conclusion
This paper introduces two novel methods, Speculative Decoding and Specialized Drafters, to significantly accelerate the inference of multilingual Large Language Models. By predicting future tokens and leveraging smaller, specialized models, the researchers have demonstrated substantial improvements in inference speed without sacrificing output quality.
These techniques have the potential to unlock new possibilities in how large language models are deployed, enabling faster, more responsive AI systems that can communicate fluently in multiple languages. As the field of natural language processing continues to advance, innovations like those presented in this paper will be crucial for making these powerful technologies more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
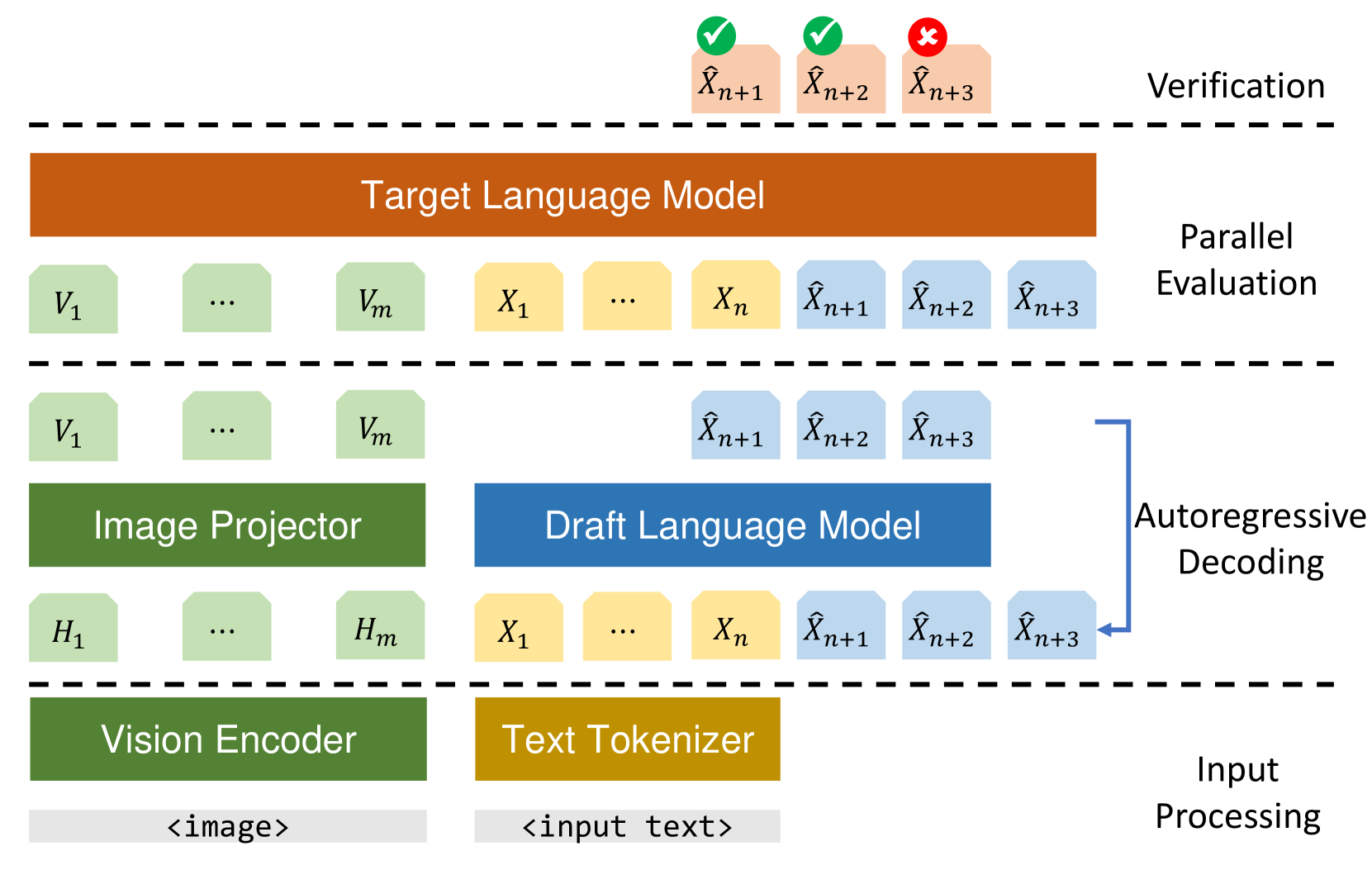
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
4/16/2024
💬
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra
0
0
We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting. Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM. Moreover, the proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its variants demonstrated a speedup up to 1.99$times$.
5/21/2024
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
0
0
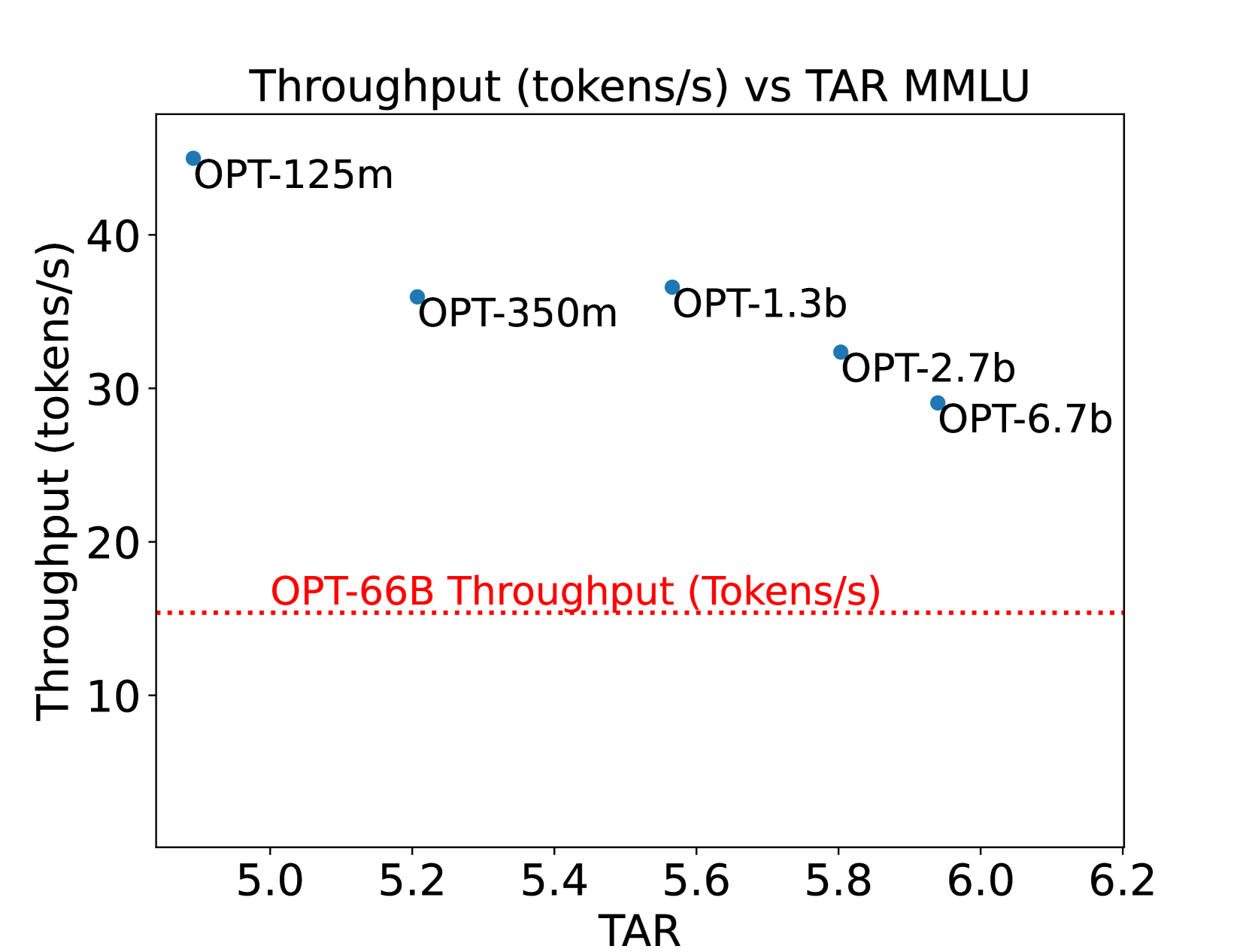
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 60% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
4/29/2024
Direct Alignment of Draft Model for Speculative Decoding with Chat-Fine-Tuned LLMs
Raghavv Goel, Mukul Gagrani, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
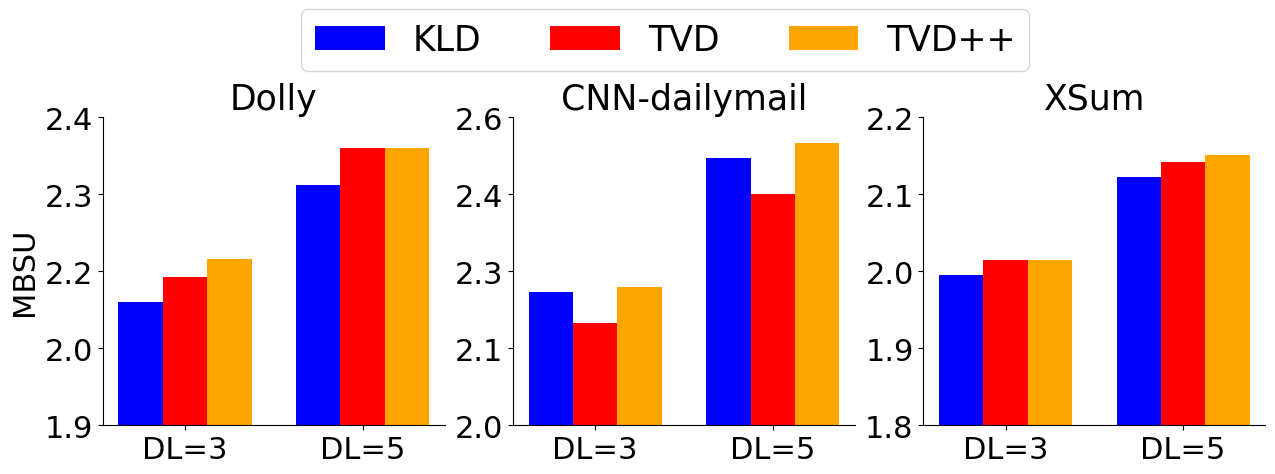
Text generation with Large Language Models (LLMs) is known to be memory bound due to the combination of their auto-regressive nature, huge parameter counts, and limited memory bandwidths, often resulting in low token rates. Speculative decoding has been proposed as a solution for LLM inference acceleration. However, since draft models are often unavailable in the modern open-source LLM families, e.g., for Llama 2 7B, training a high-quality draft model is required to enable inference acceleration via speculative decoding. In this paper, we propose a simple draft model training framework for direct alignment to chat-capable target models. With the proposed framework, we train Llama 2 Chat Drafter 115M, a draft model for Llama 2 Chat 7B or larger, with only 1.64% of the original size. Our training framework only consists of pretraining, distillation dataset generation, and finetuning with knowledge distillation, with no additional alignment procedure. For the finetuning step, we use instruction-response pairs generated by target model for distillation in plausible data distribution, and propose a new Total Variation Distance++ (TVD++) loss that incorporates variance reduction techniques inspired from the policy gradient method in reinforcement learning. Our empirical results show that Llama 2 Chat Drafter 115M with speculative decoding achieves up to 2.3 block efficiency and 2.4$times$ speed-up relative to autoregressive decoding on various tasks with no further task-specific fine-tuning.
5/15/2024