Towards flexible perception with visual memory

0

Sign in to get full access
Overview
- This paper explores a novel approach to visual perception and classification that leverages a retrieval-based visual memory.
- The key idea is to build a memory of visual exemplars that can be efficiently retrieved and used to inform classification decisions.
- The authors demonstrate that this approach can lead to more flexible and robust visual perception compared to standard approaches.
Plain English Explanation
The paper proposes a new way for computer vision systems to recognize and classify objects in images. Instead of the typical approach of training a neural network to directly map image inputs to class labels, the authors suggest building a visual memory - a database of visual exemplars that the system can efficiently retrieve and use to inform its classification decisions.
The core idea is that by having access to a rich set of visual examples, the system can become more flexible and adaptable in its perception. Rather than relying solely on the patterns it was trained on, the system can dynamically retrieve relevant visual memories to help it make sense of new inputs. This could allow the system to better generalize to novel situations and handle greater visual variability.
The paper describes the process of building this retrieval-based visual memory and how it can be integrated into a classification pipeline. The authors also present experimental results demonstrating the benefits of this approach compared to standard classification methods.
Technical Explanation
The paper introduces a new framework for visual perception that leverages a retrieval-based visual memory. At a high level, the approach involves:
-
Building a Visual Memory: The system first constructs a memory bank of visual exemplars, where each exemplar is represented by a compact feature vector. This memory bank is organized to enable efficient retrieval of relevant exemplars given a new input image.
-
Retrieval-based Classification: When presented with a new input image, the system retrieves the most relevant exemplars from its visual memory. It then uses these retrieved exemplars, along with the input image, to inform its final classification decision.
The authors evaluate this approach on standard image classification benchmarks and show that it can outperform standard end-to-end classification models, particularly in terms of flexibility and robustness to distributional shift. The intuition is that by having access to a diverse set of visual memories, the system can better adapt to novel situations and handle greater visual variability.
The paper also includes an in-depth analysis of the learned visual memory, exploring how the exemplars are organized and how they contribute to classification decisions.
Critical Analysis
The paper presents a compelling and well-executed exploration of the potential benefits of a retrieval-based approach to visual perception. The authors make a strong case for the advantages of this approach in terms of flexibility and robustness, and the experimental results are convincing.
However, the paper does not fully address some potential limitations and areas for further research. For example, the scalability of the visual memory as the number of exemplars grows could be a concern, and the authors do not discuss how the memory might be updated or adapted over time.
Additionally, while the paper demonstrates the advantages of this approach on standard benchmarks, it would be interesting to see how it performs on more challenging or real-world visual perception tasks, where the value of a flexible, retrieval-based system might be even more pronounced.
Overall, this paper makes a significant contribution to the field of computer vision by introducing a novel and promising approach to visual perception. Further research and development in this area could lead to more robust and adaptable visual AI systems.
Conclusion
This paper presents a novel approach to visual perception that leverages a retrieval-based visual memory. By building a rich database of visual exemplars and efficiently retrieving relevant memories to inform classification decisions, the system can achieve greater flexibility and robustness compared to standard end-to-end classification models.
The experimental results demonstrate the benefits of this approach, and the paper provides a detailed technical explanation of the framework. While the paper does not address all potential limitations, it represents an important step forward in the development of more adaptable and capable visual AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards flexible perception with visual memory
Robert Geirhos, Priyank Jaini, Austin Stone, Sourabh Medapati, Xi Yi, George Toderici, Abhijit Ogale, Jonathon Shlens
Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network's weights. We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database. Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities: (1.) The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data; (2.) The ability to remove data through unlearning and memory pruning; (3.) An interpretable decision-mechanism on which we can intervene to control its behavior. Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models -- beyond carving it in ``stone'' weights.
Read more8/16/2024
0
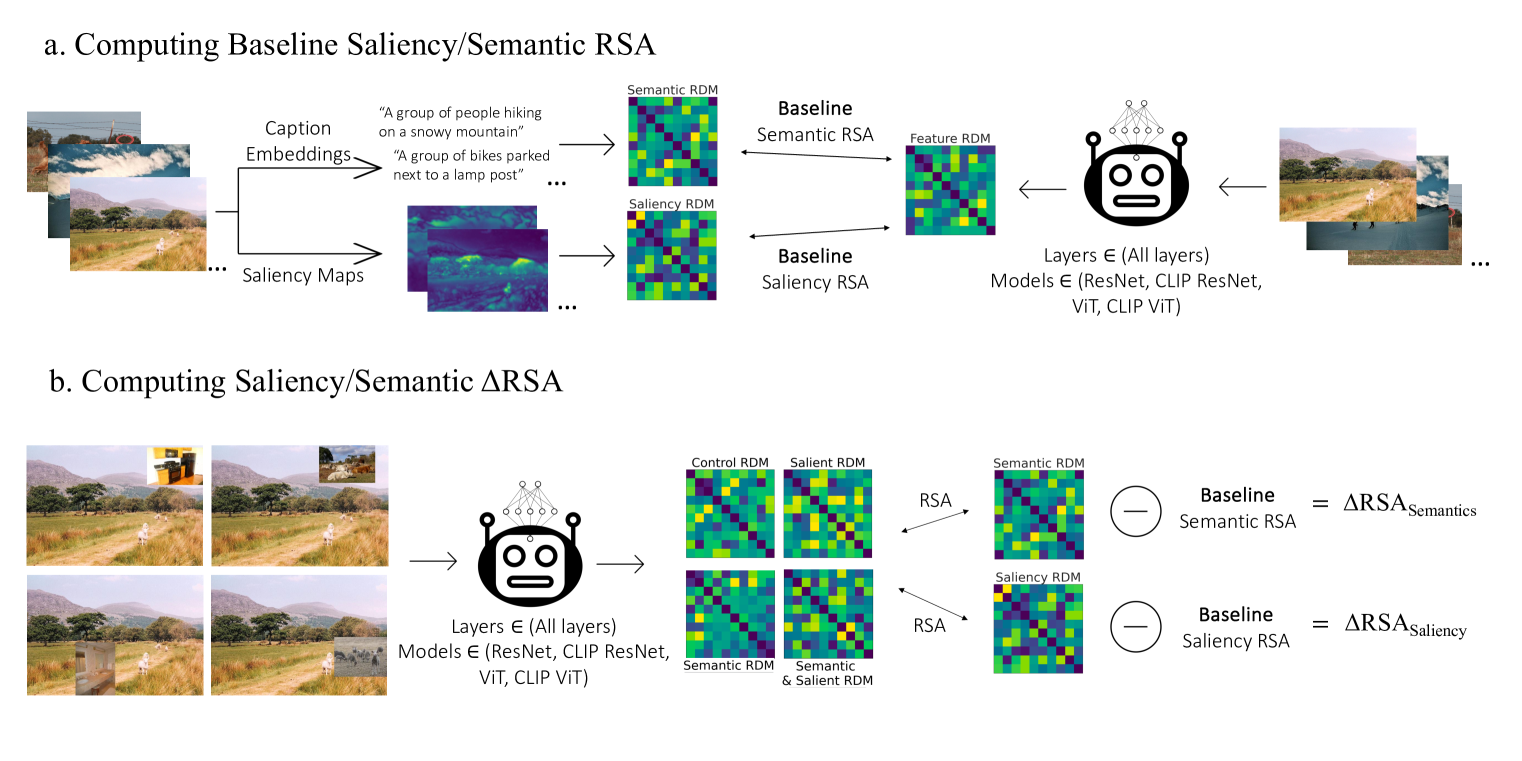
Saliency Suppressed, Semantics Surfaced: Visual Transformations in Neural Networks and the Brain
Gustaw Opie{l}ka, Jessica Loke, Steven Scholte
Deep learning algorithms lack human-interpretable accounts of how they transform raw visual input into a robust semantic understanding, which impedes comparisons between different architectures, training objectives, and the human brain. In this work, we take inspiration from neuroscience and employ representational approaches to shed light on how neural networks encode information at low (visual saliency) and high (semantic similarity) levels of abstraction. Moreover, we introduce a custom image dataset where we systematically manipulate salient and semantic information. We find that ResNets are more sensitive to saliency information than ViTs, when trained with object classification objectives. We uncover that networks suppress saliency in early layers, a process enhanced by natural language supervision (CLIP) in ResNets. CLIP also enhances semantic encoding in both architectures. Finally, we show that semantic encoding is a key factor in aligning AI with human visual perception, while saliency suppression is a non-brain-like strategy.
Read more4/30/2024

0
Growing Deep Neural Network Considering with Similarity between Neurons
Taigo Sakai, Kazuhiro Hotta
Deep learning has excelled in image recognition tasks through neural networks inspired by the human brain. However, the necessity for large models to improve prediction accuracy introduces significant computational demands and extended training times.Conventional methods such as fine-tuning, knowledge distillation, and pruning have the limitations like potential accuracy drops. Drawing inspiration from human neurogenesis, where neuron formation continues into adulthood, we explore a novel approach of progressively increasing neuron numbers in compact models during training phases, thereby managing computational costs effectively. We propose a method that reduces feature extraction biases and neuronal redundancy by introducing constraints based on neuron similarity distributions. This approach not only fosters efficient learning in new neurons but also enhances feature extraction relevancy for given tasks. Results on CIFAR-10 and CIFAR-100 datasets demonstrated accuracy improvement, and our method pays more attention to whole object to be classified in comparison with conventional method through Grad-CAM visualizations. These results suggest that our method's potential to decision-making processes.
Read more8/27/2024
0
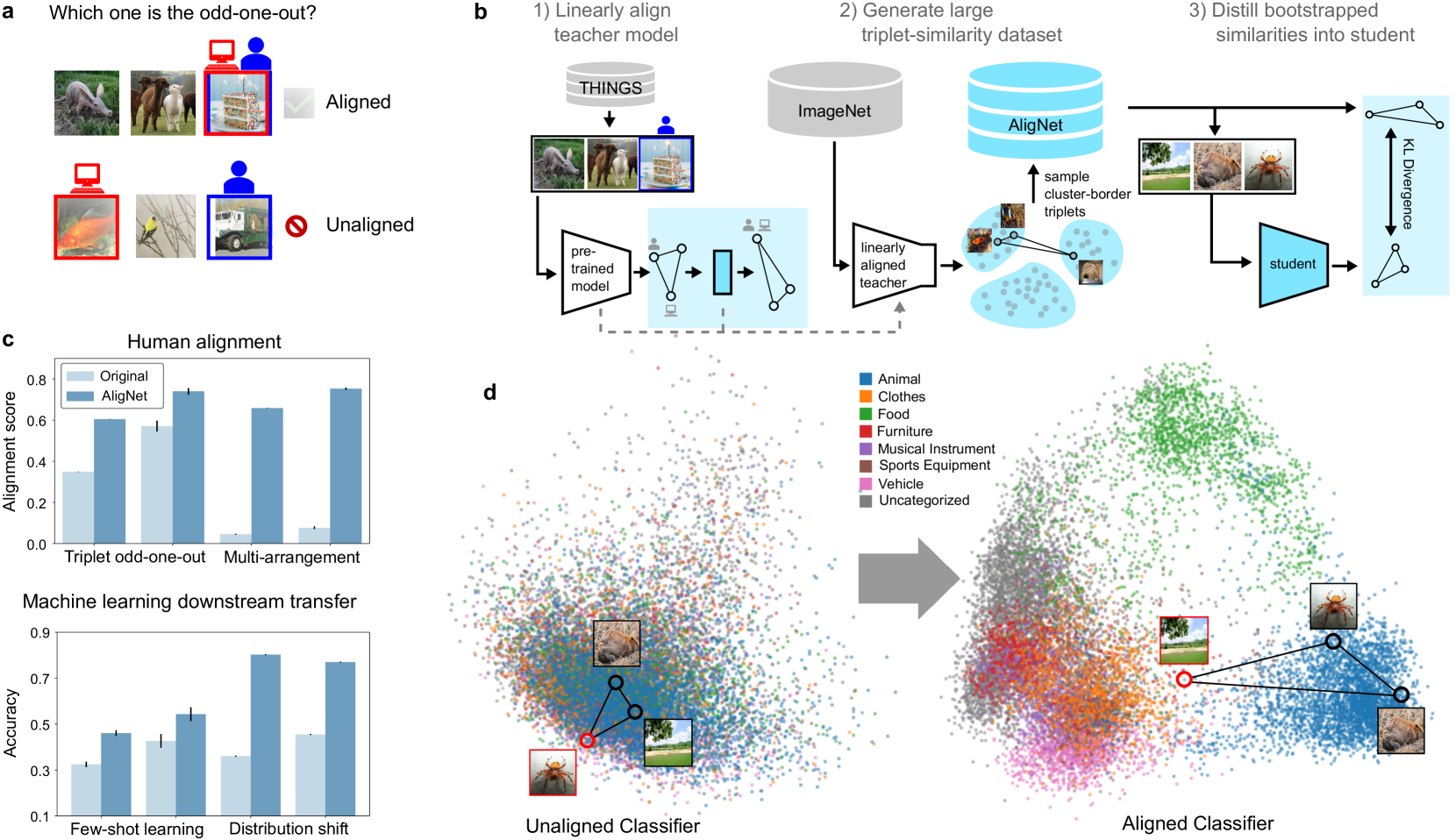
Aligning Machine and Human Visual Representations across Abstraction Levels
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C. Mozer, Klaus-Robert Muller, Thomas Unterthiner, Andrew K. Lampinen
Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Read more9/11/2024