Saliency Suppressed, Semantics Surfaced: Visual Transformations in Neural Networks and the Brain
2404.18772
0
0
Abstract
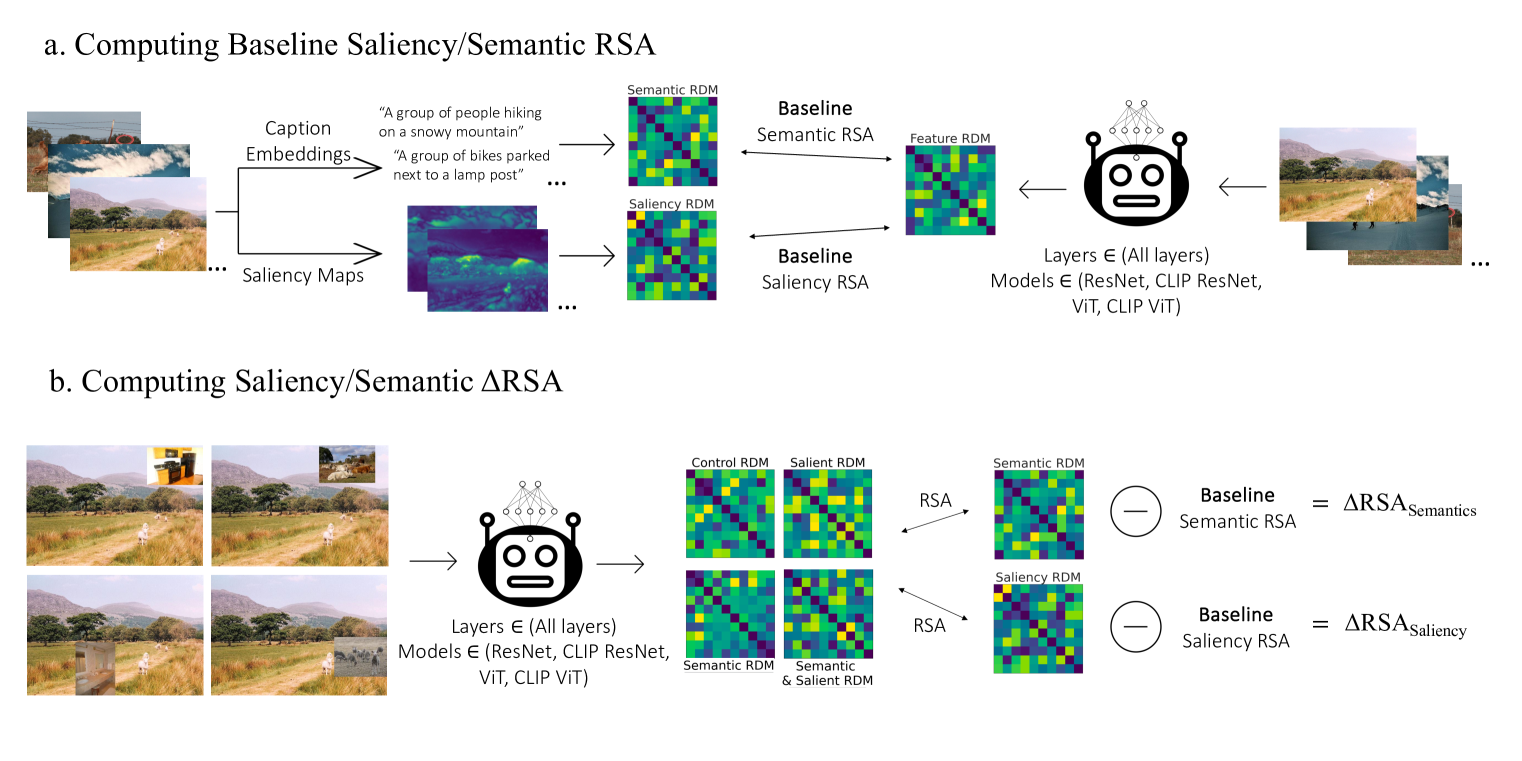
Deep learning algorithms lack human-interpretable accounts of how they transform raw visual input into a robust semantic understanding, which impedes comparisons between different architectures, training objectives, and the human brain. In this work, we take inspiration from neuroscience and employ representational approaches to shed light on how neural networks encode information at low (visual saliency) and high (semantic similarity) levels of abstraction. Moreover, we introduce a custom image dataset where we systematically manipulate salient and semantic information. We find that ResNets are more sensitive to saliency information than ViTs, when trained with object classification objectives. We uncover that networks suppress saliency in early layers, a process enhanced by natural language supervision (CLIP) in ResNets. CLIP also enhances semantic encoding in both architectures. Finally, we show that semantic encoding is a key factor in aligning AI with human visual perception, while saliency suppression is a non-brain-like strategy.
Create account to get full access
Overview
- This paper explores how neural networks and the brain process visual information, focusing on the relationship between saliency (the ability to draw attention) and semantics (the meaning or significance of visual elements).
- The researchers investigate how visual transformers in neural networks and the human visual cortex transform visual inputs, suppressing saliency while surfacing semantic information.
- The findings provide insights into the mechanisms underlying visual perception and cognition, with implications for few-shot learning, saliency prediction, and adversarial robustness in artificial and biological vision systems.
Plain English Explanation
The paper explores how neural networks and the human brain process visual information. It focuses on the relationship between two key concepts: saliency and semantics.
Saliency refers to the ability of certain visual elements to draw our attention. These are the things that "pop out" and immediately catch our eye, like a bright color or a distinctive shape. Semantics, on the other hand, refers to the meaning or significance of visual elements - what they represent or symbolize.
The researchers investigate how neural networks and the human visual cortex transform visual inputs, suppressing saliency while surfacing semantic information. In other words, as we process visual scenes, our attention shifts away from the most salient parts and towards the more meaningful or conceptual elements.
This is an important finding because it suggests that our visual perception is not just about identifying the most attention-grabbing parts of an image. Instead, our brains are actively extracting the deeper meaning and significance of what we see, even if those elements aren't the most visually striking.
The researchers believe these insights could have implications for various fields, such as few-shot learning, where models need to quickly learn from limited data, and saliency prediction, which is important for applications like autonomous driving. The findings may also shed light on the mechanisms behind adversarial robustness in both artificial and biological vision systems.
Technical Explanation
The paper investigates how neural networks and the human visual cortex transform visual inputs, focusing on the relationship between saliency and semantics. The researchers use a combination of computational modeling and neuroscientific experiments to explore this phenomenon.
In the neural network experiments, the team trained vision transformers on image classification tasks and analyzed the internal representations of the models. They found that as the networks processed visual inputs, the representations became less focused on salient features and more attuned to semantic information.
Similarly, in the neuroscientific experiments, the researchers used functional magnetic resonance imaging (fMRI) to study brain activity in the visual cortex of human subjects as they viewed various images. The results showed that activity in higher-level visual areas was more correlated with semantic processing, while lower-level areas were more sensitive to saliency.
The researchers propose that this saliency-to-semantics transformation is a fundamental feature of both artificial and biological vision systems. They suggest that this shift in focus from salient to semantic information may underlie key capabilities, such as few-shot learning and adversarial robustness, as well as inform the development of more contextual saliency prediction models.
Critical Analysis
The paper provides a compelling account of how both artificial and biological vision systems transform visual inputs, shifting from a focus on saliency to a focus on semantics. The researchers' use of computational modeling and neuroscientific experimentation lends credibility to their findings and offers a multifaceted perspective on this phenomenon.
One potential limitation of the study is the scope of the neural network experiments, which were primarily focused on image classification tasks. It would be interesting to see how these saliency-to-semantics transformations manifest in other computer vision tasks, such as object detection, segmentation, or scene understanding.
Additionally, the paper does not delve deeply into the potential mechanisms underlying this transformation. While the researchers propose that it may be a fundamental feature of vision systems, further research is needed to elucidate the specific neural or computational processes involved.
Despite these minor caveats, the study makes a significant contribution to our understanding of visual perception and cognition. The insights gleaned from this work could have far-reaching implications, informing the development of more concept-based and semantically-aware artificial vision systems, as well as providing new avenues for investigating the workings of the human visual cortex.
Conclusion
This paper presents a fascinating exploration of how neural networks and the human brain process visual information, with a focus on the relationship between saliency and semantics. The researchers demonstrate that as visual inputs are transformed, the emphasis shifts from salient features to semantic information, a phenomenon observed in both artificial and biological vision systems.
The implications of this work are broad, spanning fields such as few-shot learning, saliency prediction, and adversarial robustness. By shedding light on the mechanisms underlying visual perception and cognition, this research could pave the way for more sophisticated and contextually-aware artificial vision systems, as well as deepen our understanding of the human visual cortex.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Alexander Kroner, Mario Senden, Kurt Driessens, Rainer Goebel
0
0
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes.
4/8/2024

Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
0
0
While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
6/11/2024
🔮
Bridging the Gap Between Saliency Prediction and Image Quality Assessment
Kirillov Alexey, Andrey Moskalenko, Dmitriy Vatolin
0
0
Over the past few years, deep neural models have made considerable advances in image quality assessment (IQA). However, the underlying reasons for their success remain unclear, owing to the complex nature of deep neural networks. IQA aims to describe how the human visual system (HVS) works and to create its efficient approximations. On the other hand, Saliency Prediction task aims to emulate HVS via determining areas of visual interest. Thus, we believe that saliency plays a crucial role in human perception. In this work, we conduct an empirical study that reveals the relation between IQA and Saliency Prediction tasks, demonstrating that the former incorporates knowledge of the latter. Moreover, we introduce a novel SACID dataset of saliency-aware compressed images and conduct a large-scale comparison of classic and neural-based IQA methods. All supplementary code and data will be available at the time of publication.
5/9/2024
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
0
0
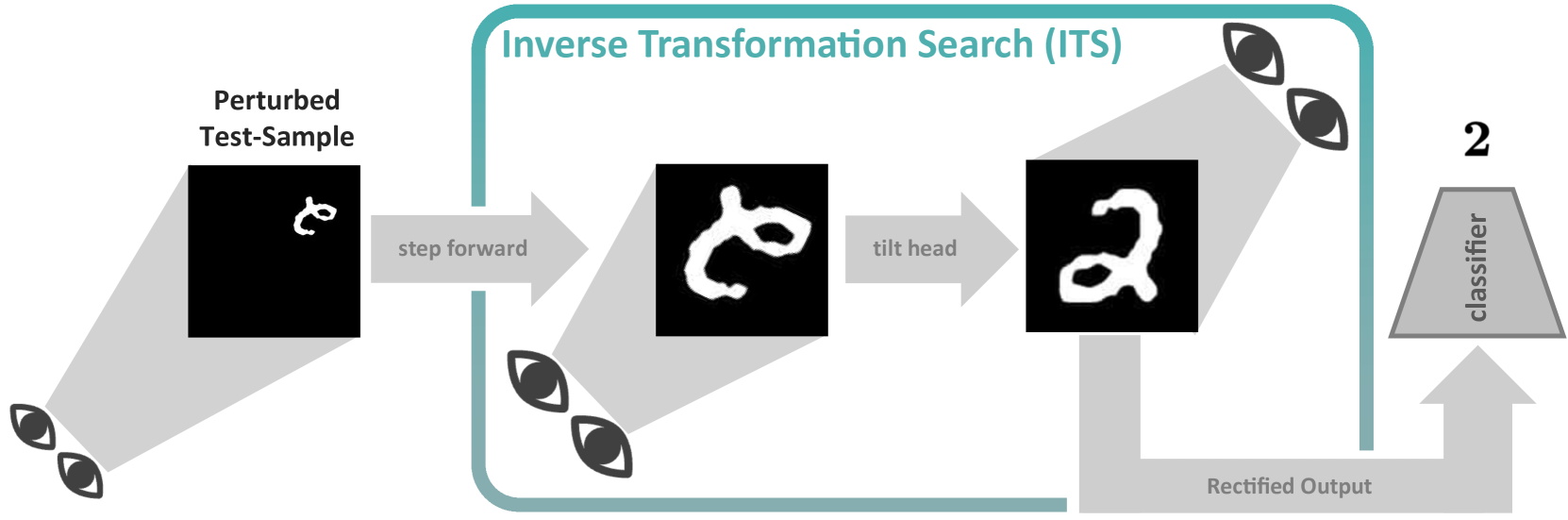
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
5/28/2024