Towards Global Localization using Multi-Modal Object-Instance Re-Identification

0
Sign in to get full access
Overview
- Describes a method for global localization using multi-modal object-instance re-identification
- Focuses on leveraging visual, thermal, and semantic information to accurately identify and locate objects across different scenes
- Aims to enable robust and scalable location recognition for various applications, such as robotics and autonomous systems
Plain English Explanation
The paper presents a new approach for global localization - the ability to determine the precise location of an object in a large-scale environment. The key idea is to use multi-modal object-instance re-identification, which combines information from different sensor modalities like visual, thermal, and semantic data to accurately identify and track objects across different scenes.
This is important for applications like robotics and autonomous systems, where the ability to precisely locate objects and understand their spatial context is crucial. By leveraging multiple data sources, the method aims to be more robust and scalable than approaches that rely on a single modality.
Technical Explanation
The paper proposes a framework that fuses visual, thermal, and semantic information to enable global localization of objects. The core components include:
-
Object Detection: The system first detects and segments objects of interest in each scene using a combination of visual and thermal data.
-
Object Re-Identification: A multi-modal object re-identification module then associates the detected objects across different scenes, allowing the system to track the same objects over time and space.
-
Semantic Fusion: Semantic information, such as object category labels, is incorporated to further improve the re-identification accuracy and provide contextual understanding.
-
Global Localization: By combining the object re-identification and semantic fusion, the system can then determine the global location of each tracked object within a larger environment.
The authors evaluate their approach on various datasets and demonstrate improved performance compared to existing single-modal methods, especially in challenging scenarios with occlusions or dramatic changes in lighting conditions.
Critical Analysis
The paper presents a promising approach for global localization using multi-modal object-instance re-identification. However, the authors acknowledge several limitations and areas for future research:
- The method relies on accurate object detection and segmentation, which can be challenging in complex real-world environments.
- The performance of the re-identification module may degrade in scenarios with significant changes in object appearance, such as extreme lighting conditions or camera viewpoints.
- The scalability of the approach to large-scale environments with a high number of objects and scenes is not extensively evaluated.
Further research could explore techniques to improve robustness and adaptability, as well as investigate the practical implications and deployment challenges for real-world applications.
Conclusion
The presented research offers a novel approach for global localization by leveraging multi-modal object-instance re-identification. This technique can enable more robust and scalable location recognition, with potential benefits for a wide range of applications, such as robotics, autonomous systems, and surveillance. While the method shows promising results, further advancements are needed to address the identified limitations and expand its practical adoption.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Towards Global Localization using Multi-Modal Object-Instance Re-Identification
Aneesh Chavan, Vaibhav Agrawal, Vineeth Bhat, Sarthak Chittawar, Siddharth Srivastava, Chetan Arora, K Madhava Krishna
Re-identification (ReID) is a critical challenge in computer vision, predominantly studied in the context of pedestrians and vehicles. However, robust object-instance ReID, which has significant implications for tasks such as autonomous exploration, long-term perception, and scene understanding, remains underexplored. In this work, we address this gap by proposing a novel dual-path object-instance re-identification transformer architecture that integrates multimodal RGB and depth information. By leveraging depth data, we demonstrate improvements in ReID across scenes that are cluttered or have varying illumination conditions. Additionally, we develop a ReID-based localization framework that enables accurate camera localization and pose identification across different viewpoints. We validate our methods using two custom-built RGB-D datasets, as well as multiple sequences from the open-source TUM RGB-D datasets. Our approach demonstrates significant improvements in both object instance ReID (mAP of 75.18) and localization accuracy (success rate of 83% on TUM-RGBD), highlighting the essential role of object ReID in advancing robotic perception. Our models, frameworks, and datasets have been made publicly available.
Read more9/19/2024

0
Object Re-identification via Spatial-temporal Fusion Networks and Causal Identity Matching
Hye-Geun Kim, Yong-Hyuk Moon, Yeong-Jun Cho
Object re-identification (ReID) in large camera networks faces numerous challenges. First, the similar appearances of objects degrade ReID performance, a challenge that needs to be addressed by existing appearance-based ReID methods. Second, most ReID studies are performed in laboratory settings and do not consider real-world scenarios. To overcome these challenges, we introduce a novel ReID framework that leverages a spatial-temporal fusion network and causal identity matching (CIM). Our framework estimates camera network topology using a proposed adaptive Parzen window and combines appearance features with spatial-temporal cues within the fusion network. This approach has demonstrated outstanding performance across several datasets, including VeRi776, Vehicle-3I, and Market-1501, achieving up to 99.70% rank-1 accuracy and 95.5% mAP. Furthermore, the proposed CIM approach, which dynamically assigns gallery sets based on camera network topology, has further improved ReID accuracy and robustness in real-world settings, evidenced by a 94.95% mAP and a 95.19% F1 score on the Vehicle-3I dataset. The experimental results support the effectiveness of incorporating spatial-temporal information and CIM for real-world ReID scenarios, regardless of the data domain (e.g., vehicle, person).
Read more8/23/2024
0
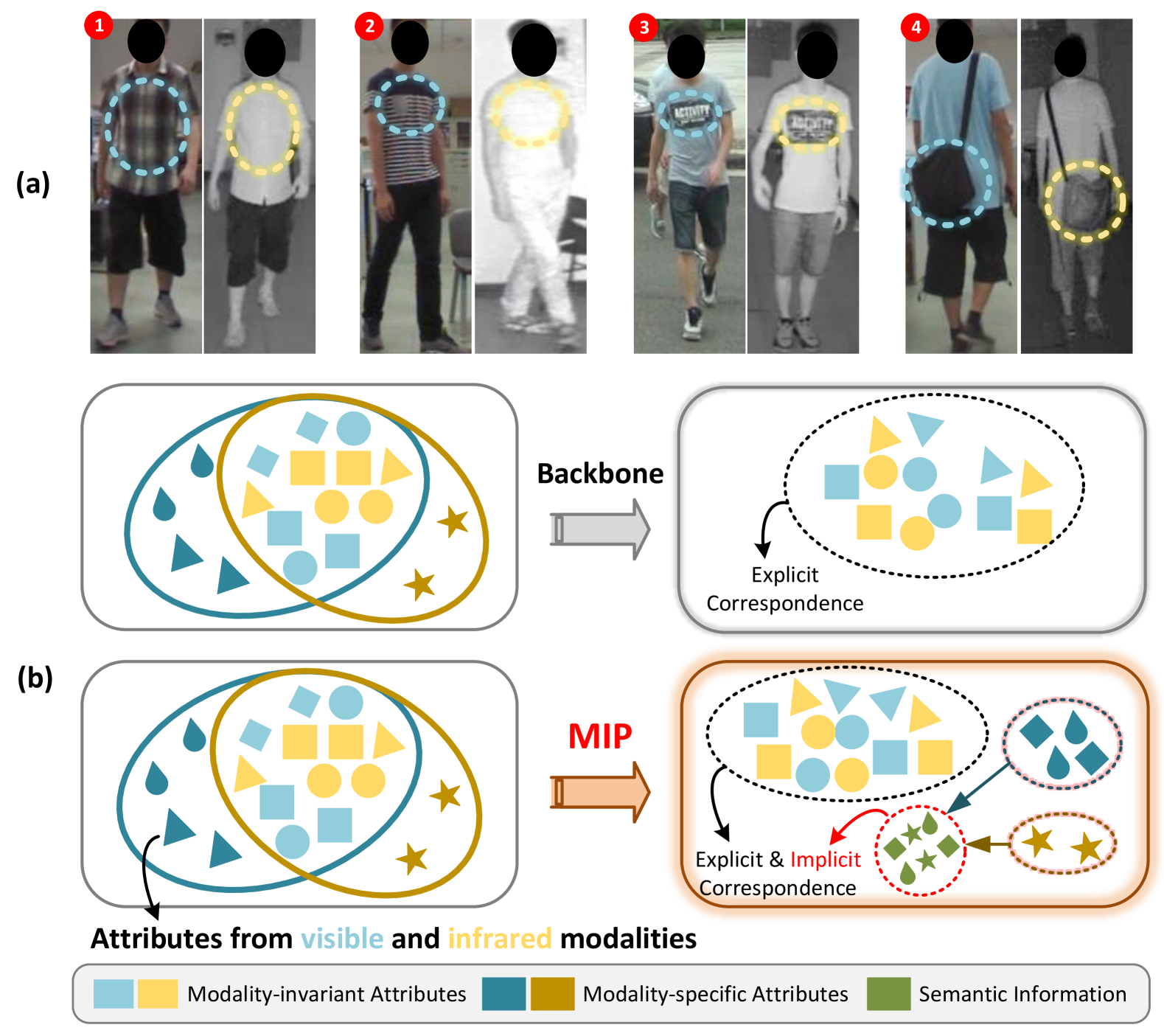
Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning
Ruiqi Wu, Bingliang Jiao, Wenxuan Wang, Meng Liu, Peng Wang
The Visible-Infrared Person Re-identification (VI ReID) aims to match visible and infrared images of the same pedestrians across non-overlapped camera views. These two input modalities contain both invariant information, such as shape, and modality-specific details, such as color. An ideal model should utilize valuable information from both modalities during training for enhanced representational capability. However, the gap caused by modality-specific information poses substantial challenges for the VI ReID model to handle distinct modality inputs simultaneously. To address this, we introduce the Modality-aware and Instance-aware Visual Prompts (MIP) network in our work, designed to effectively utilize both invariant and specific information for identification. Specifically, our MIP model is built on the transformer architecture. In this model, we have designed a series of modality-specific prompts, which could enable our model to adapt to and make use of the specific information inherent in different modality inputs, thereby reducing the interference caused by the modality gap and achieving better identification. Besides, we also employ each pedestrian feature to construct a group of instance-specific prompts. These customized prompts are responsible for guiding our model to adapt to each pedestrian instance dynamically, thereby capturing identity-level discriminative clues for identification. Through extensive experiments on SYSU-MM01 and RegDB datasets, the effectiveness of both our designed modules is evaluated. Additionally, our proposed MIP performs better than most state-of-the-art methods.
Read more6/19/2024

0
Optimizing ROI Benefits Vehicle ReID in ITS
Mei Qiu, Lauren Ann Christopher, Lingxi Li, Stanley Chien, Yaobin Chen
Vehicle re-identification (ReID) is a computer vision task that matches the same vehicle across different cameras or viewpoints in a surveillance system. This is crucial for Intelligent Transportation Systems (ITS), where the effectiveness is influenced by the regions from which vehicle images are cropped. This study explores whether optimal vehicle detection regions, guided by detection confidence scores, can enhance feature matching and ReID tasks. Using our framework with multiple Regions of Interest (ROIs) and lane-wise vehicle counts, we employed YOLOv8 for detection and DeepSORT for tracking across twelve Indiana Highway videos, including two pairs of videos from non-overlapping cameras. Tracked vehicle images were cropped from inside and outside the ROIs at five-frame intervals. Features were extracted using pre-trained models: ResNet50, ResNeXt50, Vision Transformer, and Swin-Transformer. Feature consistency was assessed through cosine similarity, information entropy, and clustering variance. Results showed that features from images cropped inside ROIs had higher mean cosine similarity values compared to those involving one image inside and one outside the ROIs. The most significant difference was observed during night conditions (0.7842 inside vs. 0.5 outside the ROI with Swin-Transformer) and in cross-camera scenarios (0.75 inside-inside vs. 0.52 inside-outside the ROI with Vision Transformer). Information entropy and clustering variance further supported that features in ROIs are more consistent. These findings suggest that strategically selected ROIs can enhance tracking performance and ReID accuracy in ITS.
Read more7/16/2024