Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference
2403.20306
0
0
Abstract
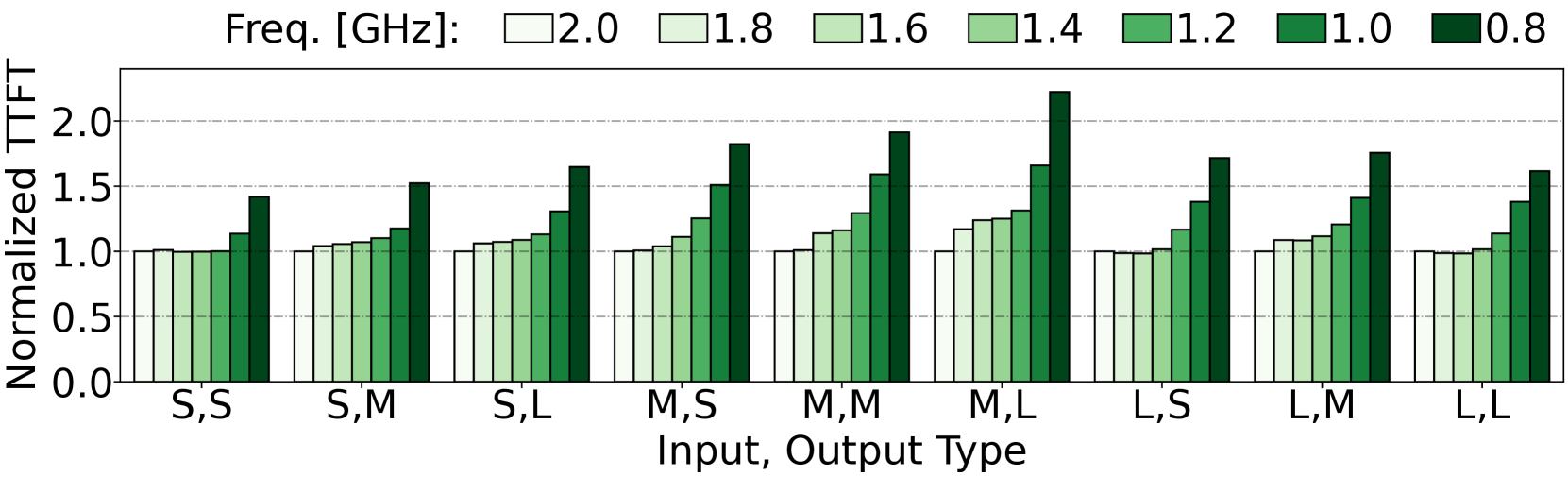
With the ubiquitous use of modern large language models (LLMs) across industries, the inference serving for these models is ever expanding. Given the high compute and memory requirements of modern LLMs, more and more top-of-the-line GPUs are being deployed to serve these models. Energy availability has come to the forefront as the biggest challenge for data center expansion to serve these models. In this paper, we present the trade-offs brought up by making energy efficiency the primary goal of LLM serving under performance SLOs. We show that depending on the inputs, the model, and the service-level agreements, there are several knobs available to the LLM inference provider to use for being energy efficient. We characterize the impact of these knobs on the latency, throughput, as well as the energy. By exploring these trade-offs, we offer valuable insights into optimizing energy usage without compromising on performance, thereby paving the way for sustainable and cost-effective LLM deployment in data center environments.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores methods to improve the energy efficiency of large language models (LLMs) during the inference stage.
- It proposes techniques to reduce the computational and energy requirements of running LLMs, which can have a significant environmental impact.
- The research aims to bring energy efficiency to the forefront of LLM development and deployment.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a wide range of natural language tasks, such as generating human-like text, answering questions, and summarizing information. However, running these complex models requires a lot of computing power and energy, which can have a substantial environmental impact.
The researchers in this paper recognized this issue and set out to find ways to make LLMs more energy-efficient. They explored various techniques that could reduce the computational and energy requirements of running LLMs during the inference stage, when the model is used to generate outputs.
By making LLMs more energy-efficient, the researchers hope to make their use more sustainable and environmentally friendly. This could have far-reaching implications, as LLMs are becoming increasingly prevalent in a variety of applications, from chatbots and virtual assistants to content generation and language translation.
Technical Explanation
The paper begins by highlighting the growing importance of LLMs and the significant computing and energy resources required to run them, particularly during the inference stage. The authors then review various approaches to improving the energy efficiency of LLMs, such as model compression, quantization, and hardware acceleration.
The researchers propose a multi-pronged approach that combines several techniques to optimize the energy efficiency of LLM inference. This includes:
-
Architectural Innovations: The authors explore modifications to the LLM architecture, such as introducing custom attention mechanisms and layer-wise adaptations, to reduce the computational complexity and energy consumption.
-
Hardware-Software Co-design: The paper investigates the synergistic optimization of LLM models and the underlying hardware, leveraging techniques like dynamic voltage and frequency scaling (DVFS) and hardware accelerators.
-
Benchmarking and Evaluation: The researchers develop comprehensive benchmarking suites and evaluation methodologies to assess the energy efficiency of LLMs across a range of tasks and deployment scenarios.
Through a series of experiments and case studies, the authors demonstrate the effectiveness of their proposed techniques in improving the energy efficiency of LLM inference without significantly compromising the model's performance.
Critical Analysis
The paper presents a well-designed and thorough investigation into improving the energy efficiency of LLMs. The researchers have thoughtfully considered various aspects of the problem, including architectural innovations, hardware-software co-design, and comprehensive evaluation methods.
One potential limitation of the study is that it primarily focuses on the inference stage of LLM deployment, while the training stage, which can also have a significant energy footprint, is not explicitly addressed. Future research could explore techniques to enhance the energy efficiency of the entire LLM lifecycle, from training to deployment.
Additionally, the authors acknowledge that their proposed methods may not be universally applicable, as the optimal energy-efficiency strategies may depend on the specific LLM architecture, deployment scenario, and hardware constraints. Further research is needed to understand the broader applicability and generalizability of the techniques presented in this paper.
Overall, this research represents an important step towards making LLMs more sustainable and environmentally friendly, which is a crucial consideration as these models become increasingly ubiquitous in various applications.
Conclusion
The paper introduces innovative approaches to improving the energy efficiency of large language models (LLMs) during the inference stage. By exploring architectural innovations, hardware-software co-design, and comprehensive evaluation methods, the researchers have demonstrated effective techniques to reduce the computational and energy requirements of running LLMs without significantly compromising their performance.
This work is particularly timely and significant, as the widespread adoption of LLMs across various industries and applications has raised concerns about their environmental impact. By bringing energy efficiency to the forefront of LLM development and deployment, the researchers are paving the way for more sustainable and environmentally friendly AI systems.
The insights and methodologies presented in this paper have the potential to influence the future design and deployment of LLMs, ultimately contributing to a more energy-efficient and eco-friendly landscape for natural language processing and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Toward Cross-Layer Energy Optimizations in Machine Learning Systems
Jae-Won Chung, Mosharaf Chowdhury
0
0
The enormous energy consumption of machine learning (ML) and generative AI workloads shows no sign of waning, taking a toll on operating costs, power delivery, and environmental sustainability. Despite a long line of research on energy-efficient hardware, we found that software plays a critical role in ML energy optimization through two recent works: Zeus and Perseus. This is especially true for large language models (LLMs) because their model sizes and, therefore, energy demands are growing faster than hardware efficiency improvements. Therefore, we advocate for a cross-layer approach for energy optimizations in ML systems, where hardware provides architectural support that pushes energy-efficient software further, while software leverages and abstracts the hardware to develop techniques that bring hardware-agnostic energy-efficiency gains.
4/11/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
4/23/2024
💬
Planning with Language Models Through The Lens of Efficiency
Michael Katz, Harsha Kokel, Kavitha Srinivas, Shirin Sohrabi
0
0
We analyse the cost of using LLMs for planning and highlight that recent trends are profoundly uneconomical. We propose a significantly more efficient approach and argue for a responsible use of compute resources; urging research community to investigate LLM-based approaches that upholds efficiency.
4/19/2024
🛠️
Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Xinyuan Zhang, Jiang Liu, Zehui Xiong, Yudong Huang, Gaochang Xie, Ran Zhang
0
0
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
5/14/2024