Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
2405.07140
0
0
🛠️
Abstract
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
Create account to get full access
Overview
- Large Language Models (LLMs) are at the forefront of Generative Artificial Intelligence (GAI), enabling unprecedented content creation abilities.
- However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations.
- Edge intelligence has been used to address these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources.
- Most research has focused on traditional AI models, leaving a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms.
Plain English Explanation
The paper discusses a new approach to using edge intelligence to optimize the performance of Large Language Models (LLMs) on resource-constrained edge devices. LLMs are a type of Generative Artificial Intelligence (GAI) that can create highly impressive content, but they require a lot of computing power, often relying on cloud-based servers. This can be problematic, as it can lead to privacy concerns, high latency, and limitations on usage.
The researchers in this paper have developed a way to run LLM inference (the process of using the model to generate content) on edge devices, such as smartphones or IoT sensors, which are located close to the data sources. This helps to address the issues with cloud-based hosting by enabling real-time AI computation and keeping the data local.
However, the unique characteristics of LLMs, such as their large model size and complex mechanisms like auto-regression and self-attention, have made it challenging to adapt existing edge intelligence solutions. The paper presents a new optimization problem and algorithm specifically tailored for LLM inference on edge devices.
Technical Explanation
The key elements of the paper are:
-
Inference Model for Transformer Decoder-based LLMs: The researchers have formulated an inference model for transformer decoder-based LLMs, which are a common type of LLM architecture. This model takes into account the unique characteristics of LLMs, such as their considerable model size and auto-regressive processes.
-
Optimization Problem: The researchers have defined an optimization problem that aims to maximize the inference throughput of LLMs on edge devices. This involves batch scheduling and the joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements for latency and accuracy.
-
Optimal Depth-First Tree-Searching Algorithm with Online Tree-Pruning (DFTSP): To address the NP-hard optimization problem, the researchers have developed an algorithm called DFTSP. This algorithm uses a depth-first tree search with online pruning to find the optimal solution within a feasible time complexity.
-
Evaluation: The researchers have simulated the performance of their DFTSP algorithm and compared it to other batching benchmarks. The results show that DFTSP outperforms the benchmarks in terms of throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
Critical Analysis
The paper presents a novel and promising approach to optimizing LLM inference on edge devices, which could help address some of the key challenges associated with cloud-based hosting of these models. However, there are a few potential limitations and areas for further research:
-
Model Diversity: The paper focuses on transformer decoder-based LLMs, but there are other types of LLM architectures (e.g., GPT-3, BERT) that may have different characteristics and requirements. It would be valuable to investigate how the proposed approach could be adapted to handle a broader range of LLM models.
-
Real-World Deployment: The evaluation in the paper is based on simulations, and it would be important to validate the performance of the DFTSP algorithm in real-world edge deployments, where factors like network latency, device heterogeneity, and dynamic workloads may introduce additional challenges.
-
Scalability and Generalizability: As the size and complexity of LLMs continue to grow, it will be crucial to ensure that the optimization approach can scale effectively and remain generalizable to future advancements in the field.
-
Benchmarking and Standardization: The paper mentions the use of a custom benchmarking suite, but it would be valuable to see the proposed approach evaluated against a more widely-accepted LLM benchmarking framework to facilitate broader comparisons and adoption.
Conclusion
This paper presents an innovative approach to optimizing LLM inference on resource-constrained edge devices, which could help address the challenges of cloud-based hosting and unlock the potential of FPGA-based spatial acceleration for LLMs. The proposed optimization problem and DFTSP algorithm show promising results in terms of throughput and time complexity, but further research is needed to validate the approach in real-world scenarios and ensure its scalability and generalizability as LLM technology continues to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SqueezeLLM: Dense-and-Sparse Quantization
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer
0
0
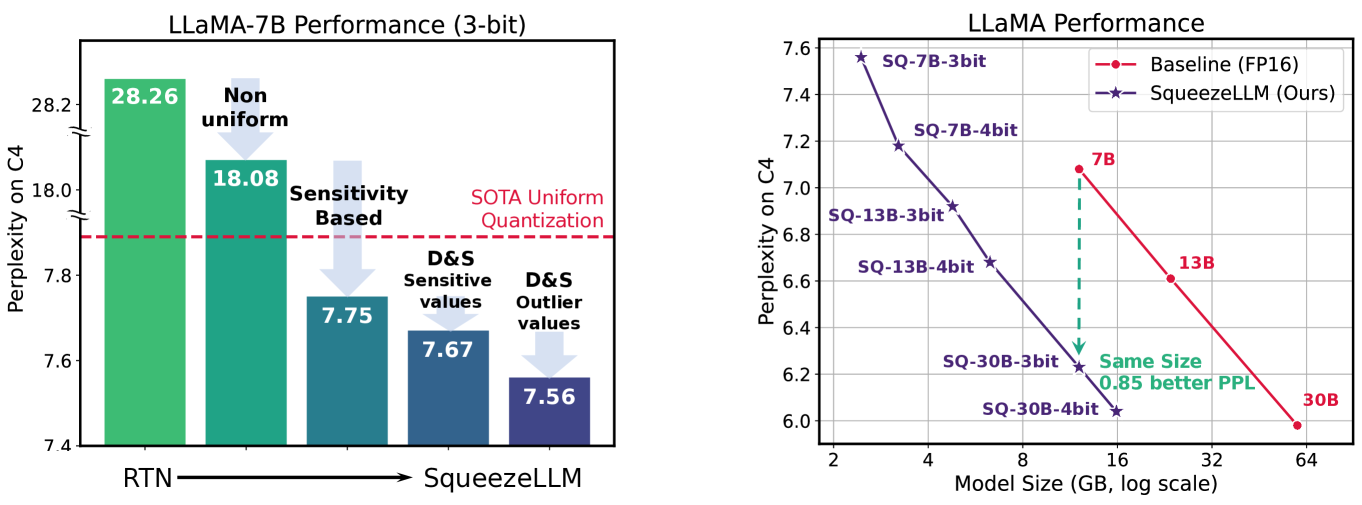
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is available at https://github.com/SqueezeAILab/SqueezeLLM.
6/6/2024
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting
Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin
0
0
Efficient adaption of large language models (LLMs) on edge devices is essential for applications requiring continuous and privacy-preserving adaptation and inference. However, existing tuning techniques fall short because of the high computation and memory overheads. To this end, we introduce a computation- and memory-efficient LLM tuning framework, called Edge-LLM, to facilitate affordable and effective LLM adaptation on edge devices. Specifically, Edge-LLM features three core components: (1) a layer-wise unified compression (LUC) technique to reduce the computation overhead by generating layer-wise pruning sparsity and quantization bit-width policies, (2) an adaptive layer tuning and voting scheme to reduce the memory overhead by reducing the backpropagation depth, and (3) a complementary hardware scheduling strategy to handle the irregular computation patterns introduced by LUC and adaptive layer tuning, thereby achieving efficient computation and data movements. Extensive experiments demonstrate that Edge-LLM achieves a 2.92x speed up and a 4x memory overhead reduction as compared to vanilla tuning methods with comparable task accuracy. Our code is available at https://github.com/GATECH-EIC/Edge-LLM
6/26/2024

ApiQ: Finetuning of 2-Bit Quantized Large Language Model
Baohao Liao, Christian Herold, Shahram Khadivi, Christof Monz
0
0
Memory-efficient finetuning of large language models (LLMs) has recently attracted huge attention with the increasing size of LLMs, primarily due to the constraints posed by GPU memory limitations and the effectiveness of these methods compared to full finetuning. Despite the advancements, current strategies for memory-efficient finetuning, such as QLoRA, exhibit inconsistent performance across diverse bit-width quantizations and multifaceted tasks. This inconsistency largely stems from the detrimental impact of the quantization process on preserved knowledge, leading to catastrophic forgetting and undermining the utilization of pretrained models for finetuning purposes. In this work, we introduce a novel quantization framework, ApiQ, designed to restore the lost information from quantization by concurrently initializing the LoRA components and quantizing the weights of LLMs. This approach ensures the maintenance of the original LLM's activation precision while mitigating the error propagation from shallower into deeper layers. Through comprehensive evaluations conducted on a spectrum of language tasks with various LLMs, ApiQ demonstrably minimizes activation error during quantization. Consequently, it consistently achieves superior finetuning results across various bit-widths.
6/24/2024
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024