Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
2404.16164
0
0
🧠
Abstract
Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
Create account to get full access
Overview
- Large language models (LLMs) have shown impressive performance on various natural language processing (NLP) tasks, leading to their rapid adoption in diverse applications.
- Evaluating the factuality of LLMs' generated outputs is crucial, as hallucinations remain a challenging issue.
- This research focuses on assessing LLMs' ability to recall factual knowledge learned during pretraining and the factors that affect this ability.
Plain English Explanation
Large language models (LLMs) are AI systems that have been trained on massive amounts of text data, allowing them to understand and generate human-like language. These models have shown impressive performance on a variety of language-related tasks, which has led to their widespread adoption in different applications.
However, one of the key challenges with LLMs is that they can sometimes generate outputs that are not entirely factual or accurate, a phenomenon known as hallucinations. This means that the model may confidently produce information that is not grounded in reality, which can be problematic in applications where factual accuracy is crucial.
To address this issue, the researchers in this study focused on evaluating how well LLMs are able to recall the factual knowledge they have learned during their pretraining process, which is the initial training phase where the model is exposed to a large amount of text data. They wanted to understand what factors might affect the model's ability to recall this factual knowledge.
The researchers created a comprehensive benchmark called FACT-BENCH that covers a wide range of knowledge domains, property types, and different levels of knowledge popularity. They then tested 31 different LLMs from 10 model families to get a holistic understanding of their strengths and weaknesses when it comes to recalling factual knowledge.
Technical Explanation
The researchers constructed FACT-BENCH, a representative benchmark that covers 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. They used this benchmark to evaluate 31 models from 10 different model families, providing a comprehensive assessment of their factual knowledge recall capabilities.
The key findings from their experiments include:
-
Instruction-tuning hurts knowledge recall: Pretraining-only models consistently outperformed their instruction-tuned counterparts, suggesting that the fine-tuning process can negatively impact a model's ability to recall factual knowledge.
-
Positive effects of model scaling: Larger models within each family outperformed their smaller counterparts, indicating that increasing model size can improve factual knowledge recall.
-
Significant gap with the upper-bound: Even the best-performing model, GPT-4, still exhibited a large gap compared to the upper-bound in terms of factual knowledge recall.
-
Negative impact of in-context exemplars: The researchers used counterfactual demonstrations to study the role of in-context exemplars, finding that they can lead to significant degradation of factual knowledge recall, especially for larger models.
-
Degradation attributed to contradictory exemplars: By decoupling known and unknown knowledge, the researchers found that the degradation in factual knowledge recall is attributed to exemplars that contradict the model's known knowledge, as well as the number of such exemplars.
-
Fine-tuning on known knowledge is beneficial: The researchers fine-tuned the LLaMA-7B model in different settings, and found that fine-tuning on a model's known knowledge consistently outperformed fine-tuning on unknown or mixed knowledge.
Critical Analysis
The researchers have provided a comprehensive and rigorous evaluation of LLMs' factual knowledge recall capabilities, which is an important area of research given the widespread adoption of these models and the issue of hallucinations.
One potential limitation of this study is that it focuses solely on factual knowledge recall, and does not address other important aspects of LLM performance, such as their ability to reason, generate coherent and contextually appropriate text, or handle more complex language tasks. Additionally, the benchmark used in this study, FACT-BENCH, may not capture the full breadth of factual knowledge that LLMs are expected to possess, and may be biased towards certain types of knowledge.
Another area for further research could be exploring the reasons behind the negative impact of instruction-tuning on factual knowledge recall. The authors suggest that this may be due to the model's focus on task-specific objectives during the fine-tuning process, but a deeper understanding of this phenomenon could help inform the development of more effective training strategies.
Additionally, the researchers' findings on the role of in-context exemplars and their impact on factual knowledge recall raise interesting questions about the cognitive processes involved in language models' reasoning and decision-making. Further investigations into these mechanisms could provide valuable insights into the inner workings of LLMs and help address the challenge of hallucinations.
Conclusion
This study provides a comprehensive evaluation of LLMs' factual knowledge recall capabilities, using the FACT-BENCH benchmark to assess 31 models from 10 different families. The key findings include the negative impact of instruction-tuning, the positive effects of model scaling, and the detrimental influence of contradictory in-context exemplars on factual knowledge recall.
These insights have important implications for the development and deployment of LLMs, as they highlight the need to carefully consider the factors that affect a model's ability to recall and utilize factual information, especially in applications where accuracy and reliability are critical. The researchers' work also underscores the importance of continued research and innovation in this area to address the challenge of hallucinations and ensure the alignment of LLMs with real-world knowledge and user needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, Helen Meng
0
0
Despite showing increasingly human-like abilities, large language models (LLMs) often struggle with factual inaccuracies, i.e. hallucinations, even when they hold relevant knowledge. To address these hallucinations, current approaches typically necessitate high-quality human factuality annotations. In this work, we explore Self-Alignment for Factuality, where we leverage the self-evaluation capability of an LLM to provide training signals that steer the model towards factuality. Specifically, we incorporate Self-Eval, a self-evaluation component, to prompt an LLM to validate the factuality of its own generated responses solely based on its internal knowledge. Additionally, we design Self-Knowledge Tuning (SK-Tuning) to augment the LLM's self-evaluation ability by improving the model's confidence estimation and calibration. We then utilize these self-annotated responses to fine-tune the model via Direct Preference Optimization algorithm. We show that the proposed self-alignment approach substantially enhances factual accuracy over Llama family models across three key knowledge-intensive tasks on TruthfulQA and BioGEN.
6/12/2024
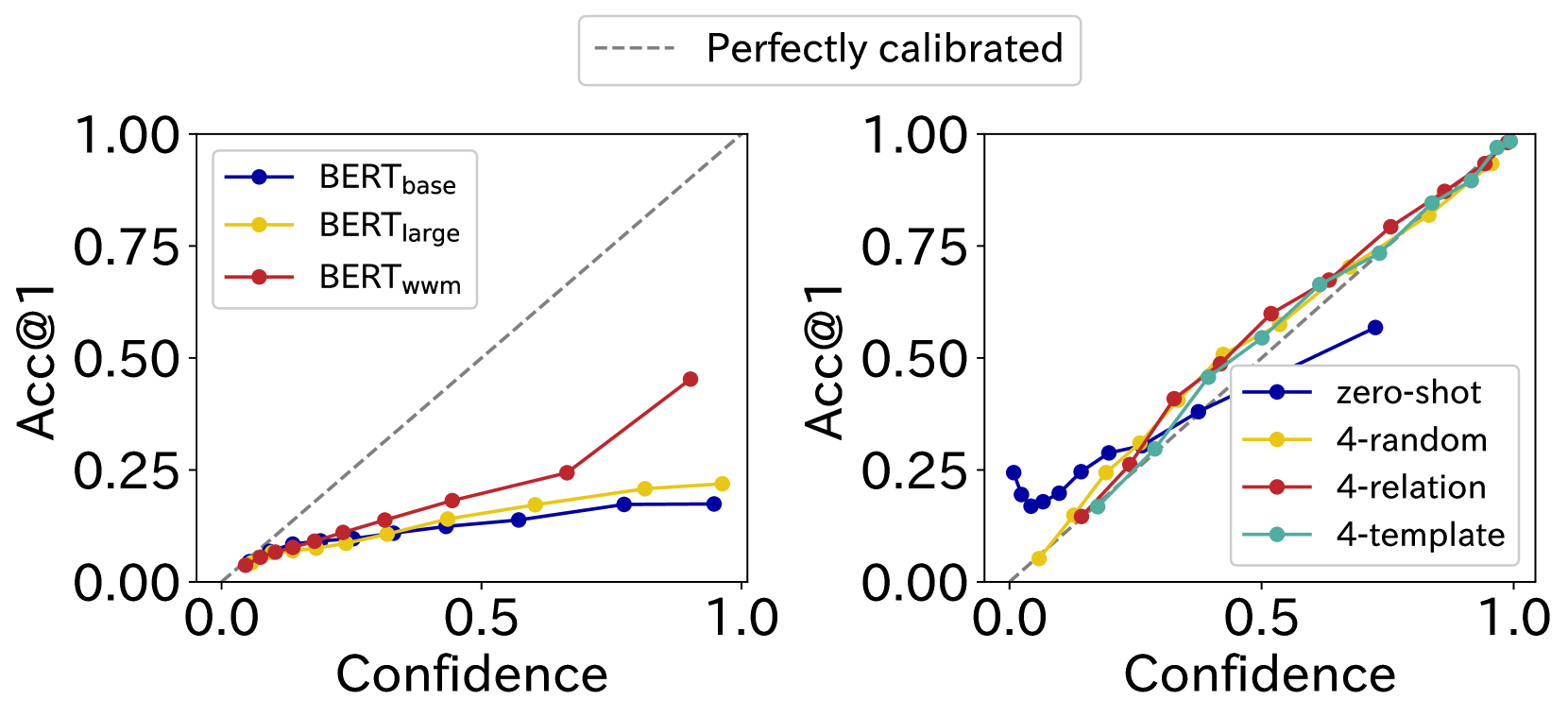
What Matters in Learning Facts in Language Models? Multifaceted Knowledge Probing with Diverse Multi-Prompt Datasets
Xin Zhao, Naoki Yoshinaga, Daisuke Oba
0
0
Large language models (LLMs) face issues in handling factual knowledge, making it vital to evaluate their true ability to understand facts. In this study, we introduce knowledge probing frameworks, BELIEF(-ICL), to evaluate the knowledge understanding ability of not only encoder-based PLMs but also decoder-based PLMs from diverse perspectives. BELIEFs utilize a multi-prompt dataset to evaluate PLM's accuracy, consistency, and reliability in factual knowledge understanding. To provide a more reliable evaluation with BELIEFs, we semi-automatically create MyriadLAMA, which has more diverse prompts than existing datasets. We validate the effectiveness of BELIEFs in correctly and comprehensively evaluating PLM's factual understanding ability through extensive evaluations. We further investigate key factors in learning facts in LLMs, and reveal the limitation of the prompt-based knowledge probing. The dataset is anonymously publicized.
6/19/2024
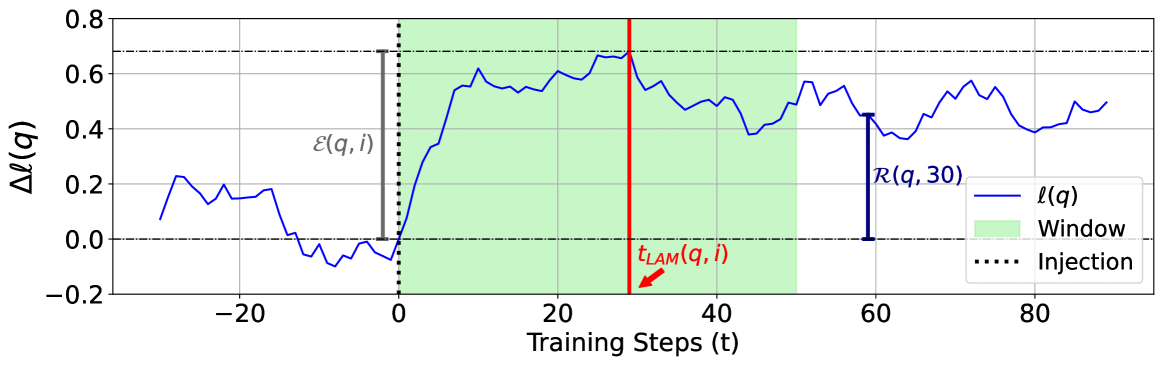
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
Hoyeon Chang, Jinho Park, Seonghyeon Ye, Sohee Yang, Youngkyung Seo, Du-Seong Chang, Minjoon Seo
0
0
Despite the recent observation that large language models (LLMs) can store substantial factual knowledge, there is a limited understanding of the mechanisms of how they acquire factual knowledge through pretraining. This work addresses this gap by studying how LLMs acquire factual knowledge during pretraining. The findings reveal several important insights into the dynamics of factual knowledge acquisition during pretraining. First, counterintuitively, we observe that pretraining on more data shows no significant improvement in the model's capability to acquire and maintain factual knowledge. Next, there is a power-law relationship between training steps and forgetting of memorization and generalization of factual knowledge, and LLMs trained with duplicated training data exhibit faster forgetting. Third, training LLMs with larger batch sizes can enhance the models' robustness to forgetting. Overall, our observations suggest that factual knowledge acquisition in LLM pretraining occurs by progressively increasing the probability of factual knowledge presented in the pretraining data at each step. However, this increase is diluted by subsequent forgetting. Based on this interpretation, we demonstrate that we can provide plausible explanations for recently observed behaviors of LLMs, such as the poor performance of LLMs on long-tail knowledge and the benefits of deduplicating the pretraining corpus.
6/18/2024

Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Mat'eo Mahaut, Laura Aina, Paula Czarnowska, Momchil Hardalov, Thomas Muller, Llu'is M`arquez
0
0
Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
6/21/2024