Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
2406.13415
0
0

Abstract
Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
Create account to get full access
Overview
- This paper explores the reliability and robustness of current estimators for "factual confidence" in large language models (LLMs).
- Factual confidence refers to an LLM's ability to accurately assess its own knowledge and uncertainty about factual information.
- The paper examines various methods for measuring factual confidence and identifies limitations in their ability to provide reliable and robust estimates.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models don't always know the limits of their own knowledge. Factual confidence refers to an LLM's ability to accurately assess how certain it is about the factual information it provides.
This paper looks at different ways researchers have tried to measure an LLM's factual confidence. The authors find that current methods have limitations and may not always provide reliable or robust estimates. For example, some methods may work well in certain situations but fail in others, or they may be sensitive to small changes in the input.
The paper is important because it highlights the challenges in building LLMs that can accurately communicate the extent of their knowledge and uncertainty. This is crucial for ensuring these models can be used safely and reliably, especially in applications where their outputs could have significant real-world consequences.
Technical Explanation
The paper examines the reliability and robustness of current estimators for "factual confidence" in large language models (LLMs). Factual confidence refers to an LLM's ability to accurately assess its own knowledge and uncertainty about factual information.
The authors review several existing methods for measuring factual confidence, including confidence estimation via black-box probing, knowledge-grounded confidence estimation, and confidence estimation from a grouping loss perspective. They evaluate these methods on their ability to provide reliable and robust estimates of factual confidence.
The results show that current estimators have limitations in their ability to accurately capture an LLM's factual confidence. The authors find that the methods can be sensitive to factors like the specific task or input, and may not generalize well to different settings. They also identify issues with the metrics used to assess factual confidence, which may not fully capture the complex nature of an LLM's knowledge and uncertainty.
Critical Analysis
The paper provides a valuable critique of the current state of factual confidence estimation in large language models. The authors' findings highlight the challenges in building LLMs that can reliably communicate the extent of their knowledge and uncertainty.
One limitation of the paper is that it does not offer a definitive solution to the problem. The authors acknowledge the need for further research to develop more robust and reliable methods for measuring factual confidence. Additionally, the paper focuses primarily on technical aspects of the problem and does not delve deeply into the broader implications for the use of LLMs in real-world applications.
It would be interesting to see the authors explore the societal and ethical considerations around the accurate communication of LLM capabilities and limitations. For example, how might unreliable factual confidence estimates impact the use of these models in decision-making processes, and what are the potential risks and consequences?
Conclusion
This paper offers a critical analysis of the reliability and robustness of current estimators for factual confidence in large language models. The authors identify significant limitations in existing methods, underscoring the need for continued research in this area.
Accurate and reliable factual confidence estimation is crucial for the safe and responsible deployment of LLMs, as it enables these models to communicate the extent of their knowledge and uncertainty. The findings in this paper highlight the importance of developing more robust and generalizable approaches to this problem, which could have important implications for the future of AI systems and their real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
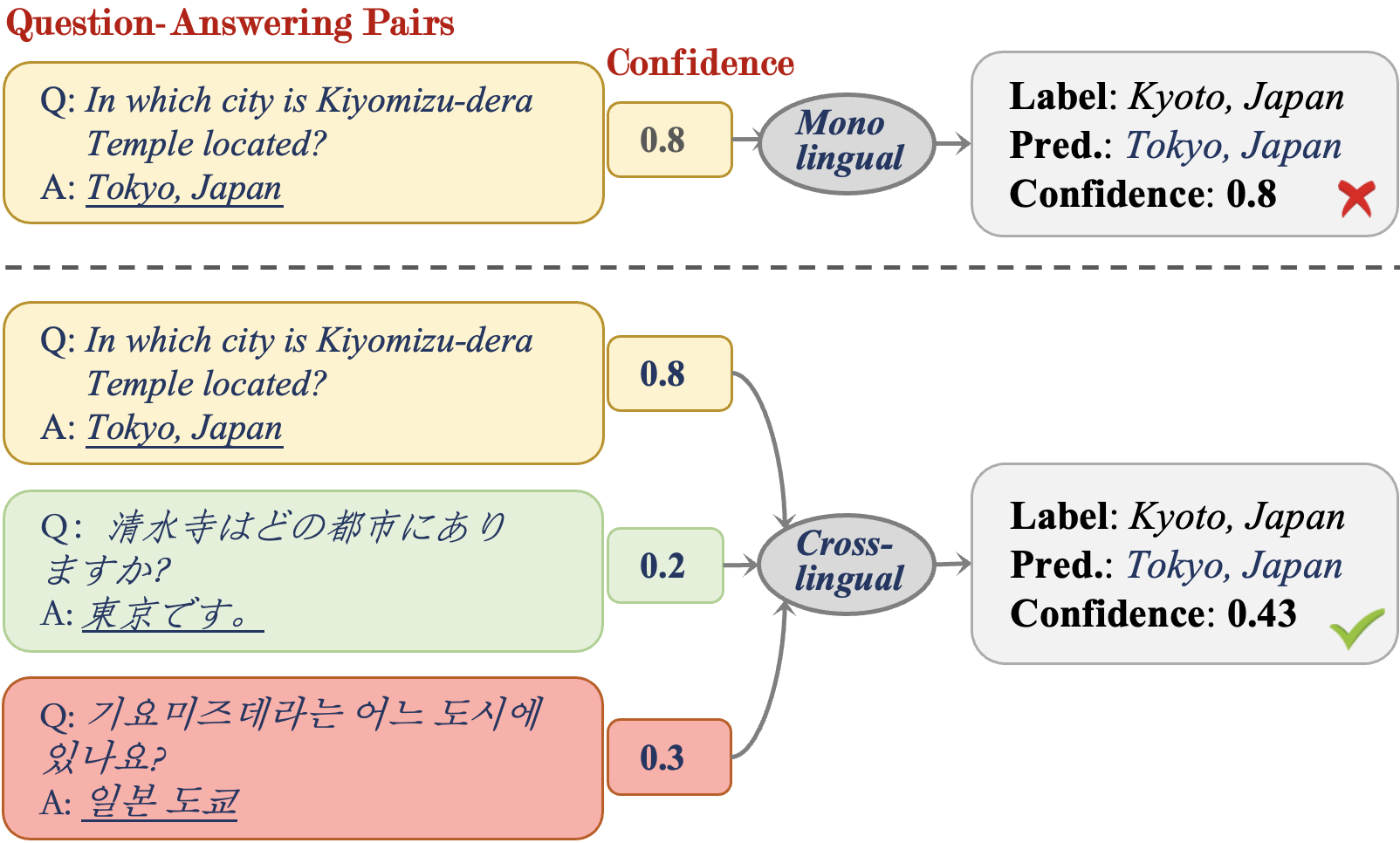
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024
🧠
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Jiaqing Yuan, Lin Pan, Chung-Wei Hang, Jiang Guo, Jiarong Jiang, Bonan Min, Patrick Ng, Zhiguo Wang
0
0
Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
4/26/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
0
0
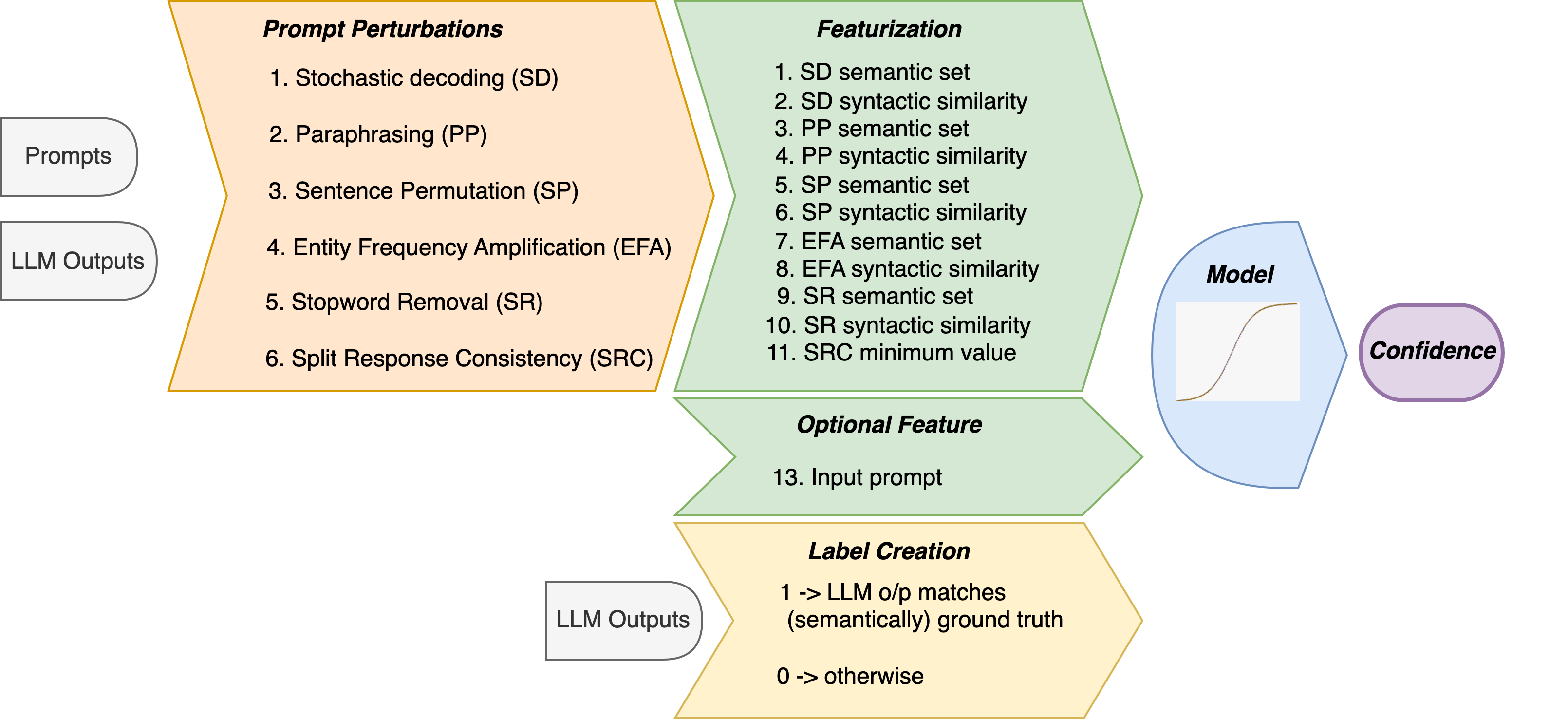
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
6/10/2024