Towards Imperceptible Backdoor Attack in Self-supervised Learning

0
🌀
Sign in to get full access
Overview
- Self-supervised learning models are vulnerable to backdoor attacks
- Existing backdoor attacks often use noticeable triggers that are easy to detect
- This paper proposes a new attack using imperceptible triggers that are effective against self-supervised models
Plain English Explanation
This research paper explores a new way to secretly "hack" self-supervised machine learning models. Self-supervised learning is a powerful technique where models learn patterns from large amounts of unlabeled data. However, the paper shows that these self-supervised models can be vulnerable to a type of attack called a "backdoor attack."
Backdoor attacks work by injecting hidden, malicious triggers into the training data. When the model is later exposed to data containing those triggers, it will produce incorrect, malicious outputs. Existing backdoor attacks often use obvious visual triggers, like colored patches, that are easy for humans to spot.
The key innovation in this paper is designing imperceptible, or "invisible," triggers that can still effectively compromise self-supervised models. The researchers found that existing invisible triggers don't work as well for self-supervised learning, because the way self-supervised models process data makes it harder to hide the triggers.
Building on this insight, the researchers developed a new type of invisible trigger that is "disentangled" from the normal data transformations used in self-supervised learning. This allows the triggers to remain undetectable to both the model and to human eyes.
Extensive experiments showed this new "IMPERATIVE" attack is highly effective at infiltrating a wide range of self-supervised models, while remaining stealthy. It also resists many existing defenses against backdoor attacks. This research highlights the importance of securing self-supervised models, which are becoming increasingly important across many AI applications.
Technical Explanation
The paper first observes that existing imperceptible backdoor triggers designed for supervised learning are not as effective at compromising self-supervised models. This is because self-supervised training involves applying various data augmentation techniques, like flipping or rotating images, to the training data.
The researchers found that the distribution overlap between these augmented samples and the backdoor samples weakens the effectiveness of the backdoor attack. To address this, they designed a new attack called "IMPERATIVE" that uses triggers optimized to be "disentangled" from the self-supervised data augmentations.
This disentanglement allows the triggers to remain imperceptible to both the model and to human inspection, while still causing the model to produce incorrect, malicious outputs when the triggers are present. The paper evaluates IMPERATIVE across five datasets and seven self-supervised learning algorithms, demonstrating its high effectiveness and stealthiness.
The researchers also show that IMPERATIVE has strong resistance against existing backdoor defense techniques. This work highlights the importance of securing self-supervised models, which are becoming increasingly prevalent in real-world AI systems.
Critical Analysis
The paper provides a thorough evaluation of the IMPERATIVE attack, testing it across a wide range of self-supervised learning setups. However, the authors acknowledge that their attack still has some limitations. For example, the triggers need to be carefully optimized for each target self-supervised model, which could be time-consuming in practice.
Additionally, while IMPERATIVE is resistant to some existing backdoor defenses, the authors note that more advanced detection techniques, like those proposed in "EMInspector", may still be able to identify their attack. Ongoing research in this area will likely lead to an "arms race" between attackers and defenders.
It's also worth considering the broader implications of this type of backdoor attack. While the paper focuses on the technical details, the ability to surreptitiously compromise self-supervised models could enable a wide range of malicious applications, from spreading misinformation to enabling targeted attacks on object detection systems.
Responsible AI development will require continued research into securing self-supervised learning against such threats, as well as careful consideration of the societal impacts of these technologies.
Conclusion
This paper presents a novel, imperceptible backdoor attack that can effectively compromise a wide range of self-supervised learning models. By designing triggers that are "disentangled" from the data augmentations used in self-supervised training, the researchers were able to create stealthy backdoors that are resistant to existing detection methods.
The findings highlight the importance of securing self-supervised models, which are becoming increasingly prevalent across many AI applications. As self-supervised learning continues to advance, further research will be needed to develop robust defenses against evolving backdoor attacks, as well as to understand the broader societal implications of these vulnerabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Towards Imperceptible Backdoor Attack in Self-supervised Learning
Hanrong Zhang, Zhenting Wang, Tingxu Han, Mingyu Jin, Chenlu Zhan, Mengnan Du, Hongwei Wang, Shiqing Ma
Self-supervised learning models are vulnerable to backdoor attacks. Existing backdoor attacks that are effective in self-supervised learning often involve noticeable triggers, like colored patches, which are vulnerable to human inspection. In this paper, we propose an imperceptible and effective backdoor attack against self-supervised models. We first find that existing imperceptible triggers designed for supervised learning are not as effective in compromising self-supervised models. We then identify this ineffectiveness is attributed to the overlap in distributions between the backdoor and augmented samples used in self-supervised learning. Building on this insight, we design an attack using optimized triggers that are disentangled to the augmented transformation in the self-supervised learning, while also remaining imperceptible to human vision. Experiments on five datasets and seven SSL algorithms demonstrate our attack is highly effective and stealthy. It also has strong resistance to existing backdoor defenses. Our code can be found at https://github.com/Zhang-Henry/IMPERATIVE.
Read more5/24/2024
0
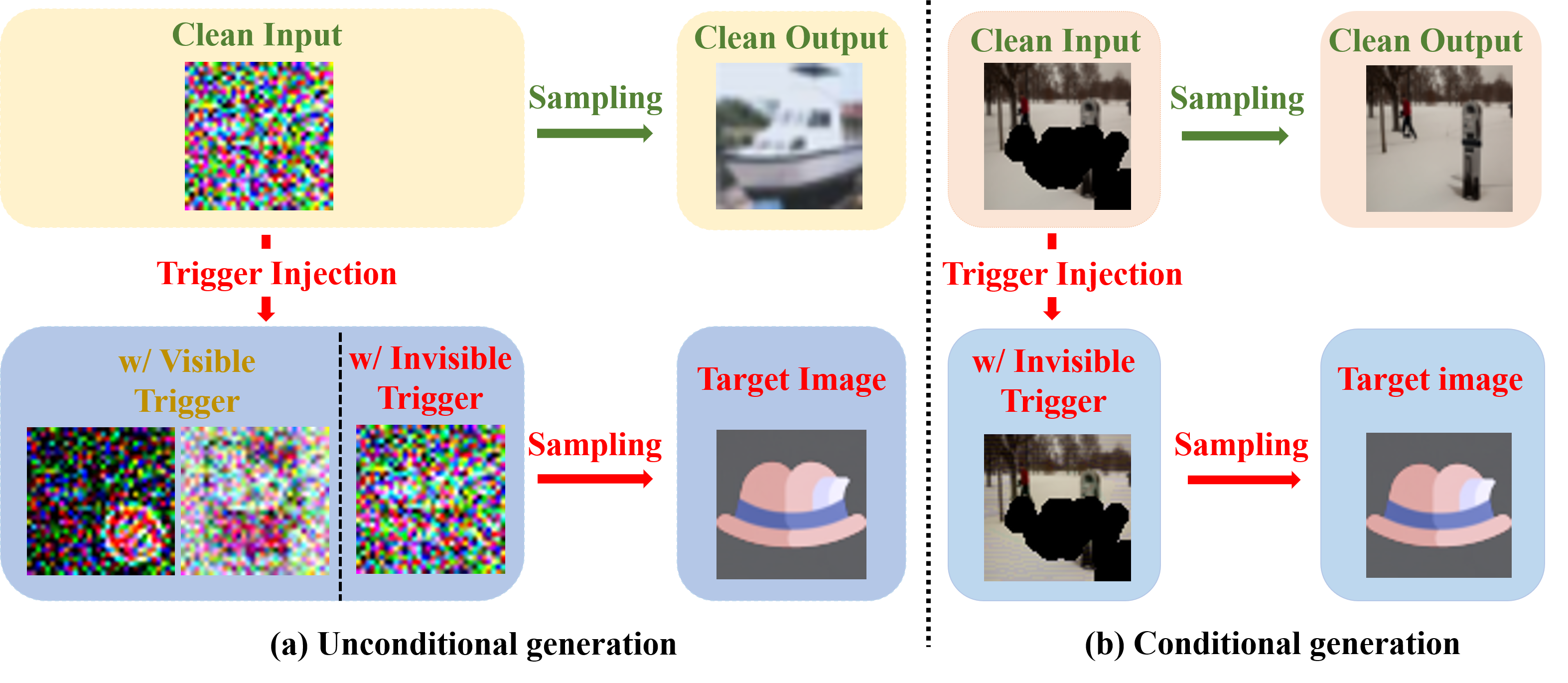
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
Read more6/4/2024

0
An Invisible Backdoor Attack Based On Semantic Feature
Yangming Chen
Backdoor attacks have severely threatened deep neural network (DNN) models in the past several years. These attacks can occur in almost every stage of the deep learning pipeline. Although the attacked model behaves normally on benign samples, it makes wrong predictions for samples containing triggers. However, most existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose a novel backdoor attack, making imperceptible changes. Concretely, our attack first utilizes the pre-trained victim model to extract low-level and high-level semantic features from clean images and generates trigger pattern associated with high-level features based on channel attention. Then, the encoder model generates poisoned images based on the trigger and extracted low-level semantic features without causing noticeable feature loss. We evaluate our attack on three prominent image classification DNN across three standard datasets. The results demonstrate that our attack achieves high attack success rates while maintaining robustness against backdoor defenses. Furthermore, we conduct extensive image similarity experiments to emphasize the stealthiness of our attack strategy.
Read more5/21/2024

0
Backdoor Defense through Self-Supervised and Generative Learning
Ivan Saboli'c, Ivan Grubiv{s}i'c, Siniv{s}a v{S}egvi'c
Backdoor attacks change a small portion of training data by introducing hand-crafted triggers and rewiring the corresponding labels towards a desired target class. Training on such data injects a backdoor which causes malicious inference in selected test samples. Most defenses mitigate such attacks through various modifications of the discriminative learning procedure. In contrast, this paper explores an approach based on generative modelling of per-class distributions in a self-supervised representation space. Interestingly, these representations get either preserved or heavily disturbed under recent backdoor attacks. In both cases, we find that per-class generative models allow to detect poisoned data and cleanse the dataset. Experiments show that training on cleansed dataset greatly reduces the attack success rate and retains the accuracy on benign inputs.
Read more9/4/2024