Trends and Challenges of Real-time Learning in Large Language Models: A Critical Review

0
💬
Sign in to get full access
Overview
- Incremental learning is the ability of systems to acquire knowledge over time, enabling their adaptation and generalization to novel tasks.
- It is a critical ability for intelligent, real-world systems, especially when data changes frequently or is limited.
- This review provides a comprehensive analysis of incremental learning in Large Language Models (LLMs).
- It synthesizes the state-of-the-art incremental learning paradigms, including continual learning, meta-learning, parameter-efficient learning, and mixture-of-experts learning.
- The review demonstrates the utility of these approaches for incremental learning and describes their critical factors.
- An important finding is that many of these approaches do not update the core model, and none of them update incrementally in real-time.
- The paper highlights current problems and challenges for future research in the field.
Plain English Explanation
The paper discusses incremental learning, which is the ability of artificial intelligence (AI) systems to learn and acquire new knowledge over time. This is a crucial capability for intelligent, real-world systems that need to adapt and generalize to new tasks, especially when the data they work with changes frequently or is limited.
The review examines how this incremental learning ability can be applied to Large Language Models (LLMs), which are AI systems trained on vast amounts of text data to understand and generate human-like language. The paper synthesizes the latest research on different approaches to incremental learning, such as continual learning, meta-learning, parameter-efficient learning, and mixture-of-experts learning.
The review describes how these techniques can be used to help LLMs continuously learn and adapt, rather than being limited to their initial training. However, it also finds that many of these approaches do not actually update the core LLM model itself, and none of them can do so in real-time. The paper highlights the current challenges and problems that researchers in this field need to address.
By consolidating the latest relevant research, this review aims to provide a comprehensive understanding of incremental learning and its implications for designing and developing more adaptable and capable LLM-based systems.
Technical Explanation
The paper reviews the state-of-the-art in incremental learning paradigms and their application to Large Language Models (LLMs). It examines several key incremental learning approaches, including:
- Continual Learning: The ability to learn new tasks or skills without forgetting previously learned information.
- Meta-Learning: The process of learning how to learn, allowing a model to quickly adapt to new tasks or environments.
- Parameter-Efficient Learning: Techniques that update only a small subset of a model's parameters, rather than the entire model, to learn new information.
- Mixture-of-Experts Learning: Architectures that combine multiple specialized sub-models (experts) to handle different tasks or domains.
The review describes how these paradigms have been applied to LLMs and the specific achievements made in each area. It also discusses the critical factors that contribute to the success of these incremental learning approaches.
An important finding is that many of these techniques do not actually update the core LLM model itself, but rather use auxiliary components or mechanisms to enable incremental learning. Additionally, none of the approaches discussed can perform incremental updates in real-time.
The paper concludes by highlighting the current problems and challenges that need to be addressed in future research to develop truly incremental and adaptable LLM-based systems.
Critical Analysis
The review provides a thorough and well-researched overview of the state-of-the-art in incremental learning approaches for Large Language Models. However, it also identifies several critical limitations and areas for further research:
Limitations of Existing Approaches:
- Many of the incremental learning techniques do not actually update the core LLM model, but rather rely on auxiliary components or mechanisms. This may limit the model's ability to truly learn and adapt over time.
- None of the approaches discussed can perform incremental updates in real-time, which is a crucial requirement for many real-world applications.
Areas for Further Research:
- Developing LLM architectures and training techniques that can efficiently and effectively update the core model in an incremental fashion, without catastrophic forgetting of previous knowledge.
- Exploring methods for performing incremental updates in real-time, to enable truly adaptive and responsive LLM-based systems.
- Investigating the integration of different incremental learning paradigms (e.g., continual learning, meta-learning) to leverage their complementary strengths.
- Evaluating the long-term consequences and societal implications of deploying continuously learning and adapting LLMs in real-world applications.
By highlighting these critical limitations and future research directions, the review encourages readers to think critically about the current state of the field and the challenges that need to be addressed to realize the full potential of incremental learning in LLMs.
Conclusion
This comprehensive review provides a detailed analysis of the state-of-the-art in incremental learning for Large Language Models. It synthesizes the latest research on key incremental learning paradigms, such as continual learning, meta-learning, parameter-efficient learning, and mixture-of-experts learning, and demonstrates their potential utility for enabling LLMs to continuously acquire new knowledge and adapt to changing environments.
However, the review also identifies important limitations in the current approaches, notably the lack of core model updates and the absence of real-time incremental learning capabilities. These findings underscore the significant challenges that researchers in this field need to overcome to develop truly adaptive and responsive LLM-based systems.
By consolidating the latest relevant research and highlighting both the achievements and open problems, this review offers a comprehensive understanding of incremental learning and its implications for the future of Large Language Models and their applications. It serves as a valuable resource for researchers, developers, and practitioners working to advance the state-of-the-art in this critical area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Trends and Challenges of Real-time Learning in Large Language Models: A Critical Review
Mladjan Jovanovic, Peter Voss
Incremental learning is the ability of systems to acquire knowledge over time, enabling their adaptation and generalization to novel tasks. It is a critical ability for intelligent, real-world systems, especially when data changes frequently or is limited. This review provides a comprehensive analysis of incremental learning in Large Language Models. It synthesizes the state-of-the-art incremental learning paradigms, including continual learning, meta-learning, parameter-efficient learning, and mixture-of-experts learning. We demonstrate their utility for incremental learning by describing specific achievements from these related topics and their critical factors. An important finding is that many of these approaches do not update the core model, and none of them update incrementally in real-time. The paper highlights current problems and challenges for future research in the field. By consolidating the latest relevant research developments, this review offers a comprehensive understanding of incremental learning and its implications for designing and developing LLM-based learning systems.
Read more5/7/2024
💬
0
Towards Lifelong Learning of Large Language Models: A Survey
Junhao Zheng, Shengjie Qiu, Chengming Shi, Qianli Ma
As the applications of large language models (LLMs) expand across diverse fields, the ability of these models to adapt to ongoing changes in data, tasks, and user preferences becomes crucial. Traditional training methods, relying on static datasets, are increasingly inadequate for coping with the dynamic nature of real-world information. Lifelong learning, also known as continual or incremental learning, addresses this challenge by enabling LLMs to learn continuously and adaptively over their operational lifetime, integrating new knowledge while retaining previously learned information and preventing catastrophic forgetting. This survey delves into the sophisticated landscape of lifelong learning, categorizing strategies into two primary groups: Internal Knowledge and External Knowledge. Internal Knowledge includes continual pretraining and continual finetuning, each enhancing the adaptability of LLMs in various scenarios. External Knowledge encompasses retrieval-based and tool-based lifelong learning, leveraging external data sources and computational tools to extend the model's capabilities without modifying core parameters. The key contributions of our survey are: (1) Introducing a novel taxonomy categorizing the extensive literature of lifelong learning into 12 scenarios; (2) Identifying common techniques across all lifelong learning scenarios and classifying existing literature into various technique groups within each scenario; (3) Highlighting emerging techniques such as model expansion and data selection, which were less explored in the pre-LLM era. Through a detailed examination of these groups and their respective categories, this survey aims to enhance the adaptability, reliability, and overall performance of LLMs in real-world applications.
Read more6/11/2024
0
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
Read more7/2/2024
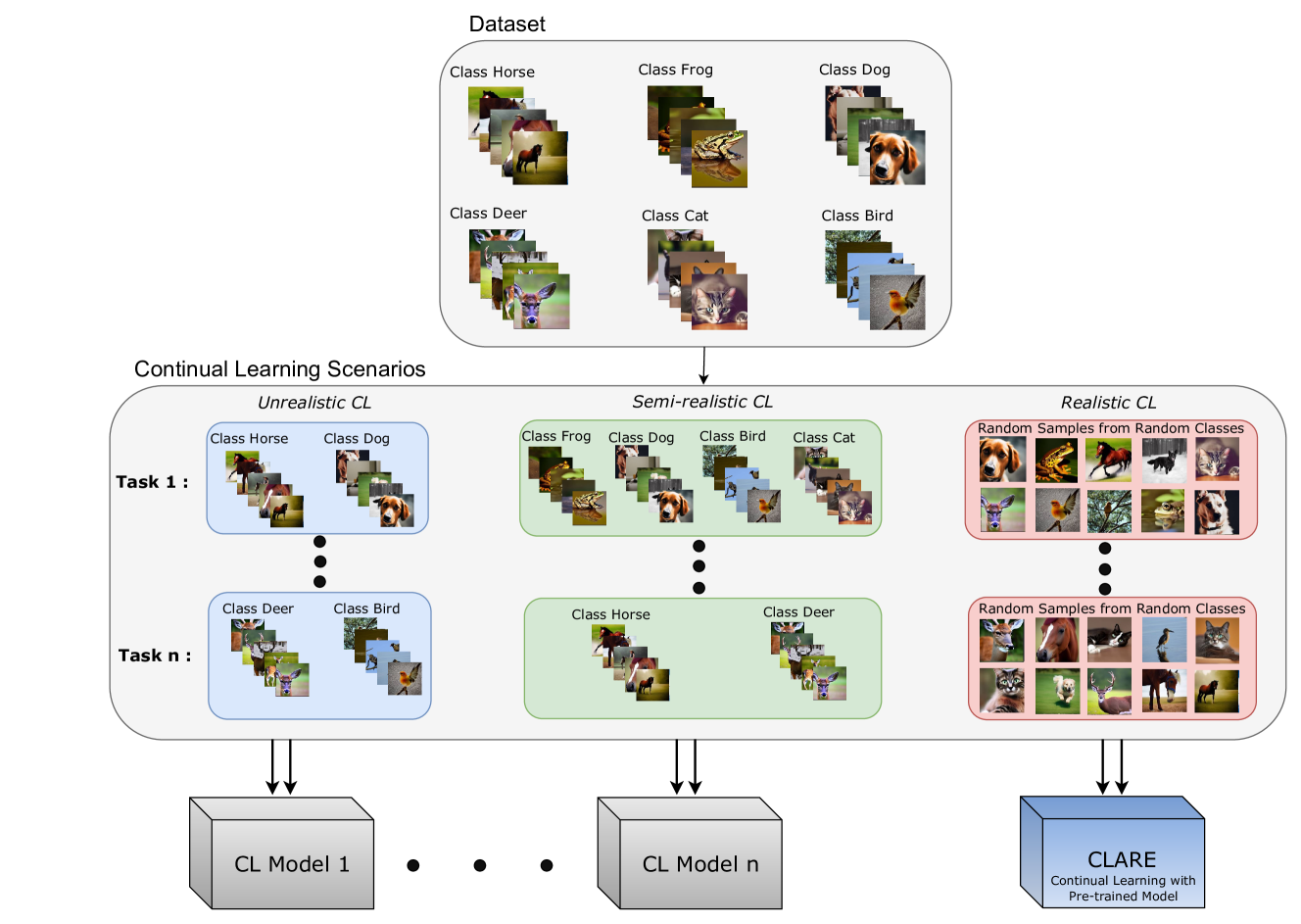
0
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024