Towards Language-Driven Video Inpainting via Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of multimodal large language models for video inpainting, which is the task of filling in missing or corrupted regions in a video.
- The researchers introduce the ROVI dataset, a new benchmark for language-driven video inpainting.
- They propose a multimodal architecture that combines visual and language understanding to generate plausible video inpainted content.
Plain English Explanation
The researchers in this paper are investigating how to use advanced language models, which are AI systems trained on vast amounts of text data, to help fill in missing or damaged parts of videos. This task, called "video inpainting," is challenging because it requires understanding both the visual content of the video and the textual descriptions or instructions related to what should be in the missing regions.
To tackle this problem, the researchers created a new dataset called ROVI, which contains videos with intentionally removed sections, along with text descriptions of what should be in those missing parts. They then developed a multimodal neural network architecture that can take in both the video and the text descriptions, and use that combined information to generate plausible content to "fill in" the gaps.
The key idea is that the language model can provide high-level guidance on what the missing content should depict, while the visual understanding components of the network can generate the actual pixels to match that description. By leveraging both vision and language, the system can produce more coherent and realistic inpainted video content compared to approaches that only use visual information.
Technical Explanation
The paper begins by outlining the video inpainting task and reviewing related work in this area. The researchers then introduce the ROVI dataset, which consists of videos with intentionally removed regions, paired with text descriptions of the missing content.
The core of the paper is the proposed multimodal architecture for language-driven video inpainting. This model takes the corrupted video and the corresponding text description as input, and outputs the inpainted video. The architecture includes both visual and language understanding components, which are trained jointly to generate the final inpainted video.
The visual component is based on a convolutional neural network that encodes the video frames, while the language component uses a transformer-based model to encode the text description. These two encodings are then combined and passed through a series of refinement steps to produce the final inpainted video.
The researchers evaluate their approach on the ROVI dataset and compare it to several baselines. They find that their multimodal model significantly outperforms methods that only use visual information, demonstrating the value of integrating language understanding for this task.
Critical Analysis
The key strengths of this work are the introduction of the ROVI dataset, which provides a valuable benchmark for language-driven video inpainting, and the novel multimodal architecture that leverages both visual and textual information. By combining these two modalities, the model is able to produce more coherent and realistic inpainted video content compared to previous approaches.
That said, the paper does not address some important limitations and potential issues with the proposed system. For example, it's unclear how well the model would generalize to more open-ended or complex text descriptions, beyond the relatively constrained prompts in the ROVI dataset. Additionally, the model's performance on more challenging or ambiguous inpainting scenarios is not explored.
Another potential concern is the model's reliance on pre-trained language and vision components, which could introduce biases or limitations from those underlying models. Further research is needed to understand the robustness and generalization capabilities of this approach.
Overall, this work represents an interesting step forward in the field of video inpainting, demonstrating the value of multimodal reasoning for this task. However, there are still many open questions and avenues for future research to fully realize the potential of language-guided video inpainting.
Conclusion
This paper presents a novel approach to video inpainting that leverages multimodal large language models. By combining visual and textual understanding, the proposed architecture is able to generate more coherent and realistic inpainted video content compared to previous methods.
The introduction of the ROVI dataset provides a valuable benchmark for this task, and the key technical contributions, including the multimodal model design and joint training approach, represent an important advance in the field of video inpainting.
While the paper demonstrates the potential of this approach, there are still many open questions and areas for further research, such as exploring more complex and open-ended language guidance, and understanding the robustness and generalization capabilities of the model. Nonetheless, this work represents an exciting step forward in the quest to develop AI systems that can effectively understand and manipulate video content through the integration of vision and language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Towards Language-Driven Video Inpainting via Multimodal Large Language Models
Jianzong Wu, Xiangtai Li, Chenyang Si, Shangchen Zhou, Jingkang Yang, Jiangning Zhang, Yining Li, Kai Chen, Yunhai Tong, Ziwei Liu, Chen Change Loy
We introduce a new task -- language-driven video inpainting, which uses natural language instructions to guide the inpainting process. This approach overcomes the limitations of traditional video inpainting methods that depend on manually labeled binary masks, a process often tedious and labor-intensive. We present the Remove Objects from Videos by Instructions (ROVI) dataset, containing 5,650 videos and 9,091 inpainting results, to support training and evaluation for this task. We also propose a novel diffusion-based language-driven video inpainting framework, the first end-to-end baseline for this task, integrating Multimodal Large Language Models to understand and execute complex language-based inpainting requests effectively. Our comprehensive results showcase the dataset's versatility and the model's effectiveness in various language-instructed inpainting scenarios. We will make datasets, code, and models publicly available.
Read more10/2/2024

0
Image Inpainting Models are Effective Tools for Instruction-guided Image Editing
Xuan Ju, Junhao Zhuang, Zhaoyang Zhang, Yuxuan Bian, Qiang Xu, Ying Shan
This is the technique report for the winning solution of the CVPR2024 GenAI Media Generation Challenge Workshop's Instruction-guided Image Editing track. Instruction-guided image editing has been largely studied in recent years. The most advanced methods, such as SmartEdit and MGIE, usually combine large language models with diffusion models through joint training, where the former provides text understanding ability, and the latter provides image generation ability. However, in our experiments, we find that simply connecting large language models and image generation models through intermediary guidance such as masks instead of joint fine-tuning leads to a better editing performance and success rate. We use a 4-step process IIIE (Inpainting-based Instruction-guided Image Editing): editing category classification, main editing object identification, editing mask acquisition, and image inpainting. Results show that through proper combinations of language models and image inpainting models, our pipeline can reach a high success rate with satisfying visual quality.
Read more7/19/2024
🖼️
0
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Navve Wasserman, Noam Rotstein, Roy Ganz, Ron Kimmel
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that inpaint within these masks. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
Read more4/30/2024
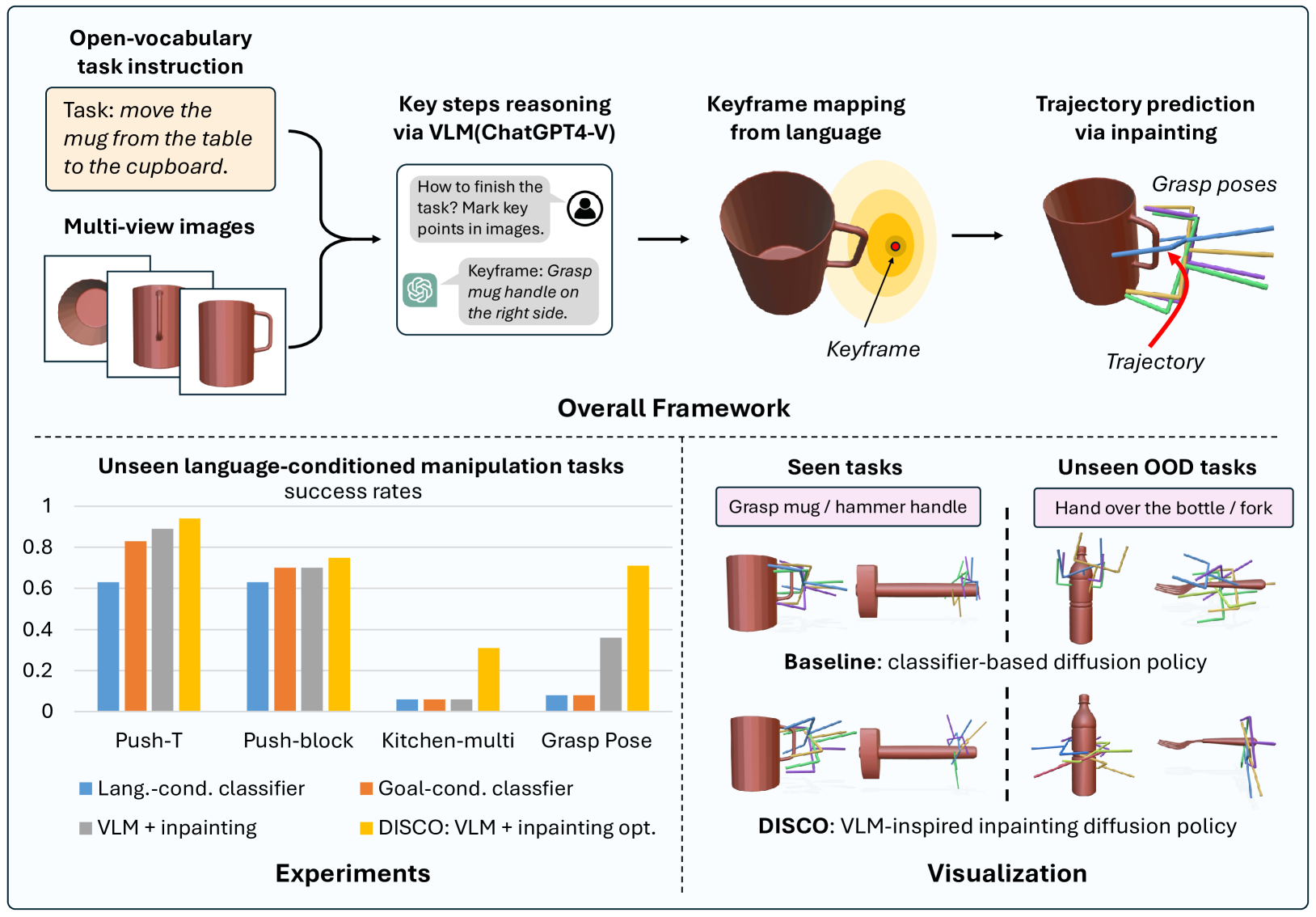
0
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Ce Hao, Kelvin Lin, Siyuan Luo, Harold Soh
Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
Read more9/24/2024