Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting

0
Sign in to get full access
Overview
- This paper presents a novel language-guided manipulation approach that combines diffusion-based image generation with constrained inpainting.
- The proposed method allows users to manipulate images by providing natural language instructions, enabling more intuitive and flexible image editing.
- The system leverages diffusion models, a powerful class of generative AI models, to generate and edit images based on the given language prompts.
- Additionally, the researchers introduce a constrained inpainting technique to seamlessly integrate the edited regions with the original image.
Plain English Explanation
The researchers have developed a new way to edit images using natural language instructions. Instead of relying on complex software tools or manual adjustments, users can simply describe what they want to change in an image, and the system will automatically make those modifications.
The key innovation is the use of diffusion models, a type of AI model that can generate and manipulate images based on textual descriptions. These models are trained on a vast amount of image-text pairs, allowing them to understand the relationship between language and visual content.
By combining diffusion models with a constrained inpainting technique, the researchers have created a system that can seamlessly integrate the edited regions back into the original image. This means that the changes made to the image will look natural and coherent, rather than appearing as a separate, pasted-on element.
The researchers demonstrate the capabilities of their system through various examples, showing how users can easily modify an image's composition, replace objects, or even add entirely new elements just by describing what they want to see. This approach has the potential to revolutionize image editing, making it more accessible and intuitive for a wide range of users.
Technical Explanation
The researchers propose a language-guided image manipulation framework that combines diffusion-based image generation with constrained inpainting. The core components of their approach are:
-
Diffusion-based Image Generation: The system leverages diffusion models, a class of generative AI models that can synthesize and edit images based on textual descriptions. These models are trained on large datasets of image-text pairs, allowing them to learn the association between language and visual content.
-
Constrained Inpainting: To seamlessly integrate the edited regions with the original image, the researchers introduce a constrained inpainting technique. This approach ensures that the modified areas match the surrounding context and blend naturally with the rest of the image.
The researchers evaluate their method on various image manipulation tasks, including object replacement, scene composition, and image completion. They demonstrate the effectiveness of their approach through qualitative and quantitative experiments, showcasing the system's ability to generate high-quality, language-guided image edits.
Critical Analysis
The proposed language-guided image manipulation framework is a promising step towards more intuitive and flexible image editing tools. By leveraging the power of diffusion models and constrained inpainting, the researchers have developed a system that can generate and integrate seamless image edits based on natural language instructions.
One potential limitation of the approach is that it may struggle with highly complex or fine-grained manipulations that require a deeper understanding of the image's semantic content and spatial relationships. The researchers acknowledge this challenge and suggest that further research is needed to address more advanced editing scenarios, such as reinforcement learning-based image editing or language-grounded video diffusion models.
Additionally, the performance of the system is likely dependent on the quality and diversity of the training data used to build the diffusion models. Biases or limitations in the training data could lead to suboptimal or even undesirable results in certain cases.
Overall, the research represents an important step forward in the field of language-guided image manipulation, demonstrating the potential of combining generative AI models with constrained inpainting techniques. As the field continues to evolve, it will be interesting to see how these approaches are further refined and applied to more complex and challenging image editing scenarios.
Conclusion
The paper presents a novel language-guided image manipulation framework that leverages diffusion-based image generation and constrained inpainting. This approach enables users to edit images more intuitively by simply describing the desired changes in natural language, without the need for specialized software or manual adjustments.
The core innovation lies in the integration of powerful diffusion models, which can generate and manipulate images based on textual descriptions, with a constrained inpainting technique that ensures the edited regions seamlessly blend with the original image. This combination allows for more seamless and naturalistic image edits, expanding the possibilities for accessible and flexible image manipulation.
The researchers demonstrate the effectiveness of their approach through various examples, showcasing its potential to revolutionize image editing workflows. While the current system has some limitations, the research represents an important step forward in the field of language-guided visual manipulation, paving the way for more advanced and user-friendly image editing tools in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Ce Hao, Kelvin Lin, Siyuan Luo, Harold Soh
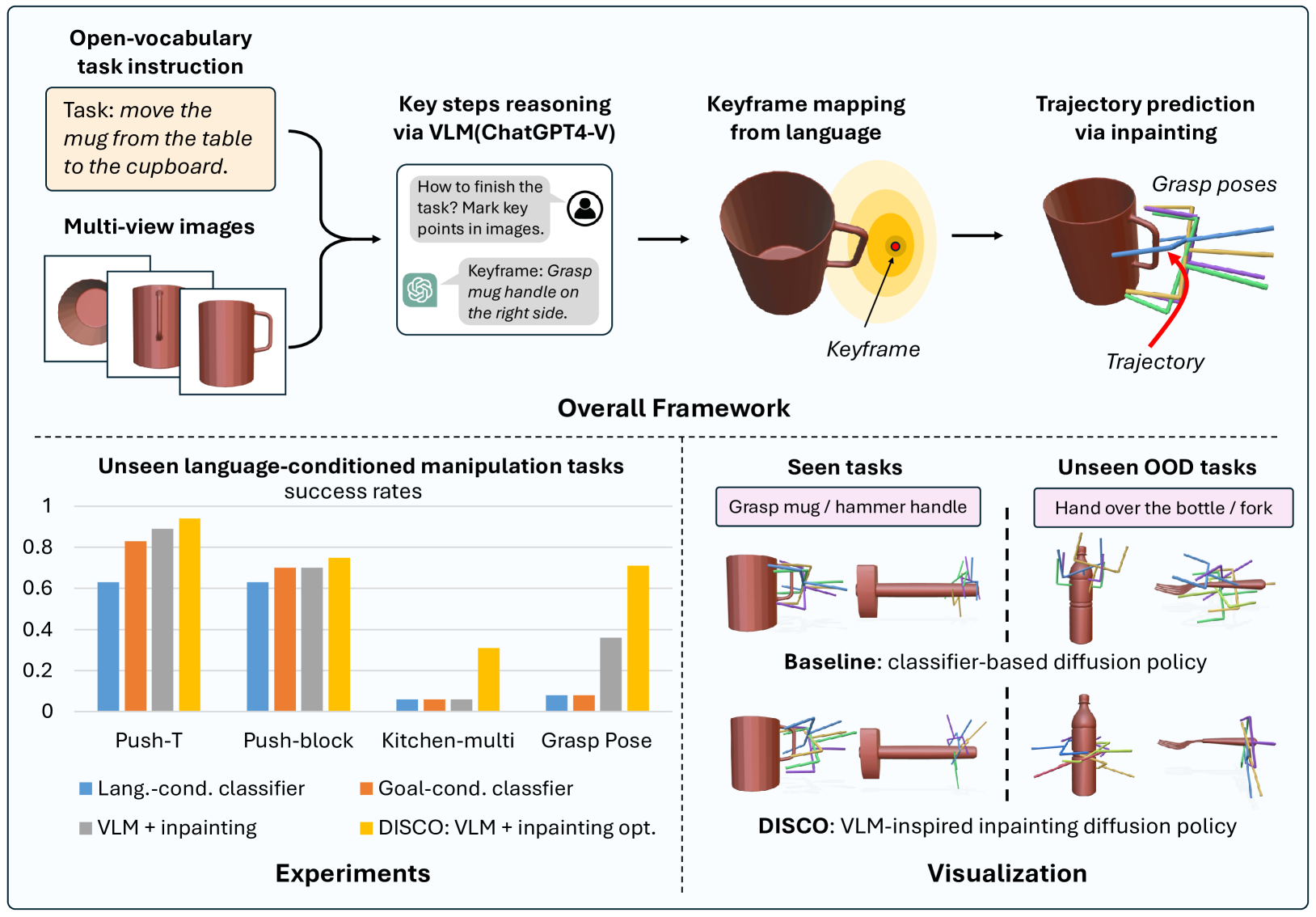
Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
Read more9/24/2024

0
Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Alois Knoll
Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
Read more7/8/2024

0
New!Towards Language-Driven Video Inpainting via Multimodal Large Language Models
Jianzong Wu, Xiangtai Li, Chenyang Si, Shangchen Zhou, Jingkang Yang, Jiangning Zhang, Yining Li, Kai Chen, Yunhai Tong, Ziwei Liu, Chen Change Loy
We introduce a new task -- language-driven video inpainting, which uses natural language instructions to guide the inpainting process. This approach overcomes the limitations of traditional video inpainting methods that depend on manually labeled binary masks, a process often tedious and labor-intensive. We present the Remove Objects from Videos by Instructions (ROVI) dataset, containing 5,650 videos and 9,091 inpainting results, to support training and evaluation for this task. We also propose a novel diffusion-based language-driven video inpainting framework, the first end-to-end baseline for this task, integrating Multimodal Large Language Models to understand and execute complex language-based inpainting requests effectively. Our comprehensive results showcase the dataset's versatility and the model's effectiveness in various language-instructed inpainting scenarios. We will make datasets, code, and models publicly available.
Read more10/2/2024

0
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Vivek Myers, Bill Chunyuan Zheng, Oier Mees, Sergey Levine, Kuan Fang
Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.
Read more8/30/2024