Towards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
2404.02512
0
0

Abstract
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
Create account to get full access
Overview
- This paper proposes a reference-less approach to evaluate machine translations between English and Indian languages using large language models.
- The authors develop a new metric called RLEE (Reference-Less Language Evaluation) that does not require reference translations, which can be costly and difficult to obtain.
- RLEE is designed to work for both English and a variety of Indian languages, addressing the challenge of evaluating translations for low-resource languages.
- The authors compare RLEE to existing reference-based and reference-less metrics, and show that it performs well across different language pairs and translation tasks.
Plain English Explanation
The paper tackles the problem of evaluating the quality of machine translations, especially between English and different Indian languages. Traditionally, this has been done by comparing the machine-generated translations to high-quality human translations, called reference translations. However, creating these reference translations can be time-consuming and expensive, especially for less common or low-resource languages.
The researchers developed a new evaluation method called RLEE that does not require reference translations. Instead, RLEE uses large language models - advanced AI systems trained on massive amounts of text - to assess the fluency and meaning of the machine translations directly. This makes the evaluation process much simpler and more accessible, especially for languages that may have fewer available resources.
The key insight is that these powerful language models can understand the meaning and naturalness of text, even without access to perfect reference translations. By analyzing the machine translations through the lens of the language model, RLEE can provide a reliable assessment of translation quality.
The authors tested RLEE on translations between English and several Indian languages, and found that it performed well compared to existing evaluation methods. This suggests RLEE could be a useful tool for quickly and affordably assessing machine translation quality, especially for language pairs where reference translations are scarce.
Technical Explanation
The paper proposes a new reference-less translation evaluation metric called RLEE (Reference-Less Language Evaluation) that leverages large language models. The authors argue that traditional reference-based metrics, while effective, can be costly and difficult to apply, especially for low-resource language pairs.
To address this, the RLEE approach uses the contextual understanding of large language models to directly assess the fluency and adequacy of machine translations, without requiring parallel reference translations. The authors experiment with different language model architectures and fine-tuning approaches to optimize RLEE's performance.
The paper evaluates RLEE across a variety of language pairs, including English-Hindi, English-Bengali, and English-Tamil. The results show that RLEE correlates well with human judgments of translation quality, and outperforms other reference-less metrics like BERTScore. Notably, RLEE demonstrates strong performance even for low-resource language pairs, addressing a key limitation of reference-based approaches.
The authors also analyze the types of translation errors RLEE is able to detect, finding that it captures both fluency issues (e.g. grammatical errors) as well as adequacy problems (e.g. meaning preservation). This suggests RLEE could be a useful tool for both system development and human evaluation of machine translations.
Critical Analysis
The paper makes a strong case for the value of reference-less translation evaluation, particularly in the context of low-resource language pairs. By leveraging powerful language models, the RLEE approach sidesteps the challenges of obtaining high-quality reference translations, which can be a significant bottleneck.
That said, the authors acknowledge that RLEE is not a perfect replacement for reference-based metrics. In certain scenarios, particularly for high-resource language pairs, reference-based approaches may still be preferable. The paper also notes that RLEE's performance can vary depending on the specific language model and fine-tuning approach used.
Additionally, while RLEE shows promise for detecting both fluency and adequacy issues, the authors do not provide a detailed breakdown of its performance on these different error types. Further research could explore how RLEE's capabilities compare to human evaluation in more nuanced ways.
It would also be valuable to see the RLEE approach tested on a broader range of language pairs, including more distant or morphologically complex languages. This could help validate the generalizability of the technique and identify any potential limitations.
Overall, the RLEE metric represents an important step forward in making translation evaluation more accessible and applicable, especially for low-resource scenarios. As language models continue to advance, reference-less approaches like this may become increasingly important tools in the machine translation ecosystem.
Conclusion
This paper presents a novel reference-less approach to evaluating machine translations between English and Indian languages, called RLEE. By leveraging powerful language models, RLEE is able to assess translation quality without the need for costly parallel reference data.
The authors demonstrate that RLEE correlates well with human judgments of translation quality, and outperforms other reference-less metrics, particularly for low-resource language pairs. This makes RLEE a promising tool for efficiently evaluating machine translations, especially in scenarios where reference translations are scarce or difficult to obtain.
While RLEE is not a perfect substitute for reference-based evaluation, it represents an important advancement in making translation assessment more accessible and scalable. As machine translation systems continue to improve, reference-less approaches like this will likely become increasingly valuable for both system development and real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
💬
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Xu Huang, Zhirui Zhang, Xiang Geng, Yichao Du, Jiajun Chen, Shujian Huang
0
0
This study investigates how Large Language Models (LLMs) leverage source and reference data in machine translation evaluation task, aiming to better understand the mechanisms behind their remarkable performance in this task. We design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. We find that reference information significantly enhances the evaluation accuracy, while surprisingly, source information sometimes is counterproductive, indicating LLMs' inability to fully leverage the cross-lingual capability when evaluating translations. Further analysis of the fine-grained evaluation and fine-tuning experiments show similar results. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
6/7/2024
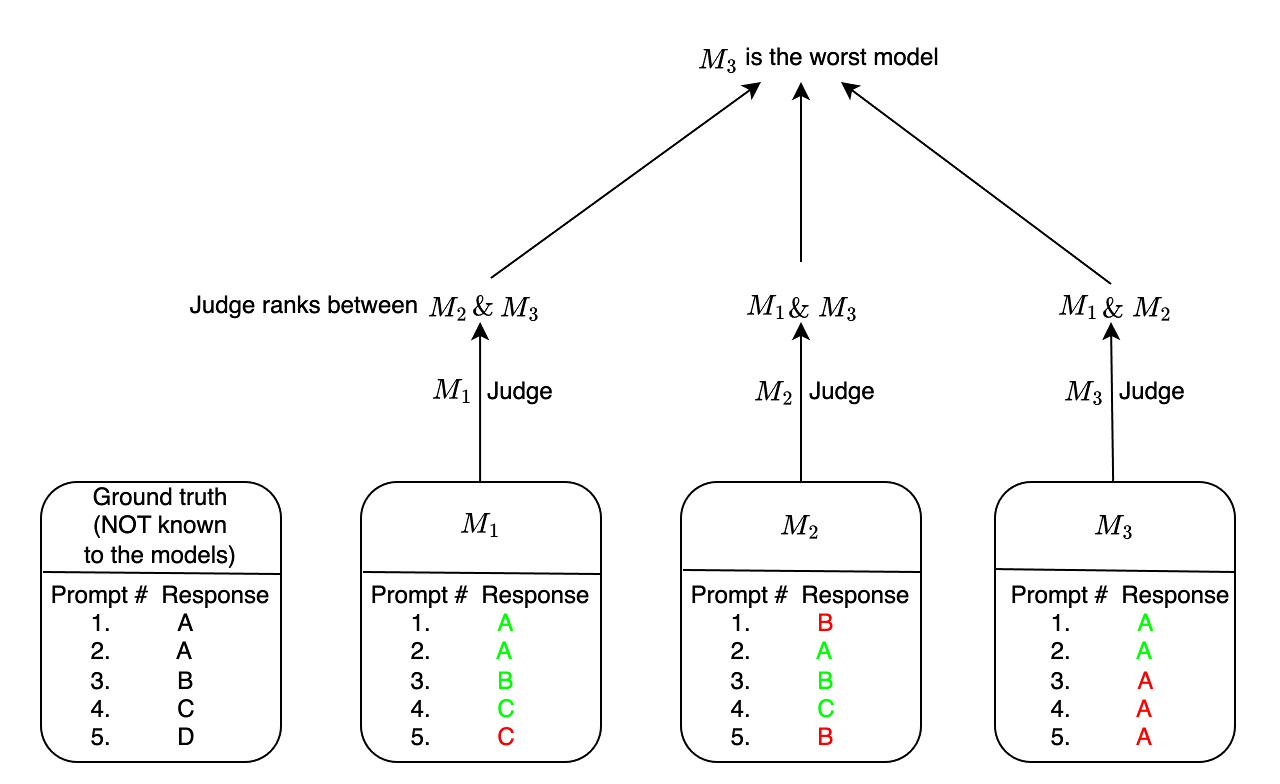
Ranking Large Language Models without Ground Truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
0
0
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
6/11/2024

PARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Ishaan Watts, Varun Gumma, Aditya Yadavalli, Vivek Seshadri, Manohar Swaminathan, Sunayana Sitaram
0
0
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
6/24/2024