Towards Large Language Models as Copilots for Theorem Proving in Lean
2404.12534
0
0
Abstract
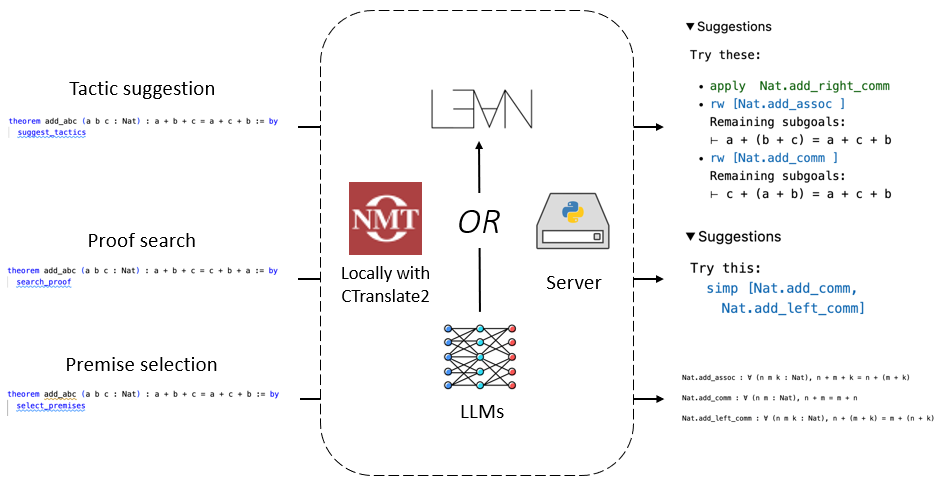
Theorem proving is an important challenge for large language models (LLMs), as formal proofs can be checked rigorously by proof assistants such as Lean, leaving no room for hallucination. Existing LLM-based provers try to prove theorems in a fully autonomous mode without human intervention. In this mode, they struggle with novel and challenging theorems, for which human insights may be critical. In this paper, we explore LLMs as copilots that assist humans in proving theorems. We introduce Lean Copilot, a framework for running LLM inference in Lean. It enables programmers to build various LLM-based proof automation tools that integrate seamlessly into the workflow of Lean users. Using Lean Copilot, we build tools for suggesting proof steps (tactic suggestion), completing intermediate proof goals (proof search), and selecting relevant premises (premise selection) using LLMs. Users can use our pretrained models or bring their own ones that run either locally (with or without GPUs) or on the cloud. Experimental results demonstrate the effectiveness of our method in assisting humans and automating theorem proving process compared to existing rule-based proof automation in Lean. We open source all codes under a permissive MIT license to facilitate further research.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) as "copilots" to assist with theorem proving in the Lean theorem prover.
- The researchers develop a system called "Lean Copilot" that allows LLMs to be used natively within the Lean environment, enabling tighter integration and more effective proof automation.
- The paper demonstrates how Lean Copilot can be used to build LLM-based proof automation tools that outperform traditional approaches on certain theorem-proving tasks.
Plain English Explanation
Theorem proving is an important field of computer science and mathematics, where researchers try to develop algorithms and systems that can automatically prove mathematical statements. This is a challenging task, as it often requires complex logical reasoning and deep domain knowledge.
The researchers behind this paper believe that large language models (LLMs) - powerful AI systems trained on vast amounts of text data - could be a valuable tool for assisting with theorem proving. LLMs have shown remarkable capabilities in tasks like natural language processing and generation, and the researchers wondered if they could be used to help automate parts of the theorem-proving process.
To explore this idea, the researchers developed a system called "Lean Copilot" that allows LLMs to be used directly within the Lean theorem prover. Lean is a popular open-source theorem prover used by mathematicians and computer scientists to formally verify the correctness of their work.
With Lean Copilot, the researchers were able to build proof automation tools that leverage the capabilities of LLMs. These tools were able to outperform traditional proof automation techniques on certain theorem-proving tasks, suggesting that LLMs could be a powerful addition to the theorem-proving toolbox.
The researchers believe that this work represents an important step towards using large language models as "copilots" - intelligent assistants that can help human experts with complex cognitive tasks like theorem proving. By integrating LLMs more tightly with theorem provers like Lean, the researchers hope to unlock new possibilities for automating and accelerating mathematical reasoning.
Technical Explanation
The key technical contribution of this paper is the development of "Lean Copilot", a system that allows large language models (LLMs) to be used natively within the Lean theorem prover. Traditionally, using LLMs for theorem proving has been challenging, as they are typically designed for general-purpose language tasks and lack the formal reasoning capabilities required for rigorous mathematical proofs.
Lean Copilot addresses this by providing a tight integration between LLMs and the Lean environment. The system allows Lean users to seamlessly invoke LLM-based inference capabilities directly within their theorem-proving workflows, enabling the LLMs to assist with tasks like proof search, lemma generation, and proof step suggestion.
The researchers demonstrate the effectiveness of Lean Copilot by building several LLM-based proof automation tools and evaluating them on a range of theorem-proving benchmarks. These tools leverage the powerful natural language understanding and generation capabilities of LLMs to outperform traditional proof automation techniques on certain tasks.
For example, the researchers develop a "proof step completion" tool that can suggest the next logical step in a proof based on the current context. By training this tool on a large corpus of Lean proofs, the researchers are able to leverage the LLM's ability to capture patterns and heuristics from the data, allowing it to make more informed proof step suggestions than rule-based approaches.
Overall, the key insights from this paper are:
- Tightly integrating LLMs with theorem provers like Lean can unlock new possibilities for LLM-based proof automation.
- LLM-based proof automation tools can outperform traditional techniques on certain theorem-proving tasks by leveraging the LLM's ability to learn from data.
- Lean Copilot provides a flexible framework for building and experimenting with LLM-based proof automation tools within the Lean ecosystem.
Critical Analysis
The researchers have made a compelling case for the potential of large language models to serve as "copilots" for theorem proving, but there are still several important challenges and limitations to consider:
-
Soundness and Reliability: While the LLM-based proof automation tools demonstrated in the paper show promising results, it's crucial to ensure that they maintain the soundness and reliability required for formal mathematical reasoning. Integrating LLMs into theorem provers like Lean introduces the risk of introducing unsound or incorrect proof steps, which could undermine the entire verification process.
-
Interpretability and Explainability: Theorem proving often requires step-by-step logical reasoning that can be difficult to extract from the black-box behavior of large language models. Improving the interpretability and explainability of LLM-based proof automation tools will be essential for building trust and adoption in the mathematical and computer science communities.
-
Scalability and Generalization: The experiments in the paper focused on a relatively narrow set of theorem-proving tasks and datasets. It's unclear how well the LLM-based approaches would scale to more complex, large-scale theorem-proving problems or generalize to new domains beyond the training data.
-
Human-AI Collaboration: While the researchers envision LLMs as "copilots" for theorem proving, it's important to consider how these systems would actually be used in practice. Striking the right balance between human expertise and AI assistance, and understanding the roles and responsibilities of each, will be a key challenge in deploying these technologies effectively.
Despite these limitations, this paper represents an important step towards exploring the potential of large language models in the domain of theorem proving. As the researchers continue to refine and expand their work, addressing the challenges outlined above will be crucial for turning this promising idea into a practical and reliable tool for mathematical reasoning.
Conclusion
This paper presents a novel approach to leveraging large language models (LLMs) as "copilots" for theorem proving in the Lean theorem prover. By developing the Lean Copilot system, the researchers have demonstrated how LLMs can be tightly integrated with theorem-proving environments to enable new forms of proof automation and assistance.
The key contributions of this work are:
- The Lean Copilot system, which allows LLMs to be used natively within the Lean ecosystem, providing a flexible platform for building and experimenting with LLM-based proof automation tools.
- Several proof automation tools built using Lean Copilot that leverage the strengths of LLMs to outperform traditional approaches on certain theorem-proving tasks.
- Insights into the potential of LLMs to serve as "copilots" for theorem proving, assisting human experts with complex logical reasoning and proof construction.
While this research represents an important step forward, there are still significant challenges to address in terms of ensuring the soundness, interpretability, and scalability of LLM-based proof automation. Nonetheless, the ideas presented in this paper point towards an exciting future where powerful language models and theorem provers collaborate to push the boundaries of automated mathematical reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts
Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, Tong Zhang
0
0
Proving mathematical theorems using computer-verifiable formal languages like Lean significantly impacts mathematical reasoning. One approach to formal theorem proving involves generating complete proofs using Large Language Models (LLMs) based on Natural Language (NL) proofs. Similar methods have shown promising results in code generation. However, most modern LLMs exhibit suboptimal performance due to the scarcity of aligned NL and Formal Language (FL) theorem-proving data. This scarcity results in a paucity of methodologies for training LLMs and techniques to fully utilize their capabilities in composing formal proofs. To address the challenges, this paper proposes **TheoremLlama**, an end-to-end framework to train a general-purpose LLM to become a Lean4 expert. This framework encompasses NL-FL aligned dataset generation methods, training approaches for the LLM formal theorem prover, and techniques for LLM Lean4 proof writing. Using the dataset generation method, we provide *Open Bootstrapped Theorems* (OBT), an NL-FL aligned and bootstrapped dataset. A key innovation in this framework is the NL-FL bootstrapping method, where NL proofs are integrated into Lean4 code for training datasets, leveraging the NL reasoning ability of LLMs for formal reasoning. The **TheoremLlama** framework achieves cumulative accuracies of 36.48% and 33.61% on MiniF2F-Valid and Test datasets respectively, surpassing the GPT-4 baseline of 22.95% and 25.41%. We have also open-sourced our model checkpoints and generated dataset, and will soon make all the code publicly available.
7/4/2024
📊
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, Xiaodan Liang
0
0
Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
5/24/2024

Towards Large Language Model Aided Program Refinement
Yufan Cai, Zhe Hou, Xiaokun Luan, David Miguel Sanan Baena, Yun Lin, Jun Sun, Jin Song Dong
0
0
Program refinement involves correctness-preserving transformations from formal high-level specification statements into executable programs. Traditional verification tool support for program refinement is highly interactive and lacks automation. On the other hand, the emergence of large language models (LLMs) enables automatic code generations from informal natural language specifications. However, code generated by LLMs is often unreliable. Moreover, the opaque procedure from specification to code provided by LLM is an uncontrolled black box. We propose LLM4PR, a tool that combines formal program refinement techniques with informal LLM-based methods to (1) transform the specification to preconditions and postconditions, (2) automatically build prompts based on refinement calculus, (3) interact with LLM to generate code, and finally, (4) verify that the generated code satisfies the conditions of refinement calculus, thus guaranteeing the correctness of the code. We have implemented our tool using GPT4, Coq, and Coqhammer, and evaluated it on the HumanEval and EvalPlus datasets.
6/28/2024

Lean Workbook: A large-scale Lean problem set formalized from natural language math problems
Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, Kai Chen
0
0
Large language models have demonstrated impressive capabilities across various natural language processing tasks, especially in solving mathematical problems. However, large language models are not good at math theorem proving using formal languages like Lean. A significant challenge in this area is the scarcity of training data available in these formal languages. To address this issue, we propose a novel pipeline that iteratively generates and filters synthetic data to translate natural language mathematical problems into Lean 4 statements, and vice versa. Our results indicate that the synthetic data pipeline can provide useful training data and improve the performance of LLMs in translating and understanding complex mathematical problems and proofs. Our final dataset contains about 57K formal-informal question pairs along with searched proof from the math contest forum and 21 new IMO questions. We open-source our code at https://github.com/InternLM/InternLM-Math and our data at https://huggingface.co/datasets/InternLM/Lean-Workbook.
6/10/2024