A Survey on Deep Learning for Theorem Proving
2404.09939
0
0

Abstract
Theorem proving is a fundamental aspect of mathematics, spanning from informal reasoning in mathematical language to rigorous derivations in formal systems. In recent years, the advancement of deep learning, especially the emergence of large language models, has sparked a notable surge of research exploring these techniques to enhance the process of theorem proving. This paper presents a pioneering comprehensive survey of deep learning for theorem proving by offering i) a thorough review of existing approaches across various tasks such as autoformalization, premise selection, proofstep generation, and proof search; ii) a meticulous summary of available datasets and strategies for data generation; iii) a detailed analysis of evaluation metrics and the performance of state-of-the-art; and iv) a critical discussion on the persistent challenges and the promising avenues for future exploration. Our survey aims to serve as a foundational reference for deep learning approaches in theorem proving, seeking to catalyze further research endeavors in this rapidly growing field.
Create account to get full access
Overview
- This paper provides a comprehensive survey of deep learning approaches for automated theorem proving, a fundamental task in mathematical logic and computer science.
- The paper covers the background of theorem proving, different deep learning techniques that have been applied, and a critical analysis of the current state of the research.
- Key topics include Enhancing Formal Theorem Proving with a Comprehensive Dataset and Training, Learning from Failure: Fine-Tuning Large Language Models for Theorem Proving Trials, Using Large Language Models for De-Formalization of Natural Mathematical Statements, and Large Language Models for Mathematical Reasoning: Progresses and Challenges.
Plain English Explanation
Theorem proving is the process of rigorously demonstrating that a mathematical statement is true. This is a fundamental task in fields like computer science, where it's used to verify the correctness of computer programs and algorithms.
Deep learning, a powerful form of artificial intelligence, has shown promise in automating parts of the theorem proving process. This paper reviews the different ways deep learning has been applied to theorem proving, from using large language models to understand natural mathematical statements, to training neural networks on datasets of proven theorems to help find new proofs.
The key ideas covered include using comprehensive datasets of proven theorems to train deep learning models, learning from failed attempts at theorem proving to improve model performance, and leveraging the impressive capabilities of large language models to translate between formal mathematical logic and more natural mathematical language.
The paper also discusses the current limitations of these deep learning approaches and highlights areas for future research, such as scaling these techniques to more complex mathematical domains and finding ways to make the models' reasoning more interpretable to human mathematicians.
Technical Explanation
The paper begins by providing background on the task of theorem proving, explaining the distinction between formal and informal approaches. It then surveys the various deep learning techniques that have been explored for automating theorem proving.
One line of work has focused on Enhancing Formal Theorem Proving with a Comprehensive Dataset and Training, where large datasets of proven theorems are used to train neural networks to assist in the formal proof search process. Another approach, Learning from Failure: Fine-Tuning Large Language Models for Theorem Proving Trials, involves fine-tuning large language models on traces of failed theorem proving attempts to improve their ability to guide the proof search.
The paper also discusses Using Large Language Models for De-Formalization of Natural Mathematical Statements, where these powerful language models are used to translate between formal mathematical logic and more natural mathematical language. This can help bridge the gap between how humans and machines reason about mathematics.
Finally, the paper provides a critical analysis of the current state of deep learning for theorem proving, as covered in Large Language Models for Mathematical Reasoning: Progresses and Challenges. It highlights limitations such as the difficulty of scaling these techniques to more advanced mathematical domains and the need for better interpretability of the models' reasoning.
Critical Analysis
The paper provides a comprehensive and balanced overview of the current state of deep learning for theorem proving. It acknowledges the significant progress that has been made in this area, such as the development of large datasets of proven theorems and the ability of language models to translate between formal and natural mathematical language.
However, the paper also rightly points out the limitations of these approaches. Scaling deep learning techniques to more complex mathematical domains remains a significant challenge, as does ensuring the interpretability of the models' reasoning to human mathematicians. The paper suggests that further research is needed to address these issues and truly integrate deep learning into the theorem proving workflow.
One potential area for improvement could be a more detailed discussion of the specific architectural choices and training techniques used in the various deep learning approaches covered. This could provide readers with a better understanding of the technical details and trade-offs involved in these methods.
Overall, the paper serves as a valuable resource for researchers and practitioners interested in the intersection of deep learning and automated theorem proving. It highlights the exciting potential of these techniques, while also maintaining a critical and realistic perspective on the current state of the field.
Conclusion
This paper provides a thorough survey of the use of deep learning for automated theorem proving, a fundamental task in mathematical logic and computer science. It covers the background of theorem proving, the various deep learning techniques that have been applied, and a critical analysis of the current state of the research.
The key takeaways include the promise of using large datasets of proven theorems and fine-tuning large language models to assist in the theorem proving process, as well as the potential of these models to bridge the gap between formal and informal mathematical reasoning. However, the paper also highlights the significant challenges in scaling these techniques to more complex mathematical domains and ensuring the interpretability of the models' reasoning.
Overall, this paper serves as an important resource for researchers and practitioners working at the intersection of deep learning and automated theorem proving, providing a comprehensive overview of the current state of the field and areas for future exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, Xiaodan Liang
0
0
Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
5/24/2024
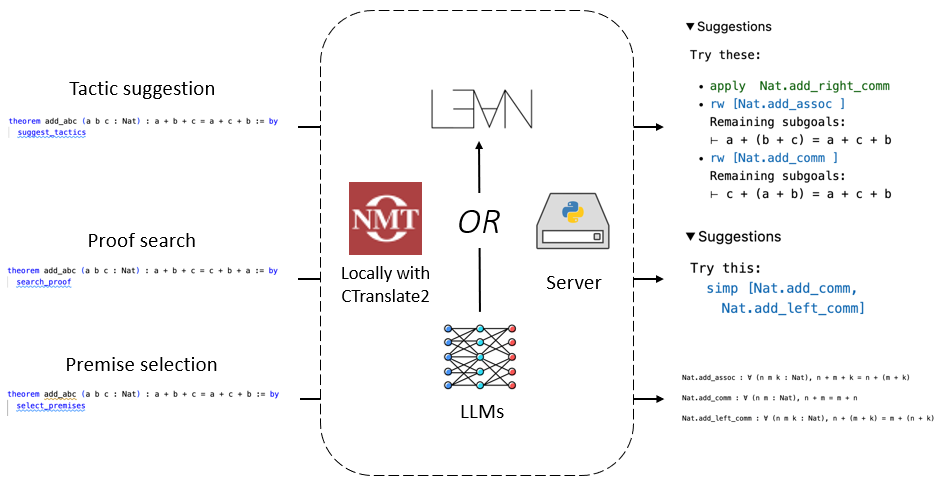
Towards Large Language Models as Copilots for Theorem Proving in Lean
Peiyang Song, Kaiyu Yang, Anima Anandkumar
0
0
Theorem proving is an important challenge for large language models (LLMs), as formal proofs can be checked rigorously by proof assistants such as Lean, leaving no room for hallucination. Existing LLM-based provers try to prove theorems in a fully autonomous mode without human intervention. In this mode, they struggle with novel and challenging theorems, for which human insights may be critical. In this paper, we explore LLMs as copilots that assist humans in proving theorems. We introduce Lean Copilot, a framework for running LLM inference in Lean. It enables programmers to build various LLM-based proof automation tools that integrate seamlessly into the workflow of Lean users. Using Lean Copilot, we build tools for suggesting proof steps (tactic suggestion), completing intermediate proof goals (proof search), and selecting relevant premises (premise selection) using LLMs. Users can use our pretrained models or bring their own ones that run either locally (with or without GPUs) or on the cloud. Experimental results demonstrate the effectiveness of our method in assisting humans and automating theorem proving process compared to existing rule-based proof automation in Lean. We open source all codes under a permissive MIT license to facilitate further research.
4/22/2024

Enhancing Formal Theorem Proving: A Comprehensive Dataset for Training AI Models on Coq Code
Andreas Florath
0
0
In the realm of formal theorem proving, the Coq proof assistant stands out for its rigorous approach to verifying mathematical assertions and software correctness. Despite the advances in artificial intelligence and machine learning, the specialized nature of Coq syntax and semantics poses unique challenges for Large Language Models (LLMs). Addressing this gap, we present a comprehensive dataset specifically designed to enhance LLMs' proficiency in interpreting and generating Coq code. This dataset, derived from a collection of over 10,000 Coq source files, encompasses a wide array of propositions, proofs, and definitions, enriched with metadata including source references and licensing information. Our primary aim is to facilitate the development of LLMs capable of generating syntactically correct and semantically meaningful Coq constructs, thereby advancing the frontier of automated theorem proving. Initial experiments with this dataset have showcased its significant potential; models trained on this data exhibited enhanced accuracy in Coq code generation. Notably, a particular experiment revealed that a fine-tuned LLM was capable of generating 141 valid proofs for a basic lemma, highlighting the dataset's utility in facilitating the discovery of diverse and valid proof strategies. This paper discusses the dataset's composition, the methodology behind its creation, and the implications of our findings for the future of machine learning in formal verification. The dataset is accessible for further research and exploration: https://huggingface.co/datasets/florath/coq-facts-props-proofs-gen0-v1
4/3/2024
🏅
Proving Theorems Recursively
Haiming Wang, Huajian Xin, Zhengying Liu, Wenda Li, Yinya Huang, Jianqiao Lu, Zhicheng Yang, Jing Tang, Jian Yin, Zhenguo Li, Xiaodan Liang
0
0
Recent advances in automated theorem proving leverages language models to explore expanded search spaces by step-by-step proof generation. However, such approaches are usually based on short-sighted heuristics (e.g., log probability or value function scores) that potentially lead to suboptimal or even distracting subgoals, preventing us from finding longer proofs. To address this challenge, we propose POETRY (PrOvE Theorems RecursivelY), which proves theorems in a recursive, level-by-level manner in the Isabelle theorem prover. Unlike previous step-by-step methods, POETRY searches for a verifiable sketch of the proof at each level and focuses on solving the current level's theorem or conjecture. Detailed proofs of intermediate conjectures within the sketch are temporarily replaced by a placeholder tactic called sorry, deferring their proofs to subsequent levels. This approach allows the theorem to be tackled incrementally by outlining the overall theorem at the first level and then solving the intermediate conjectures at deeper levels. Experiments are conducted on the miniF2F and PISA datasets and significant performance gains are observed in our POETRY approach over state-of-the-art methods. POETRY on miniF2F achieves an average proving success rate improvement of 5.1%. Moreover, we observe a substantial increase in the maximum proof length found by POETRY, from 10 to 26.
5/24/2024