Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training

0
🏋️
Sign in to get full access
Overview
- Deep learning models often excel due to their ability to leverage massive training data.
- 3D deep learning has not yet fully benefited from this, as large-scale 3D datasets are limited.
- Merging multiple 3D datasets and training a single model could be a solution, but the domain gap between datasets can lead to negative transfer and degraded performance.
- This paper introduces Point Prompt Training (PPT), a framework for synergistic multi-dataset learning in 3D representation learning.
Plain English Explanation
Deep learning models, which mimic the human brain's neural networks, have made rapid advancements in many fields. A key reason for their success is their ability to learn from massive amounts of training data. This allows them to discover complex patterns and relationships that would be difficult for humans to identify on their own.
However, the 3D deep learning field has not yet fully benefited from this advantage. This is because large-scale 3D datasets, the type of data needed to train these models effectively, are relatively scarce compared to the 2D image datasets commonly used in other deep learning applications.
One potential solution is to merge multiple available 3D datasets and use them to train a single, unified model. This could allow the model to learn from a broader range of examples and potentially achieve better performance. However, the authors note that the "domain gap" - the differences in how the various datasets are structured and labeled - can cause issues.
Specifically, the authors explain that simply combining these diverse datasets to train a single model can lead to "negative transfer," where the model's performance actually degrades compared to training on a single dataset. This is because the model may struggle to reconcile the conflicting information from the different datasets.
To address this challenge, the researchers introduce a new framework called Point Prompt Training (PPT). PPT is designed to enable synergistic learning across multiple 3D datasets, allowing the model to benefit from the combined information without suffering from negative transfer.
The key innovations in PPT include "Prompt-driven Normalization," which helps the model adapt to different datasets using domain-specific prompts, and "Language-guided Categorical Alignment," which unifies the label spaces across datasets by leveraging the relationships between the label text.
Through extensive experiments, the authors demonstrate that PPT can overcome the negative transfer issue and produce high-quality, generalizable 3D representations. Additionally, they show that using PPT as a pre-training framework can lead to state-of-the-art performance on a wide range of 3D tasks and datasets.
Technical Explanation
The paper introduces Point Prompt Training (PPT), a novel framework for enabling synergistic learning across multiple 3D point cloud datasets in the context of 3D representation learning.
One of the key challenges in 3D deep learning is the limited availability of large-scale 3D datasets, especially compared to the abundance of 2D image datasets that have fueled advancements in other deep learning domains. To address this, the authors explore the potential of merging multiple 3D datasets and training a single model to leverage the combined information.
However, the authors note that due to the large domain gap between 3D point cloud datasets, such mixed supervision can lead to negative transfer, where the model's performance actually degrades compared to training on a single dataset.
To overcome this challenge, the PPT framework incorporates two key innovations:
-
Prompt-driven Normalization: This component adapts the model to different datasets by using domain-specific prompts, which help the model learn dataset-specific nuances without being adversely affected by the domain gap.
-
Language-guided Categorical Alignment: This module unifies the label spaces across multiple datasets by leveraging the relationships between the label text, allowing the model to learn a coherent representation of the data despite the differences in how the datasets are annotated.
The authors evaluate PPT through extensive experiments, demonstrating its ability to overcome negative transfer and produce high-quality, generalizable 3D representations. When used as a pre-training framework, PPT outperforms other pre-training approaches in terms of representation quality and achieves state-of-the-art performance on a diverse range of downstream 3D tasks and datasets, spanning both indoor and outdoor scenarios.
Critical Analysis
The paper presents a well-designed and thorough study on addressing the challenge of negative transfer in multi-dataset learning for 3D deep learning. The authors acknowledge the limitations of their work, noting that while PPT can mitigate negative transfer, there may still be some performance degradation compared to training on a single, large dataset.
Additionally, the authors suggest that further research is needed to explore more advanced techniques for aligning label spaces across datasets, as the current Language-guided Categorical Alignment method may have limitations in handling complex hierarchical or compositional label structures.
Another potential area for improvement is the scalability of the PPT framework. As the number of datasets and dataset-specific prompts increases, the complexity and computational requirements of the system may grow, which could limit its practical applicability for very large-scale multi-dataset learning scenarios.
Overall, the paper makes a valuable contribution to the field of 3D deep learning by introducing a novel framework that can effectively leverage the benefits of multi-dataset training while overcoming the negative transfer issue. The techniques and insights presented in this work could serve as a foundation for future research in this important area.
Conclusion
This paper introduces Point Prompt Training (PPT), a novel framework for enabling synergistic learning across multiple 3D point cloud datasets in the context of 3D representation learning. The key innovations in PPT, including Prompt-driven Normalization and Language-guided Categorical Alignment, allow the model to overcome the negative transfer issues that can arise when combining diverse 3D datasets.
The extensive experiments conducted by the authors demonstrate that PPT can produce high-quality, generalizable 3D representations and achieve state-of-the-art performance on a wide range of downstream 3D tasks and datasets. This work represents an important step forward in addressing the challenge of limited 3D dataset availability, which has been a significant bottleneck in the rapid advancement of 3D deep learning.
The insights and techniques presented in this paper could inspire further research into more robust and scalable multi-dataset learning approaches, ultimately contributing to the continued progress of 3D deep learning and its applications in various industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, Hengshuang Zhao
The rapid advancement of deep learning models often attributes to their ability to leverage massive training data. In contrast, such privilege has not yet fully benefited 3D deep learning, mainly due to the limited availability of large-scale 3D datasets. Merging multiple available data sources and letting them collaboratively train a single model is a potential solution. However, due to the large domain gap between 3D point cloud datasets, such mixed supervision could adversely affect the model's performance and lead to degenerated performance (i.e., negative transfer) compared to single-dataset training. In view of this challenge, we introduce Point Prompt Training (PPT), a novel framework for multi-dataset synergistic learning in the context of 3D representation learning that supports multiple pre-training paradigms. Based on this framework, we propose Prompt-driven Normalization, which adapts the model to different datasets with domain-specific prompts and Language-guided Categorical Alignment that decently unifies the multiple-dataset label spaces by leveraging the relationship between label text. Extensive experiments verify that PPT can overcome the negative transfer associated with synergistic learning and produce generalizable representations. Notably, it achieves state-of-the-art performance on each dataset using a single weight-shared model with supervised multi-dataset training. Moreover, when served as a pre-training framework, it outperforms other pre-training approaches regarding representation quality and attains remarkable state-of-the-art performance across over ten diverse downstream tasks spanning both indoor and outdoor 3D scenarios.
Read more7/23/2024
0
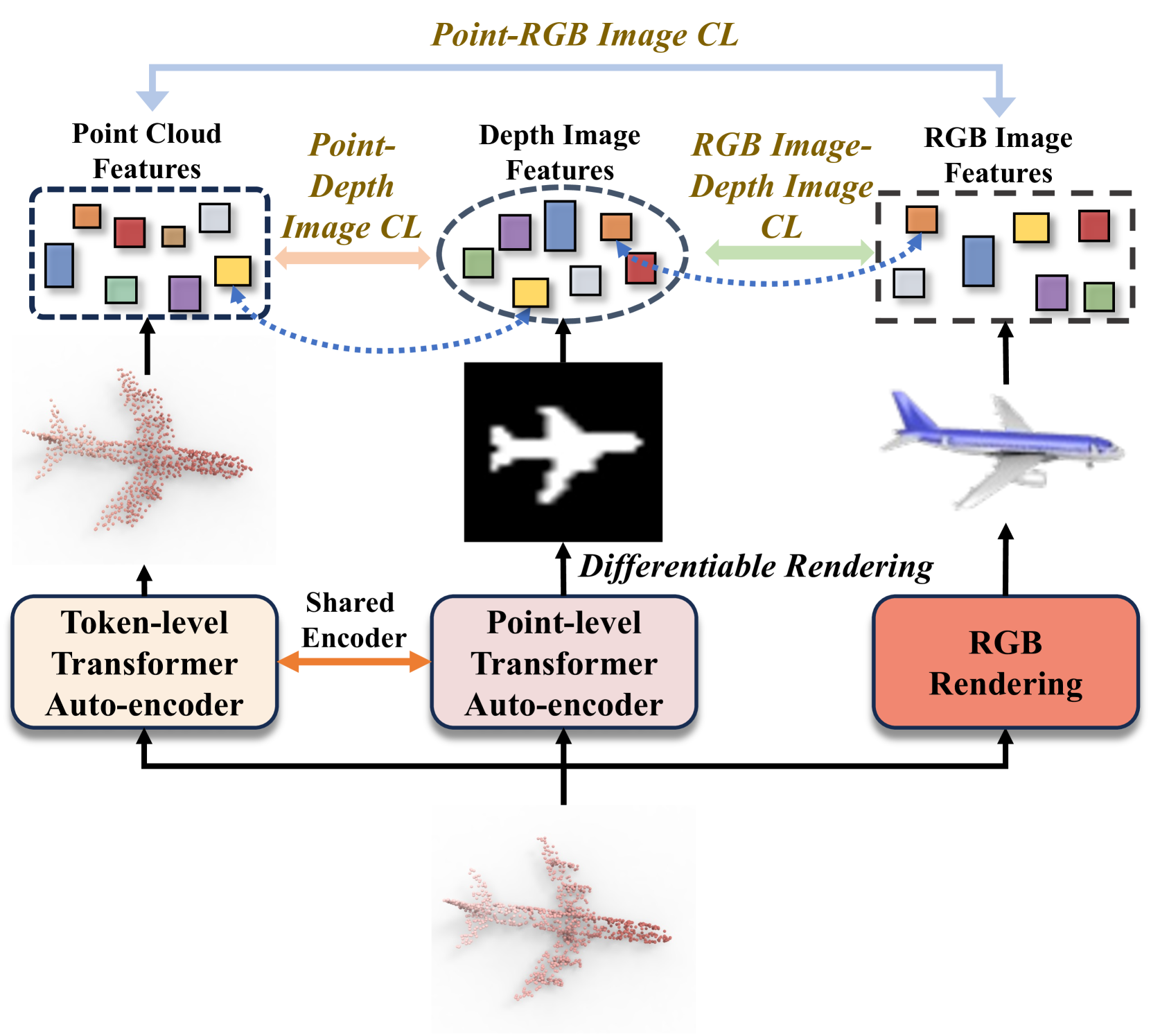
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
Read more4/23/2024
✨
0
Multi-View Representation is What You Need for Point-Cloud Pre-Training
Siming Yan, Chen Song, Youkang Kong, Qixing Huang
A promising direction for pre-training 3D point clouds is to leverage the massive amount of data in 2D, whereas the domain gap between 2D and 3D creates a fundamental challenge. This paper proposes a novel approach to point-cloud pre-training that learns 3D representations by leveraging pre-trained 2D networks. Different from the popular practice of predicting 2D features first and then obtaining 3D features through dimensionality lifting, our approach directly uses a 3D network for feature extraction. We train the 3D feature extraction network with the help of the novel 2D knowledge transfer loss, which enforces the 2D projections of the 3D feature to be consistent with the output of pre-trained 2D networks. To prevent the feature from discarding 3D signals, we introduce the multi-view consistency loss that additionally encourages the projected 2D feature representations to capture pixel-wise correspondences across different views. Such correspondences induce 3D geometry and effectively retain 3D features in the projected 2D features. Experimental results demonstrate that our pre-trained model can be successfully transferred to various downstream tasks, including 3D shape classification, part segmentation, 3D object detection, and semantic segmentation, achieving state-of-the-art performance.
Read more4/30/2024
0
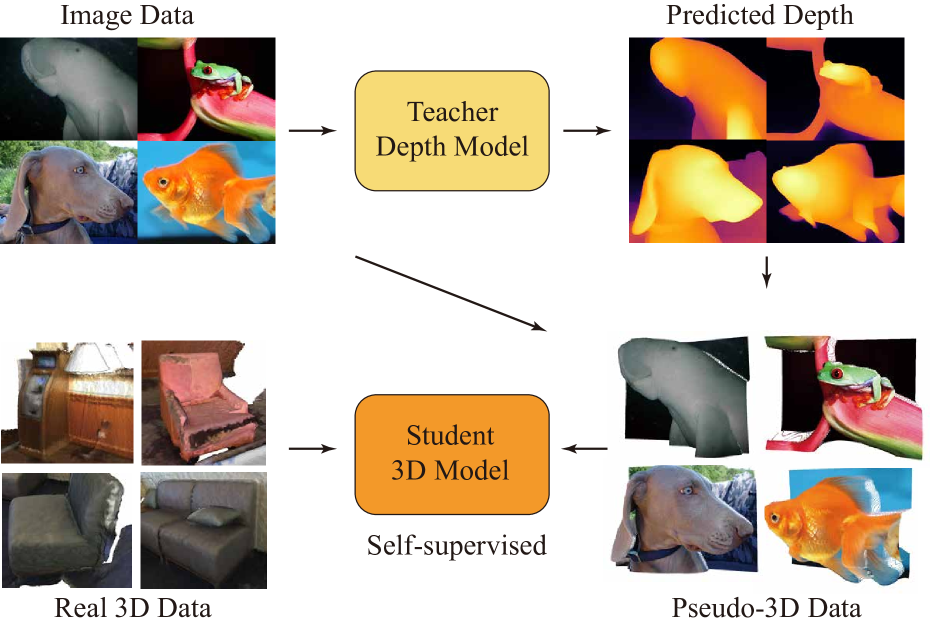
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Yong Liu, Qixing Huang, Yang Li
3D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
Read more8/20/2024