P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders

0
Sign in to get full access
Overview
- The paper proposes a novel pre-training approach called P3P (Pseudo-3D Pre-training) to scale 3D masked autoencoders for various 3D recognition tasks.
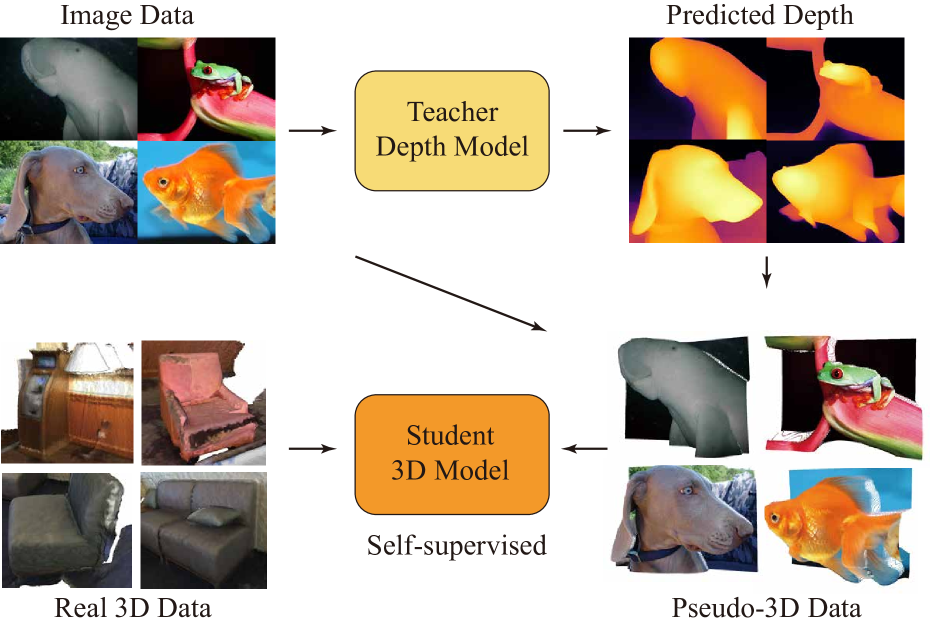
- P3P leverages 2D image data to pre-train the model, which can then be fine-tuned on 3D point cloud data.
- This approach aims to address the challenge of limited 3D training data, which has hindered the development of high-performing 3D models.
Plain English Explanation
The paper introduces a new way to train 3D machine learning models called P3P (Pseudo-3D Pre-training). The key idea is to first pre-train the model using 2D image data, which is much more abundant than 3D data. This pre-training helps the model learn useful features that can then be fine-tuned on the 3D point cloud data for specific 3D recognition tasks.
The reason this is important is that 3D data, such as point clouds, is much harder to come by compared to 2D images. By leveraging the wealth of 2D image data to pre-train the model, the researchers can overcome the challenge of limited 3D training data, which has historically hindered the development of powerful 3D models.
Technical Explanation
The paper proposes a novel pre-training approach called P3P (Pseudo-3D Pre-training) to scale 3D masked autoencoders for various 3D recognition tasks. The key innovation is to leverage abundant 2D image data to pre-train the model, which can then be fine-tuned on 3D point cloud data.
The pre-training process involves training the model to reconstruct 2D images that have been corrupted with random masking. This helps the model learn useful visual features that can then be transferred to the 3D domain during fine-tuning. The researchers show that this pseudo-3D pre-training approach outperforms directly training on limited 3D data, as well as other 3D pre-training methods.
Additionally, the paper explores the use of cross-dimensional pre-training, where the model is pre-trained on a combination of 2D and 3D data. This further improves the model's performance on 3D recognition tasks, particularly in cross-modal medical applications.
Critical Analysis
The P3P approach presented in this paper offers a promising solution to the challenge of limited 3D training data, which has hindered the development of high-performing 3D models. By leveraging the wealth of 2D image data, the researchers demonstrate that pre-training can significantly boost the performance of 3D masked autoencoders.
However, the paper does not address the potential limitations of this approach. For example, it's unclear how well the learned 2D features would transfer to 3D tasks, and whether there are any inherent biases or limitations in the 2D data that could be propagated to the 3D model.
Additionally, the paper focuses on a specific type of 3D data (point clouds) and 3D recognition tasks. It would be valuable to see how the P3P approach generalizes to other 3D modalities, such as voxels or meshes, and a wider range of 3D applications.
Overall, the P3P approach is a promising step forward in scaling 3D representation learning, but further research is needed to fully understand its limitations and generalizability.
Conclusion
The P3P (Pseudo-3D Pre-training) approach presented in this paper offers a novel solution to the challenge of limited 3D training data, which has hindered the development of high-performing 3D models. By leveraging the wealth of 2D image data to pre-train the model, the researchers demonstrate significant performance improvements on 3D recognition tasks.
This work highlights the potential of cross-dimensional pre-training, where models can learn useful features from related data modalities and then be fine-tuned on the target 3D data. As 3D data becomes increasingly important in fields like medical imaging and robotics, approaches like P3P could play a crucial role in unlocking the full potential of 3D machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Yong Liu, Qixing Huang, Yang Li
3D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
Read more8/20/2024
✨
0
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Siming Yan, Yuqi Yang, Yuxiao Guo, Hao Pan, Peng-shuai Wang, Xin Tong, Yang Liu, Qixing Huang
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Read more4/30/2024
🏋️
0
Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, Hengshuang Zhao
The rapid advancement of deep learning models often attributes to their ability to leverage massive training data. In contrast, such privilege has not yet fully benefited 3D deep learning, mainly due to the limited availability of large-scale 3D datasets. Merging multiple available data sources and letting them collaboratively train a single model is a potential solution. However, due to the large domain gap between 3D point cloud datasets, such mixed supervision could adversely affect the model's performance and lead to degenerated performance (i.e., negative transfer) compared to single-dataset training. In view of this challenge, we introduce Point Prompt Training (PPT), a novel framework for multi-dataset synergistic learning in the context of 3D representation learning that supports multiple pre-training paradigms. Based on this framework, we propose Prompt-driven Normalization, which adapts the model to different datasets with domain-specific prompts and Language-guided Categorical Alignment that decently unifies the multiple-dataset label spaces by leveraging the relationship between label text. Extensive experiments verify that PPT can overcome the negative transfer associated with synergistic learning and produce generalizable representations. Notably, it achieves state-of-the-art performance on each dataset using a single weight-shared model with supervised multi-dataset training. Moreover, when served as a pre-training framework, it outperforms other pre-training approaches regarding representation quality and attains remarkable state-of-the-art performance across over ten diverse downstream tasks spanning both indoor and outdoor 3D scenarios.
Read more7/23/2024

0
Cross-Dimensional Medical Self-Supervised Representation Learning Based on a Pseudo-3D Transformation
Fei Gao, Siwen Wang, Fandong Zhang, Hong-Yu Zhou, Yizhou Wang, Churan Wang, Gang Yu, Yizhou Yu
Medical image analysis suffers from a shortage of data, whether annotated or not. This becomes even more pronounced when it comes to 3D medical images. Self-Supervised Learning (SSL) can partially ease this situation by using unlabeled data. However, most existing SSL methods can only make use of data in a single dimensionality (e.g. 2D or 3D), and are incapable of enlarging the training dataset by using data with differing dimensionalities jointly. In this paper, we propose a new cross-dimensional SSL framework based on a pseudo-3D transformation (CDSSL-P3D), that can leverage both 2D and 3D data for joint pre-training. Specifically, we introduce an image transformation based on the im2col algorithm, which converts 2D images into a format consistent with 3D data. This transformation enables seamless integration of 2D and 3D data, and facilitates cross-dimensional self-supervised learning for 3D medical image analysis. We run extensive experiments on 13 downstream tasks, including 2D and 3D classification and segmentation. The results indicate that our CDSSL-P3D achieves superior performance, outperforming other advanced SSL methods.
Read more7/8/2024