Towards Long-Range 3D Object Detection for Autonomous Vehicles
2310.04800
0
0
🔎
Abstract
3D object detection at long range is crucial for ensuring the safety and efficiency of self driving vehicles, allowing them to accurately perceive and react to objects, obstacles, and potential hazards from a distance. But most current state of the art LiDAR based methods are range limited due to sparsity at long range, which generates a form of domain gap between points closer to and farther away from the ego vehicle. Another related problem is the label imbalance for faraway objects, which inhibits the performance of Deep Neural Networks at long range. To address the above limitations, we investigate two ways to improve long range performance of current LiDAR based 3D detectors. First, we combine two 3D detection networks, referred to as range experts, one specializing at near to mid range objects, and one at long range 3D detection. To train a detector at long range under a scarce label regime, we further weigh the loss according to the labelled point's distance from ego vehicle. Second, we augment LiDAR scans with virtual points generated using Multimodal Virtual Points (MVP), a readily available image-based depth completion algorithm. Our experiments on the long range Argoverse2 (AV2) dataset indicate that MVP is more effective in improving long range performance, while maintaining a straightforward implementation. On the other hand, the range experts offer a computationally efficient and simpler alternative, avoiding dependency on image-based segmentation networks and perfect camera-LiDAR calibration.
Create account to get full access
Overview
- Long-range 3D object detection is crucial for self-driving car safety and performance, but current LiDAR-based methods struggle at long ranges due to sparse point clouds.
- This paper explores two approaches to improve long-range 3D detection: combining "range expert" networks and augmenting LiDAR scans with virtual points generated using a depth completion algorithm.
Plain English Explanation
Self-driving cars need to be able to accurately detect and respond to objects, obstacles, and hazards from a distance to drive safely. However, current 3D detection methods based on LiDAR sensors often struggle at long ranges because the LiDAR point clouds become very sparse the farther away they are from the car.
To address this, the researchers in this paper tested two different approaches. First, they combined two separate 3D detection networks - one focused on objects close to the car, and one focused on objects farther away. This "range expert" approach allows each network to specialize in its preferred distance range.
The second approach was to take the sparse LiDAR point clouds and use a depth completion algorithm to add virtual points, effectively "filling in" the sparse areas. This helps provide the detection networks with more complete information about distant objects.
The researchers found that the depth completion approach, called "Multimodal Virtual Points" (MVP), was more effective at improving long-range performance. However, the range expert approach offers a simpler, more computationally efficient alternative that avoids relying on additional sensors like cameras.
Technical Explanation
The key innovation in this paper is the use of two complementary approaches to enhance long-range 3D object detection from LiDAR data:
-
Range Experts: The researchers trained two separate 3D detection networks, one specialized for near-to-mid range objects and one for long-range objects. This allows each "range expert" to focus on its preferred distance regime, rather than a single network having to handle the entire range. To train the long-range expert under sparse label conditions, the loss function was weighted based on the distance of labeled points from the ego vehicle.
-
Multimodal Virtual Points (MVP): To compensate for the sparsity of LiDAR points at long range, the researchers augmented the input point clouds using an image-based depth completion algorithm. This adds virtual points to fill in the gaps, providing the 3D detection network with a more complete representation of the environment.
The researchers evaluated these approaches on the long-range Argoverse2 (AV2) dataset. Their experiments showed that MVP was more effective at improving long-range performance compared to the range expert approach. However, the range expert method offers a simpler, more computationally efficient alternative that avoids dependencies on additional sensors like cameras and their calibration.
Critical Analysis
The paper presents a thorough evaluation of the two proposed approaches, considering their trade-offs in terms of performance, complexity, and computational cost. The researchers acknowledge the limitations of their work, noting that the range expert method still struggles with the inherent label imbalance problem for distant objects, and that the MVP approach relies on accurate camera-LiDAR calibration.
Additional areas for future research could include exploring more advanced techniques for handling sparse point clouds, such as leveraging temporal information or investigating novel network architectures specifically designed for long-range object detection. It would also be valuable to assess the impact of these methods on the overall safety and performance of self-driving vehicles in real-world driving scenarios.
Conclusion
This paper tackles the important challenge of improving long-range 3D object detection for self-driving cars, which is crucial for ensuring safety and efficient operation. The researchers present two complementary approaches - range experts and multimodal virtual points - that demonstrate the potential to enhance the performance of LiDAR-based 3D detectors at long ranges. While the depth completion-based MVP method shows stronger results, the simpler range expert approach offers a compelling alternative that may be more practical for real-world deployment. Overall, this work contributes valuable insights and techniques that can help advance the state of the art in autonomous vehicle perception and navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
0
0
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
4/11/2024
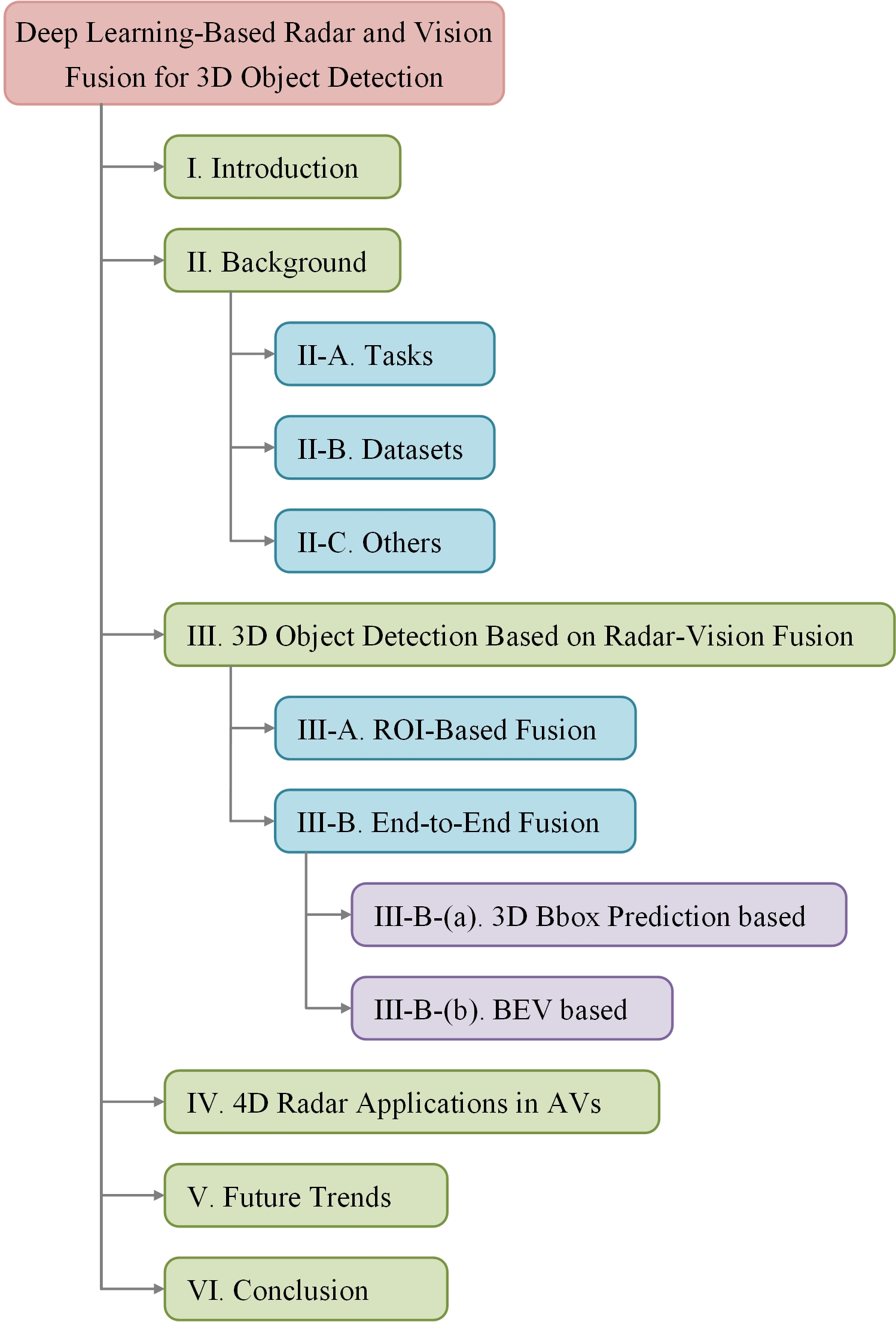
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024

Multimodal 3D Object Detection on Unseen Domains
Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Michael J. Jones, Vishal M. Patel
0
0
LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
4/19/2024

Better Monocular 3D Detectors with LiDAR from the Past
Yurong You, Cheng Perng Phoo, Carlos Andres Diaz-Ruiz, Katie Z Luo, Wei-Lun Chao, Mark Campbell, Bharath Hariharan, Kilian Q Weinberger
0
0
Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
4/11/2024