Towards Model-Agnostic Dataset Condensation by Heterogeneous Models

0

Sign in to get full access
Overview
- The paper explores a new approach to dataset condensation called "Model-Agnostic Dataset Condensation by Heterogeneous Models".
- Dataset condensation aims to create a smaller dataset that can train models as effectively as the original larger dataset.
- This paper proposes using a diverse set of models, rather than a single model, to condense the dataset in a way that is agnostic to the final model architecture.
Plain English Explanation
The researchers wanted to find a way to take a large dataset and create a much smaller version of it that would still be effective for training machine learning models. This is called "dataset condensation".
Typically, dataset condensation methods use a single model to condense the dataset. <a href="https://aimodels.fyi/papers/arxiv/calibrated-dataset-condensation-faster-hyperparameter-search">Previous research</a> has shown that this can lead to the condensed dataset only working well for models similar to the one used for condensation.
In this paper, the researchers propose using a diverse set of "heterogeneous" models, rather than just one, to condense the dataset. The idea is that by using a variety of different model types, the condensed dataset will work well for training many different types of models, not just ones similar to the condensation model.
This "model-agnostic" approach means the condensed dataset should be useful no matter what kind of machine learning model you want to train, rather than being optimized for a specific model architecture.
Technical Explanation
The key technical contributions of this paper are:
-
Heterogeneous Model Condensation: Instead of using a single model for dataset condensation, the researchers use a set of diverse "heterogeneous" models. This includes models with different architectures, such as convolutional neural networks, transformers, and more.
-
Optimization Objective: The researchers define a new optimization objective that encourages the condensed dataset to work well across the set of heterogeneous models, rather than just optimizing for a single model.
-
Experiments: The paper evaluates this model-agnostic condensation approach on several image classification benchmarks. The results show the condensed datasets work well for training a variety of different model types, outperforming previous single-model condensation methods.
Critical Analysis
The paper presents a promising new direction for dataset condensation that addresses some limitations of prior work. By using a diverse set of models, the condensed datasets become more "model-agnostic" and can be effectively used to train a wider range of architectures.
However, the paper does not explore the limits of this approach. It's unclear how the number and types of models used in the condensation process impact the final results. There may be diminishing returns or an optimal set of models to use.
Additionally, the experiments are primarily focused on image classification tasks. It would be valuable to see how well this approach generalizes to other domains, such as natural language processing or reinforcement learning.
Overall, this is an interesting and well-executed piece of research that opens up new avenues for further exploration in the field of dataset condensation.
Conclusion
This paper introduces a novel dataset condensation approach that uses a diverse set of "heterogeneous" machine learning models, rather than a single model, to create a condensed dataset that is agnostic to the final model architecture.
The key insight is that by optimizing the condensed dataset to work well across a variety of model types, it can be effectively used to train many different kinds of models, not just those similar to the condensation model. The experimental results demonstrate the benefits of this model-agnostic approach compared to prior single-model condensation methods.
This research represents an important step forward in making dataset condensation more broadly applicable and useful for a wide range of machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Model-Agnostic Dataset Condensation by Heterogeneous Models
Jun-Yeong Moon, Jung Uk Kim, Gyeong-Moon Park
Abstract. The advancement of deep learning has coincided with the proliferation of both models and available data. The surge in dataset sizes and the subsequent surge in computational requirements have led to the development of the Dataset Condensation (DC). While prior studies have delved into generating synthetic images through methods like distribution alignment and training trajectory tracking for more efficient model training, a significant challenge arises when employing these condensed images practically. Notably, these condensed images tend to be specific to particular models, constraining their versatility and practicality. In response to this limitation, we introduce a novel method, Heterogeneous Model Dataset Condensation (HMDC), designed to produce universally applicable condensed images through cross-model interactions. To address the issues of gradient magnitude difference and semantic distance in models when utilizing heterogeneous models, we propose the Gradient Balance Module (GBM) and Mutual Distillation (MD) with the SpatialSemantic Decomposition method. By balancing the contribution of each model and maintaining their semantic meaning closely, our approach overcomes the limitations associated with model-specific condensed images and enhances the broader utility. The source code is available in https://github.com/KHU-AGI/HMDC.
Read more9/24/2024

0
Calibrated Dataset Condensation for Faster Hyperparameter Search
Mucong Ding, Yuancheng Xu, Tahseen Rabbani, Xiaoyu Liu, Brian Gravelle, Teresa Ranadive, Tai-Ching Tuan, Furong Huang
Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
Read more5/29/2024
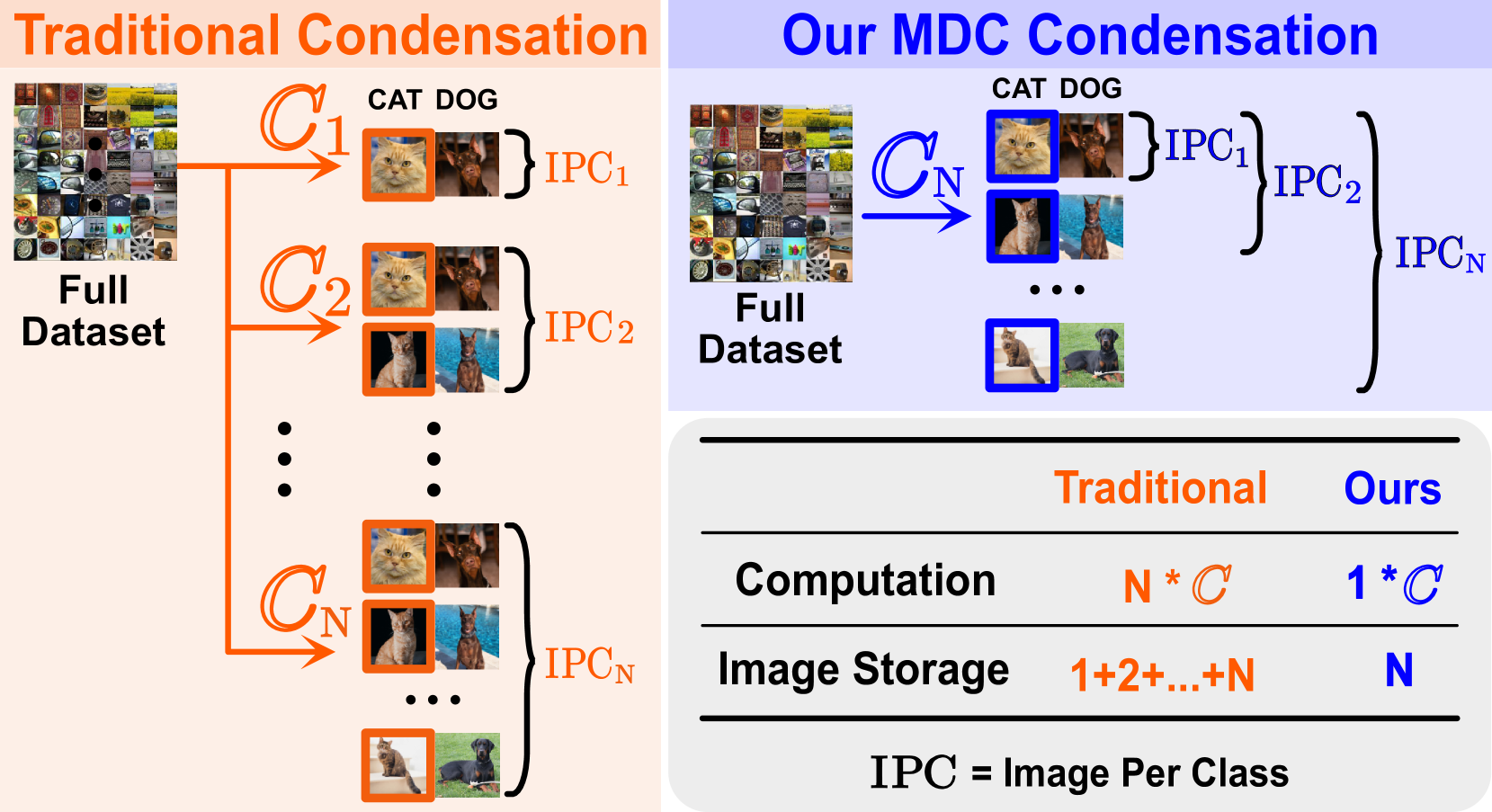
0
Multisize Dataset Condensation
Yang He, Lingao Xiao, Joey Tianyi Zhou, Ivor Tsang
While dataset condensation effectively enhances training efficiency, its application in on-device scenarios brings unique challenges. 1) Due to the fluctuating computational resources of these devices, there's a demand for a flexible dataset size that diverges from a predefined size. 2) The limited computational power on devices often prevents additional condensation operations. These two challenges connect to the subset degradation problem in traditional dataset condensation: a subset from a larger condensed dataset is often unrepresentative compared to directly condensing the whole dataset to that smaller size. In this paper, we propose Multisize Dataset Condensation (MDC) by compressing N condensation processes into a single condensation process to obtain datasets with multiple sizes. Specifically, we introduce an adaptive subset loss on top of the basic condensation loss to mitigate the subset degradation problem. Our MDC method offers several benefits: 1) No additional condensation process is required; 2) reduced storage requirement by reusing condensed images. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including SVHN, CIFAR-10, CIFAR-100 and ImageNet. For example, we achieved 5.22%-6.40% average accuracy gains on condensing CIFAR-10 to ten images per class. Code is available at: https://github.com/he-y/Multisize-Dataset-Condensation.
Read more4/16/2024

0
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Haizhong Zheng, Jiachen Sun, Shutong Wu, Bhavya Kailkhura, Zhuoqing Mao, Chaowei Xiao, Atul Prakash
Given a real-world dataset, data condensation (DC) aims to synthesize a small synthetic dataset that captures the knowledge of a natural dataset while being usable for training models with comparable accuracy. Recent works propose to enhance DC with data parameterization, which condenses data into very compact parameterized data containers instead of images. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on five public datasets and show that our proposed method outperforms all baselines.
Read more7/22/2024