Multisize Dataset Condensation
2403.06075
0
0
Abstract
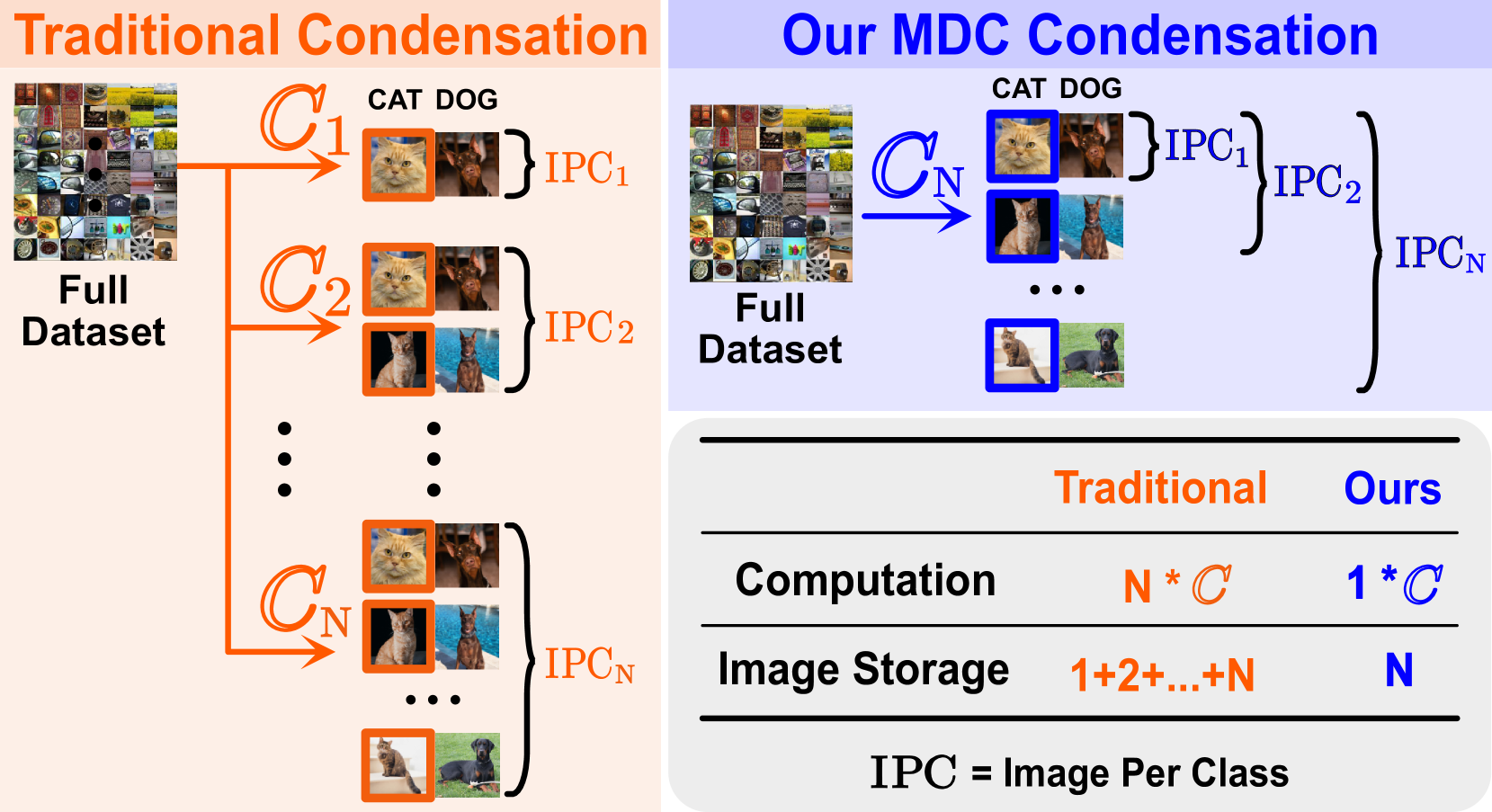
While dataset condensation effectively enhances training efficiency, its application in on-device scenarios brings unique challenges. 1) Due to the fluctuating computational resources of these devices, there's a demand for a flexible dataset size that diverges from a predefined size. 2) The limited computational power on devices often prevents additional condensation operations. These two challenges connect to the subset degradation problem in traditional dataset condensation: a subset from a larger condensed dataset is often unrepresentative compared to directly condensing the whole dataset to that smaller size. In this paper, we propose Multisize Dataset Condensation (MDC) by compressing N condensation processes into a single condensation process to obtain datasets with multiple sizes. Specifically, we introduce an adaptive subset loss on top of the basic condensation loss to mitigate the subset degradation problem. Our MDC method offers several benefits: 1) No additional condensation process is required; 2) reduced storage requirement by reusing condensed images. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including SVHN, CIFAR-10, CIFAR-100 and ImageNet. For example, we achieved 5.22%-6.40% average accuracy gains on condensing CIFAR-10 to ten images per class. Code is available at: https://github.com/he-y/Multisize-Dataset-Condensation.
Create account to get full access
Overview
- This paper introduces a novel method called "Multisize Dataset Condensation" that aims to condense large datasets into smaller versions while preserving their representational power.
- The method involves training a generative model to create a compact representation of the original dataset, which can then be used to train machine learning models effectively.
- The authors demonstrate that their approach outperforms existing dataset condensation techniques on various benchmark tasks, leading to more efficient and effective model training.
Plain English Explanation
Multisize Dataset Condensation is a technique that allows researchers and developers to take a large dataset and create a smaller, more manageable version of it. This can be useful when working with very large datasets, as it can be computationally expensive to train machine learning models on the full dataset.
The key idea behind Multisize Dataset Condensation is to use a generative model to create a compact representation of the original dataset. This generative model is trained to generate new data samples that capture the essential characteristics of the original dataset. Once this compact representation is created, it can be used to train machine learning models, often with better performance than using the full dataset.
The authors of the paper show that their Multisize Dataset Condensation approach outperforms other existing dataset condensation techniques. This means that the smaller, condensed datasets they create are more effective at training machine learning models than the condensed datasets produced by other methods.
This research is significant because it can lead to more efficient and effective machine learning model development. By being able to work with smaller, more manageable datasets, researchers and developers can save time and computational resources, while still achieving high-performing models. This could be particularly useful in domains where very large datasets are common, such as computer vision or natural language processing.
Technical Explanation
The key technical contribution of this paper is the Multisize Dataset Condensation method, which extends the dataset condensation approach to handle datasets of varying sizes.
The method works by training a generative model, such as a variational autoencoder (VAE) or a generative adversarial network (GAN), to create a compact representation of the original dataset. This generative model is trained using a novel loss function that encourages the generated samples to be representative of the original dataset, while also being diverse and non-redundant.
The authors experiment with different types of generative models and loss functions, and they find that their approach outperforms existing dataset condensation techniques on a range of benchmark tasks, including image classification and semantic segmentation.
One key aspect of the method is its ability to handle datasets of varying sizes. The authors show that their approach can effectively condense both large and small datasets, and that the resulting condensed datasets can be used to train high-performing machine learning models.
Critical Analysis
The Multisize Dataset Condensation method presented in this paper is a promising approach to efficient dataset management and model training. The authors have demonstrated its effectiveness on several benchmark tasks, and the ability to handle datasets of varying sizes is a valuable feature.
However, it's important to note that the method is not a panacea for all dataset-related challenges. The performance of the condensed datasets is still dependent on the quality and representativeness of the original dataset, and the efficacy of the generative model used to create the compact representation.
Additionally, the authors acknowledge that their method may not be suitable for every application, particularly those where the original dataset structure or semantics are crucial for model performance. In such cases, simply using the full dataset may be preferable to the condensed version.
Further research could explore ways to make the Multisize Dataset Condensation method more robust and adaptable to a wider range of use cases. Investigating the impact of different generative model architectures or loss functions, for example, could lead to improvements in the quality and diversity of the condensed datasets.
Conclusion
The Multisize Dataset Condensation method introduced in this paper represents an important step forward in the field of dataset management and efficient model training. By leveraging generative models to create compact representations of large datasets, the authors have demonstrated a way to reduce the computational burden of machine learning model development while maintaining high performance.
This research has significant implications for a wide range of applications, particularly in domains where very large datasets are common. By enabling more efficient model training, the Multisize Dataset Condensation method can help accelerate the pace of innovation and unlock new possibilities for data-driven solutions.
As with any research, there are still areas for improvement and further exploration. However, the core ideas presented in this paper offer a promising path forward for researchers and developers looking to work with large datasets more effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Elucidating the Design Space of Dataset Condensation
Shitong Shao, Zikai Zhou, Huanran Chen, Zhiqiang Shen
0
0
Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe2L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe2L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.
5/7/2024

Calibrated Dataset Condensation for Faster Hyperparameter Search
Mucong Ding, Yuancheng Xu, Tahseen Rabbani, Xiaoyu Liu, Brian Gravelle, Teresa Ranadive, Tai-Ching Tuan, Furong Huang
0
0
Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
5/29/2024
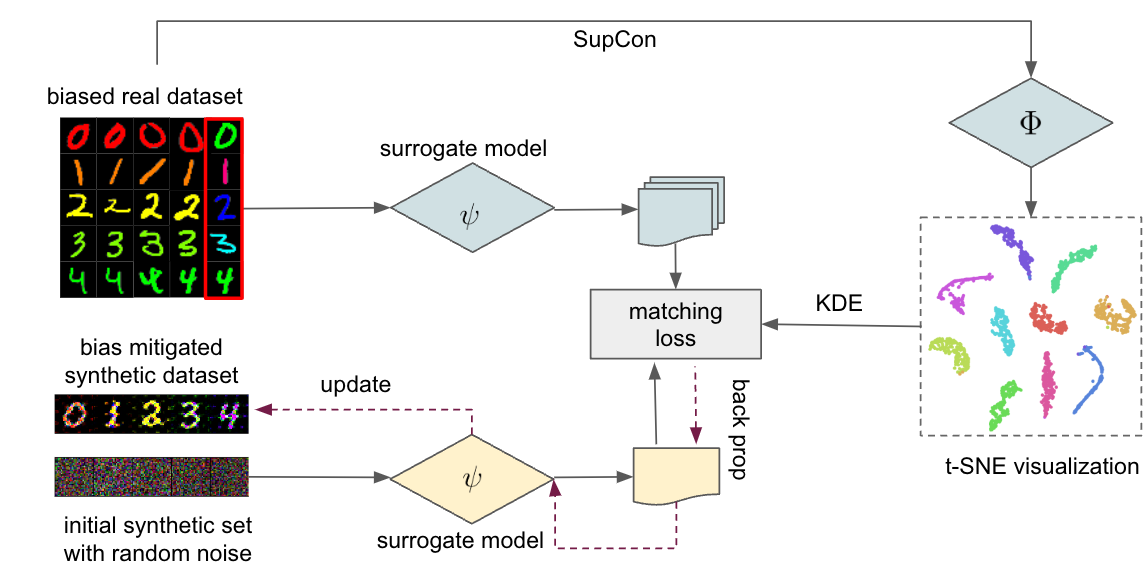
Ameliorate Spurious Correlations in Dataset Condensation
Justin Cui, Ruochen Wang, Yuanhao Xiong, Cho-Jui Hsieh
0
0
Dataset Condensation has emerged as a technique for compressing large datasets into smaller synthetic counterparts, facilitating downstream training tasks. In this paper, we study the impact of bias inside the original dataset on the performance of dataset condensation. With a comprehensive empirical evaluation on canonical datasets with color, corruption and background biases, we found that color and background biases in the original dataset will be amplified through the condensation process, resulting in a notable decline in the performance of models trained on the condensed dataset, while corruption bias is suppressed through the condensation process. To reduce bias amplification in dataset condensation, we introduce a simple yet highly effective approach based on a sample reweighting scheme utilizing kernel density estimation. Empirical results on multiple real-world and synthetic datasets demonstrate the effectiveness of the proposed method. Notably, on CMNIST with 5% bias-conflict ratio and IPC 50, our method achieves 91.5% test accuracy compared to 23.8% from vanilla DM, boosting the performance by 67.7%, whereas applying state-of-the-art debiasing method on the same dataset only achieves 53.7% accuracy. Our findings highlight the importance of addressing biases in dataset condensation and provide a promising avenue to address bias amplification in the process.
6/12/2024

Efficient and Flexible Method for Reducing Moderate-size Deep Neural Networks with Condensation
Tianyi Chen, Zhi-Qin John Xu
0
0
Neural networks have been extensively applied to a variety of tasks, achieving astounding results. Applying neural networks in the scientific field is an important research direction that is gaining increasing attention. In scientific applications, the scale of neural networks is generally moderate-size, mainly to ensure the speed of inference during application. Additionally, comparing neural networks to traditional algorithms in scientific applications is inevitable. These applications often require rapid computations, making the reduction of neural network sizes increasingly important. Existing work has found that the powerful capabilities of neural networks are primarily due to their non-linearity. Theoretical work has discovered that under strong non-linearity, neurons in the same layer tend to behave similarly, a phenomenon known as condensation. Condensation offers an opportunity to reduce the scale of neural networks to a smaller subnetwork with similar performance. In this article, we propose a condensation reduction algorithm to verify the feasibility of this idea in practical problems. Our reduction method can currently be applied to both fully connected networks and convolutional networks, achieving positive results. In complex combustion acceleration tasks, we reduced the size of the neural network to 41.7% of its original scale while maintaining prediction accuracy. In the CIFAR10 image classification task, we reduced the network size to 11.5% of the original scale, still maintaining a satisfactory validation accuracy. Our method can be applied to most trained neural networks, reducing computational pressure and improving inference speed.
5/3/2024