Towards Out-of-Distribution Detection in Vocoder Recognition via Latent Feature Reconstruction

0
Sign in to get full access
Overview
- This paper proposes a novel framework for detecting out-of-distribution (OOD) samples in vocoder recognition tasks.
- The key idea is to leverage latent feature reconstruction to identify OOD samples that cannot be well reconstructed by the model.
- The proposed approach aims to improve OOD detection performance compared to existing methods.
Plain English Explanation
Vocoder recognition is the task of analyzing and processing human speech signals. Language-Enhanced Latent Representations for Out-of-Distribution Detection, Out-of-Distribution Detection Based on Subspace Projection in High-dimensional Spaces, and Pursuing Feature Separation for Neural Collapse in Out-of-Distribution Detection have explored ways to improve the ability to detect when a given speech sample is not part of the normal distribution of data the model was trained on.
This paper takes a different approach, using "latent feature reconstruction" to identify OOD samples. The key idea is that in-distribution samples should be well-reconstructed by the model, while OOD samples will not be. By analyzing how well the model can reconstruct the latent features of a given input, the researchers can flag inputs that don't fit the normal pattern as likely OOD. This provides an additional signal beyond just classifying the input, which can help improve the model's ability to reliably detect OOD samples.
Technical Explanation
The paper proposes a framework that combines vocoder recognition with OOD detection based on latent feature reconstruction. The key components are:
-
Vocoder Recognition Model: This is a deep learning model trained to perform vocoder recognition, which involves analyzing the characteristics of human speech signals.
-
Latent Feature Reconstruction: The framework extracts the latent features from the vocoder recognition model and attempts to reconstruct them. Inputs that cannot be well reconstructed are flagged as potential OOD samples.
-
OOD Detection: By analyzing the reconstruction error, the framework can identify OOD samples that do not fit the normal distribution of the training data. This complements the vocoder recognition task.
The paper evaluates this approach on several benchmark datasets and compares it to How Good are LLMs at Out-of-Distribution Detection? and A Unified Representation Learning Framework for Textual Out-of-Distribution Detection. The results show that the proposed framework can achieve improved OOD detection performance compared to these baselines.
Critical Analysis
The paper presents a novel approach to OOD detection in vocoder recognition, but there are a few potential limitations and areas for further research:
-
Generalization to Other Domains: The evaluation is focused on vocoder recognition tasks, so it's unclear how well the proposed framework would generalize to OOD detection in other domains, such as image or text classification.
-
Computational Complexity: Reconstructing latent features may add significant computational overhead, which could impact the real-world deployment of the system. The tradeoffs between performance and efficiency should be further explored.
-
Interpretability: The paper does not provide much insight into why certain inputs are flagged as OOD. Improving the interpretability of the OOD detection process could make the system more explainable and trustworthy.
-
Robustness to Adversarial Attacks: The paper does not investigate the robustness of the proposed framework to adversarial attacks, which is an important consideration for real-world applications.
Overall, the paper presents a promising approach to OOD detection in vocoder recognition, but further research is needed to address these potential limitations and ensure the practical viability of the system.
Conclusion
This paper introduces a novel framework for detecting out-of-distribution samples in vocoder recognition tasks. By leveraging latent feature reconstruction, the proposed approach aims to improve OOD detection performance compared to existing methods. While the results are promising, there are several areas for further research, such as exploring the generalization of the framework to other domains, addressing computational complexity, improving interpretability, and investigating robustness to adversarial attacks. Overall, this work contributes to the ongoing efforts to develop more reliable and robust OOD detection systems in speech processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Out-of-Distribution Detection in Vocoder Recognition via Latent Feature Reconstruction
Renmingyue Du, Jixun Yao, Qiuqiang Kong, Yin Cao
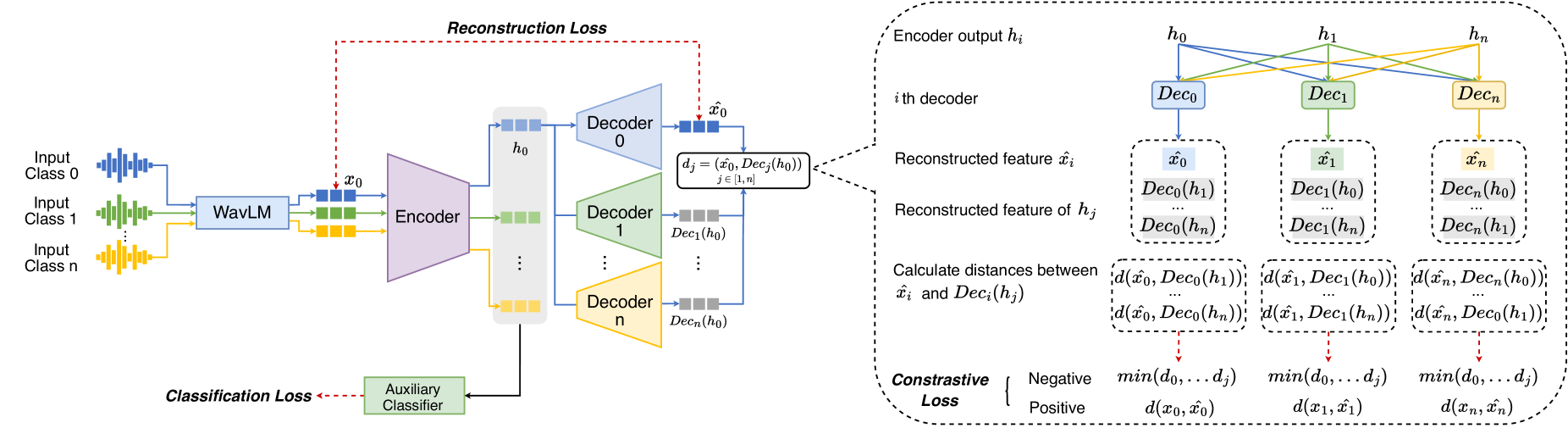
Advancements in synthesized speech have created a growing threat of impersonation, making it crucial to develop deepfake algorithm recognition. One significant aspect is out-of-distribution (OOD) detection, which has gained notable attention due to its important role in deepfake algorithm recognition. However, most of the current approaches for detecting OOD in deepfake algorithm recognition rely on probability-score or classified-distance, which may lead to limitations in the accuracy of the sample at the edge of the threshold. In this study, we propose a reconstruction-based detection approach that employs an autoencoder architecture to compress and reconstruct the acoustic feature extracted from a pre-trained WavLM model. Each acoustic feature belonging to a specific vocoder class is only aptly reconstructed by its corresponding decoder. When none of the decoders can satisfactorily reconstruct a feature, it is classified as an OOD sample. To enhance the distinctiveness of the reconstructed features by each decoder, we incorporate contrastive learning and an auxiliary classifier to further constrain the reconstructed feature. Experiments demonstrate that our proposed approach surpasses baseline systems by a relative margin of 10% in the evaluation dataset. Ablation studies further validate the effectiveness of both the contrastive constraint and the auxiliary classifier within our proposed approach.
Read more6/5/2024
0
Compressing VAE-Based Out-of-Distribution Detectors for Embedded Deployment
Aditya Bansal, Michael Yuhas, Arvind Easwaran
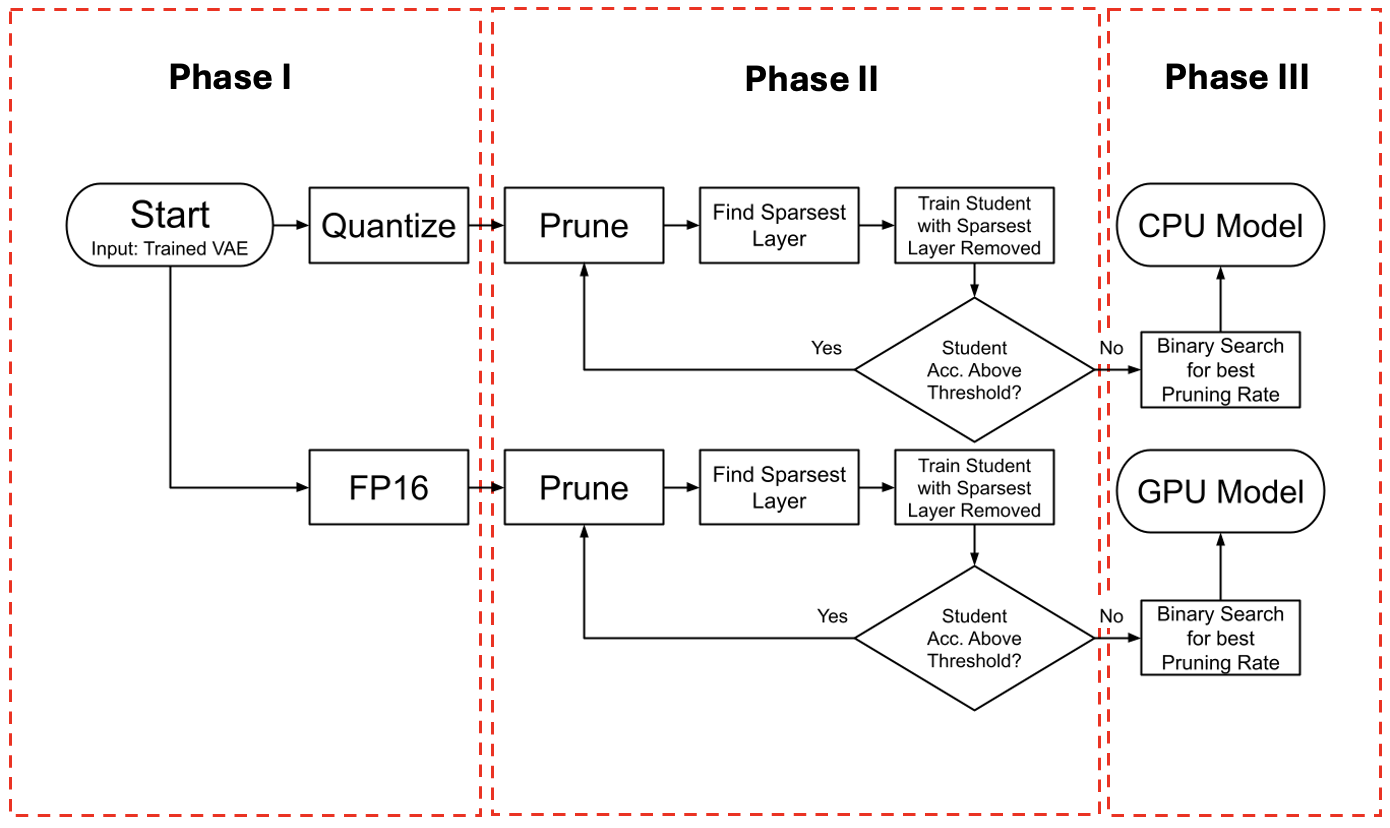
Out-of-distribution (OOD) detectors can act as safety monitors in embedded cyber-physical systems by identifying samples outside a machine learning model's training distribution to prevent potentially unsafe actions. However, OOD detectors are often implemented using deep neural networks, which makes it difficult to meet real-time deadlines on embedded systems with memory and power constraints. We consider the class of variational autoencoder (VAE) based OOD detectors where OOD detection is performed in latent space, and apply quantization, pruning, and knowledge distillation. These techniques have been explored for other deep models, but no work has considered their combined effect on latent space OOD detection. While these techniques increase the VAE's test loss, this does not correspond to a proportional decrease in OOD detection performance and we leverage this to develop lean OOD detectors capable of real-time inference on embedded CPUs and GPUs. We propose a design methodology that combines all three compression techniques and yields a significant decrease in memory and execution time while maintaining AUROC for a given OOD detector. We demonstrate this methodology with two existing OOD detectors on a Jetson Nano and reduce GPU and CPU inference time by 20% and 28% respectively while keeping AUROC within 5% of the baseline.
Read more9/4/2024

0
Language-Enhanced Latent Representations for Out-of-Distribution Detection in Autonomous Driving
Zhenjiang Mao, Dong-You Jhong, Ao Wang, Ivan Ruchkin
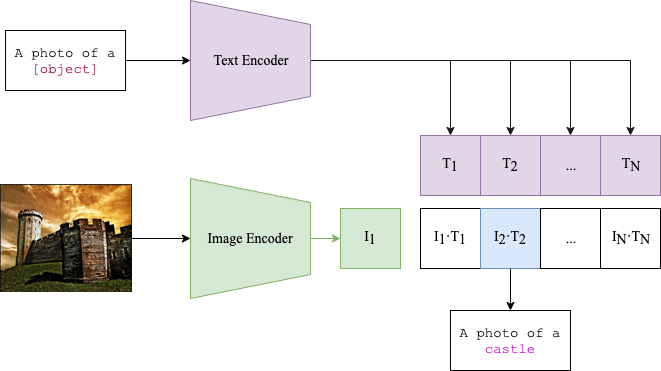
Out-of-distribution (OOD) detection is essential in autonomous driving, to determine when learning-based components encounter unexpected inputs. Traditional detectors typically use encoder models with fixed settings, thus lacking effective human interaction capabilities. With the rise of large foundation models, multimodal inputs offer the possibility of taking human language as a latent representation, thus enabling language-defined OOD detection. In this paper, we use the cosine similarity of image and text representations encoded by the multimodal model CLIP as a new representation to improve the transparency and controllability of latent encodings used for visual anomaly detection. We compare our approach with existing pre-trained encoders that can only produce latent representations that are meaningless from the user's standpoint. Our experiments on realistic driving data show that the language-based latent representation performs better than the traditional representation of the vision encoder and helps improve the detection performance when combined with standard representations.
Read more5/6/2024
0
Exploiting Diffusion Prior for Out-of-Distribution Detection
Armando Zhu, Jiabei Liu, Keqin Li, Shuying Dai, Bo Hong, Peng Zhao, Changsong Wei
Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models, especially in areas where security is critical. However, traditional OOD detection methods often fail to capture complex data distributions from large scale date. In this paper, we present a novel approach for OOD detection that leverages the generative ability of diffusion models and the powerful feature extraction capabilities of CLIP. By using these features as conditional inputs to a diffusion model, we can reconstruct the images after encoding them with CLIP. The difference between the original and reconstructed images is used as a signal for OOD identification. The practicality and scalability of our method is increased by the fact that it does not require class-specific labeled ID data, as is the case with many other methods. Extensive experiments on several benchmark datasets demonstrates the robustness and effectiveness of our method, which have significantly improved the detection accuracy.
Read more8/22/2024