Small Scale Data-Free Knowledge Distillation
2406.07876
0
0

Abstract
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
Create account to get full access
Overview
- This paper introduces a novel knowledge distillation approach called "Small Scale Data-Free Knowledge Distillation" that can effectively transfer knowledge from a large pre-trained model to a smaller model without using any external data.
- The proposed method leverages the original model's logits and attention maps to guide the training of the student model, enabling it to learn the necessary knowledge from the teacher model's internal representations.
- Experiments on various computer vision tasks demonstrate that the student model trained with this approach can achieve comparable or even better performance than the teacher model, despite its smaller size and lack of access to the original training data.
Plain English Explanation
The paper discusses a way to "shrink" a large, powerful AI model into a smaller, more efficient one without needing to use the original training data. This is called "knowledge distillation," and it's useful because smaller models can run faster and use less computing power, which is important for things like mobile apps or edge devices.
The key insight is that the smaller "student" model can learn a lot from the internal workings of the larger "teacher" model, even without access to the original training data. By studying the teacher's "logits" (its final output values) and "attention maps" (which parts of the input it focuses on), the student model can recreate much of the teacher's knowledge and capabilities. <a href="https://aimodels.fyi/papers/arxiv/improve-knowledge-distillation-via-label-revision-data">This is similar to how a student can learn from a teacher's explanations, without needing to see the original textbooks or datasets.</a>
The researchers show that this approach works well across different computer vision tasks, allowing the student model to match or even outperform the teacher, despite being much smaller. <a href="https://aimodels.fyi/papers/arxiv/ckd-contrastive-knowledge-distillation-from-sample-wise">This is an important advancement, as it means we can make powerful AI models more practical and accessible for a wider range of applications.</a>
Technical Explanation
The key innovation in this paper is the "Small Scale Data-Free Knowledge Distillation" method, which enables effective knowledge transfer from a large pre-trained model (the "teacher") to a smaller model (the "student") without using any external data.
The core idea is to leverage the teacher model's internal representations, specifically its logits (final output values) and attention maps (which parts of the input it focuses on), to guide the training of the student model. This allows the student to learn the necessary knowledge from the teacher's own decision-making process, rather than relying on the original training data.
The authors propose several loss functions to capture different aspects of the teacher's knowledge. The "logit loss" encourages the student to match the teacher's output logits, while the "attention loss" aligns the student's attention maps with the teacher's. Additionally, a "contrastive loss" is used to enhance the student's discriminative power.
Experiments are conducted on various computer vision tasks, including image classification, object detection, and semantic segmentation. The results show that the student models trained with this approach can often achieve comparable or even superior performance compared to the original teacher models, despite their smaller size and lack of access to the training data.
<a href="https://aimodels.fyi/papers/arxiv/knowledge-distillation-llm-automatic-scoring-science-education">This work builds on previous knowledge distillation techniques by demonstrating the ability to distill knowledge without any external data, which can be particularly useful when the original training data is not available or difficult to obtain.</a> <a href="https://aimodels.fyi/papers/arxiv/data-free-knowledge-distillation-fine-grained-visual">It also expands the applicability of data-free knowledge distillation to a broader range of computer vision tasks, beyond the more commonly studied image classification domain.</a>
Critical Analysis
The paper presents a compelling approach to knowledge distillation that addresses the practical challenge of transferring knowledge from large models to smaller ones without access to the original training data. The experiments demonstrate the effectiveness of the proposed method across different computer vision tasks, which is a notable strength.
However, the paper does not extensively discuss potential limitations or caveats of the approach. For example, it would be valuable to understand how the method might scale to more complex models or tasks, or how sensitive it is to the relative size and architecture differences between the teacher and student models.
<a href="https://aimodels.fyi/papers/arxiv/multi-task-multi-scale-contrastive-knowledge-distillation">Additionally, the paper could have explored the potential benefits of incorporating other knowledge distillation techniques, such as contrastive learning or multi-task distillation, to further enhance the student model's performance and generalization capabilities.</a>
Overall, the research presented in this paper represents a meaningful contribution to the field of knowledge distillation, but there are opportunities for further exploration and refinement of the proposed approach.
Conclusion
The "Small Scale Data-Free Knowledge Distillation" method introduced in this paper offers a novel and practical solution for transferring knowledge from large, pre-trained models to smaller, more efficient models without requiring access to the original training data.
The key innovation is the use of the teacher model's internal representations, such as logits and attention maps, to guide the training of the student model. This enables the student to learn the necessary knowledge and skills from the teacher, even in the absence of the original dataset.
The experimental results demonstrate the effectiveness of this approach across various computer vision tasks, showcasing the student model's ability to match or even surpass the performance of the larger teacher model. This is a significant advancement, as it paves the way for deploying powerful AI models in resource-constrained environments, such as mobile devices or edge computing systems.
Overall, this research represents an important step forward in the field of knowledge distillation, with the potential to make state-of-the-art AI models more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
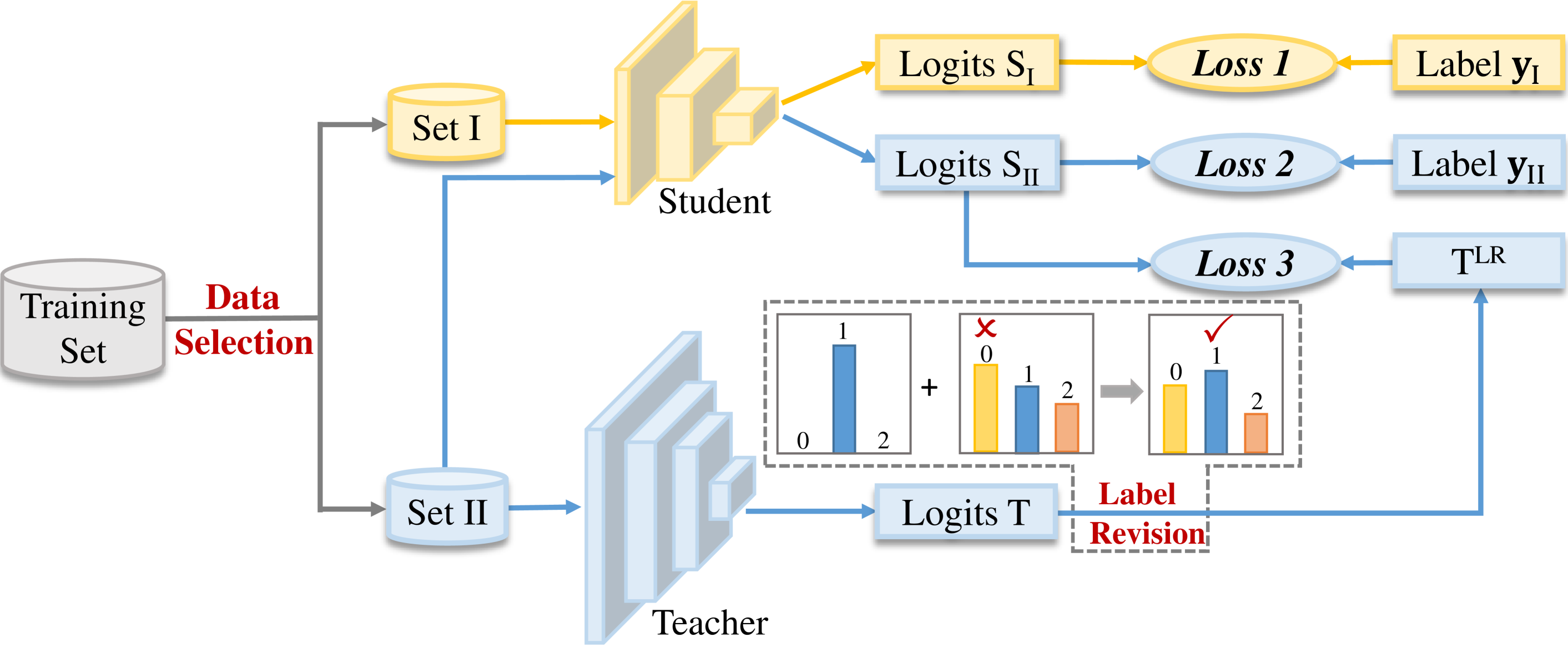
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
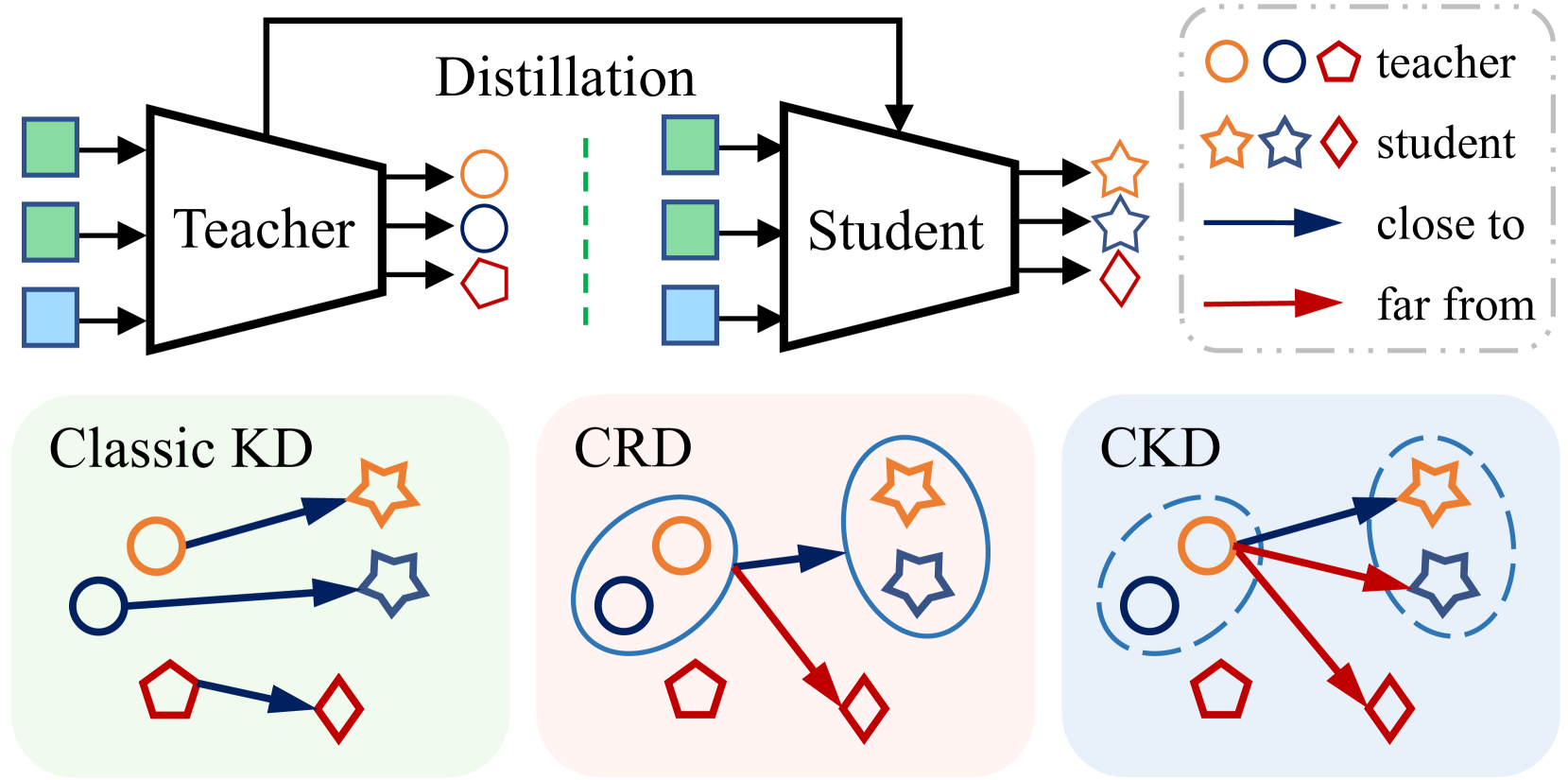
CKD: Contrastive Knowledge Distillation from A Sample-wise Perspective
Wencheng Zhu, Xin Zhou, Pengfei Zhu, Yu Wang, Qinghua Hu
0
0
In this paper, we present a simple yet effective contrastive knowledge distillation approach, which can be formulated as a sample-wise alignment problem with intra- and inter-sample constraints. Unlike traditional knowledge distillation methods that concentrate on maximizing feature similarities or preserving class-wise semantic correlations between teacher and student features, our method attempts to recover the dark knowledge by aligning sample-wise teacher and student logits. Specifically, our method first minimizes logit differences within the same sample by considering their numerical values, thus preserving intra-sample similarities. Next, we bridge semantic disparities by leveraging dissimilarities across different samples. Note that constraints on intra-sample similarities and inter-sample dissimilarities can be efficiently and effectively reformulated into a contrastive learning framework with newly designed positive and negative pairs. The positive pair consists of the teacher's and student's logits derived from an identical sample, while the negative pairs are formed by using logits from different samples. With this formulation, our method benefits from the simplicity and efficiency of contrastive learning through the optimization of InfoNCE, yielding a run-time complexity that is far less than $O(n^2)$, where $n$ represents the total number of training samples. Furthermore, our method can eliminate the need for hyperparameter tuning, particularly related to temperature parameters and large batch sizes. We conduct comprehensive experiments on three datasets including CIFAR-100, ImageNet-1K, and MS COCO. Experimental results clearly confirm the effectiveness of the proposed method on both image classification and object detection tasks. Our source codes will be publicly available at https://github.com/wencheng-zhu/CKD.
4/23/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024

Multi-Stage Balanced Distillation: Addressing Long-Tail Challenges in Sequence-Level Knowledge Distillation
Yuhang Zhou, Jing Zhu, Paiheng Xu, Xiaoyu Liu, Xiyao Wang, Danai Koutra, Wei Ai, Furong Huang
0
0
Large language models (LLMs) have significantly advanced various natural language processing tasks, but deploying them remains computationally expensive. Knowledge distillation (KD) is a promising solution, enabling the transfer of capabilities from larger teacher LLMs to more compact student models. Particularly, sequence-level KD, which distills rationale-based reasoning processes instead of merely final outcomes, shows great potential in enhancing students' reasoning capabilities. However, current methods struggle with sequence level KD under long-tailed data distributions, adversely affecting generalization on sparsely represented domains. We introduce the Multi-Stage Balanced Distillation (BalDistill) framework, which iteratively balances training data within a fixed computational budget. By dynamically selecting representative head domain examples and synthesizing tail domain examples, BalDistill achieves state-of-the-art performance across diverse long-tailed datasets, enhancing both the efficiency and efficacy of the distilled models.
6/21/2024