Auto-Encoding Morph-Tokens for Multimodal LLM
2405.01926
0
0
🚀
Abstract
For multimodal LLMs, the synergy of visual comprehension (textual output) and generation (visual output) presents an ongoing challenge. This is due to a conflicting objective: for comprehension, an MLLM needs to abstract the visuals; for generation, it needs to preserve the visuals as much as possible. Thus, the objective is a dilemma for visual-tokens. To resolve the conflict, we propose encoding images into morph-tokens to serve a dual purpose: for comprehension, they act as visual prompts instructing MLLM to generate texts; for generation, they take on a different, non-conflicting role as complete visual-tokens for image reconstruction, where the missing visual cues are recovered by the MLLM. Extensive experiments show that morph-tokens can achieve a new SOTA for multimodal comprehension and generation simultaneously. Our project is available at https://github.com/DCDmllm/MorphTokens.
Create account to get full access
Overview
- Multimodal large language models (MMLLMs) face a challenge in balancing visual comprehension (text generation) and visual generation (image reconstruction)
- This is due to a conflicting objective: for comprehension, the MLLM needs to abstract the visuals, but for generation, it needs to preserve the visuals as much as possible
- The paper proposes a solution using "morph-tokens" to resolve this conflict and achieve state-of-the-art performance in both comprehension and generation
Plain English Explanation
Multimodal large language models (MMLLMs) can understand and generate both text and images. However, these two capabilities can sometimes work against each other. When trying to comprehend an image, the MLLM needs to simplify or "abstract" the visual information to understand it and generate relevant text. But when generating an image, the MLLM needs to preserve as much of the original visual detail as possible.
This creates a dilemma for the MLLM - it has to choose between abstracting the visuals for comprehension or preserving them for generation. To solve this problem, the researchers introduced a new type of "morph-token" that can serve both purposes.
For comprehension, the morph-tokens act as visual prompts that instruct the MLLM to generate relevant text. But for generation, the morph-tokens can take on a different role, providing complete visual information for the MLLM to reconstruct the image, without the conflicting objectives.
Through extensive experiments, the researchers show that this morph-token approach allows the MLLM to achieve state-of-the-art performance in both visual comprehension (text generation) and visual generation (image reconstruction) simultaneously. This represents an important advance in making MMLLMs more effective and balanced in their multimodal capabilities.
Technical Explanation
The key insight of this paper is the use of "morph-tokens" to resolve the conflicting objectives between visual comprehension and visual generation in multimodal large language models (MMLLMs).
Typically, for visual comprehension, an MLLM needs to abstract or simplify the visual information in order to generate relevant text. But for visual generation, the MLLM needs to preserve as much of the original visual detail as possible. This creates a dilemma, as the MLLM has to choose between these two conflicting goals.
To address this, the researchers propose encoding images into morph-tokens, which can serve a dual purpose. For comprehension, the morph-tokens act as visual prompts that instruct the MLLM to generate relevant text. But for generation, the morph-tokens take on a different role, serving as complete visual-tokens that the MLLM can use to reconstruct the original image, without the conflicting objectives.
Through extensive experiments, the researchers demonstrate that this morph-token approach allows MMLLMs to achieve state-of-the-art performance in both visual comprehension (text generation) and visual generation (image reconstruction) simultaneously. This represents a significant advance in the field of multimodal language models and paves the way for more balanced and effective large multimodal language models in the future.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. For example, they note that the morph-token approach may not be as effective for highly complex or abstract visual information, and that further work is needed to improve the overall visual quality of the generated images.
Additionally, the paper does not address potential issues around the interpretability or explainability of the morph-token mechanism. It would be valuable to better understand how the MLLM is able to utilize these tokens for both comprehension and generation, and whether there are any biases or inconsistencies in the model's behavior.
Another area for further research could be exploring the trade-offs between model size, efficiency, and performance when incorporating morph-tokens into larger multimodal language models. It's possible that the benefits of this approach may be limited by the overall complexity and computational requirements of the model.
Overall, the morph-token approach represents an important step forward in addressing the challenges of multimodal language models, but more research will be needed to fully realize its potential and address any remaining limitations.
Conclusion
This paper proposes a novel solution to the challenge of balancing visual comprehension and visual generation in multimodal large language models (MMLLMs). By introducing "morph-tokens" that can serve a dual purpose, the researchers have developed a way for MMLLMs to achieve state-of-the-art performance in both text generation (from images) and image reconstruction.
This represents a significant advance in the field of multimodal language models, as it paves the way for more effective and balanced MMLLMs that can seamlessly integrate both text and visual information. While there are still some limitations and areas for further research, this work demonstrates the potential for innovative approaches to overcome the inherent trade-offs in multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Matryoshka Multimodal Models
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
0
0
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
5/28/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024

Morphing Tokens Draw Strong Masked Image Models
Taekyung Kim, Byeongho Heo, Dongyoon Han
0
0
Masked image modeling (MIM) is a promising option for training Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked token predictions, with targets tokenized from images or generated by pre-trained models such as vision-language models. While tokenizers or pre-trained models are plausible MIM targets, they often offer spatially inconsistent targets even for neighboring tokens, complicating models to learn unified discriminative representations. Our pilot study confirms that addressing spatial inconsistencies has the potential to enhance representation quality. Motivated by the findings, we introduce a novel self-supervision signal called Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens to yield contextualized targets. DTM is compatible with various SSL frameworks; we showcase an improved MIM by employing DTM, barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K demonstrate the superiority of our methods compared with state-of-the-art, complex MIM methods. Furthermore, the comparative evaluation of the iNaturalists and fine-grained visual classification datasets further validates the transferability of our method on various downstream tasks. Code is available at https://github.com/naver-ai/dtm
5/3/2024
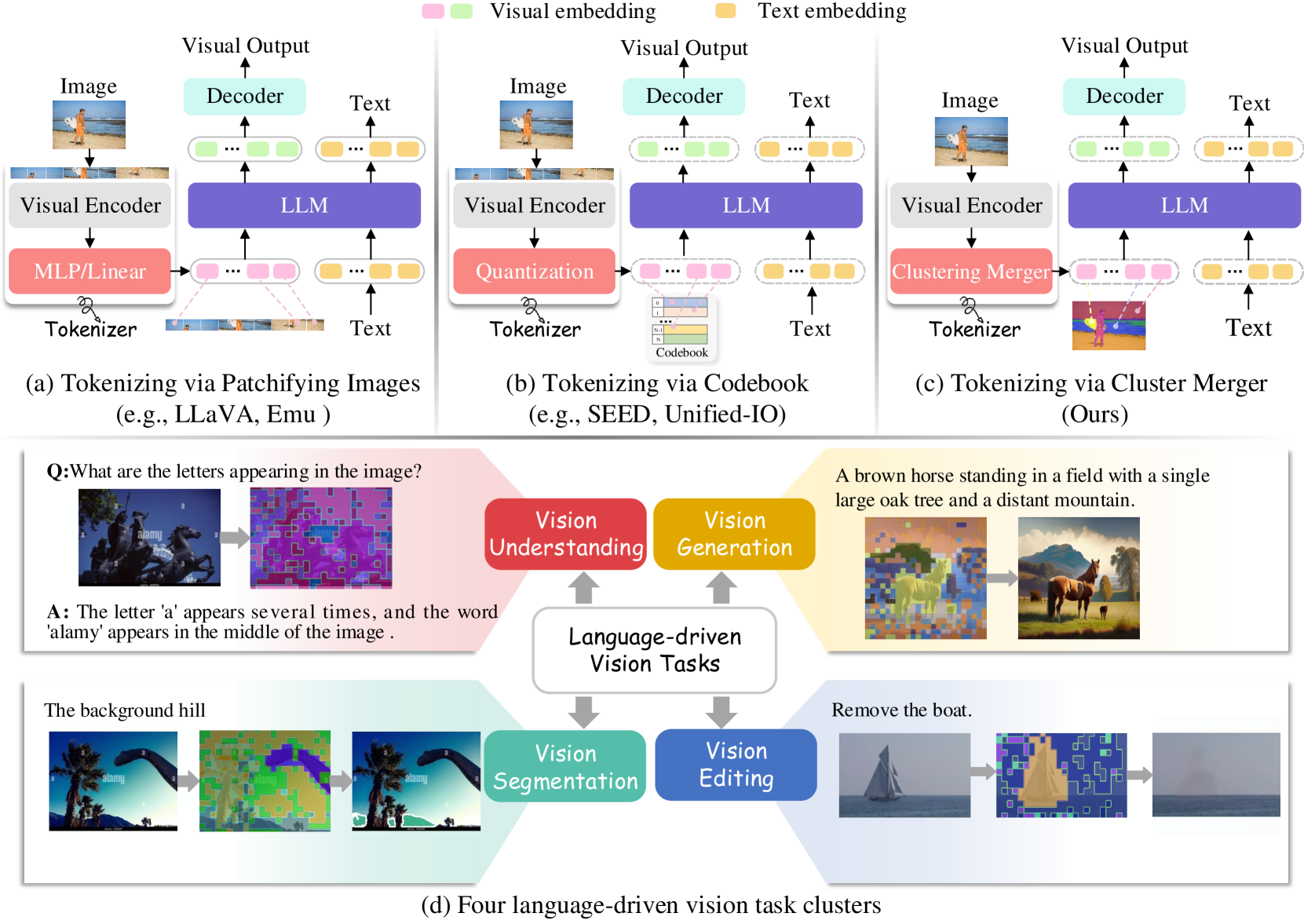
Towards Semantic Equivalence of Tokenization in Multimodal LLM
Shengqiong Wu, Hao Fei, Xiangtai Li, Jiayi Ji, Hanwang Zhang, Tat-Seng Chua, Shuicheng Yan
0
0
Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in processing vision-language tasks. One of the crux of MLLMs lies in vision tokenization, which involves efficiently transforming input visual signals into feature representations that are most beneficial for LLMs. However, existing vision tokenizers, essential for semantic alignment between vision and language, remain problematic. Existing methods aggressively fragment visual input, corrupting the visual semantic integrity. To address this, this paper proposes a novel dynamic Semantic-Equivalent Vision Tokenizer (SeTok), which groups visual features into semantic units via a dynamic clustering algorithm, flexibly determining the number of tokens based on image complexity. The resulting vision tokens effectively preserve semantic integrity and capture both low-frequency and high-frequency visual features. The proposed MLLM (Setokim) equipped with SeTok significantly demonstrates superior performance across various tasks, as evidenced by our experimental results. The project page is at https://chocowu.github.io/SeTok-web/.
6/28/2024