Towards Socially and Morally Aware RL agent: Reward Design With LLM
2401.12459
0
0

Abstract
When we design and deploy an Reinforcement Learning (RL) agent, reward functions motivates agents to achieve an objective. An incorrect or incomplete specification of the objective can result in behavior that does not align with human values - failing to adhere with social and moral norms that are ambiguous and context dependent, and cause undesired outcomes such as negative side effects and exploration that is unsafe. Previous work have manually defined reward functions to avoid negative side effects, use human oversight for safe exploration, or use foundation models as planning tools. This work studies the ability of leveraging Large Language Models (LLM)' understanding of morality and social norms on safe exploration augmented RL methods. This work evaluates language model's result against human feedbacks and demonstrates language model's capability as direct reward signals.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) to design rewards for reinforcement learning (RL) agents, with the goal of developing socially and morally aware AI systems.
- The researchers investigate how LLMs can be leveraged to imbue RL agents with a sense of ethics and prosocial behavior, moving beyond traditional reward shaping approaches.
- The paper presents experiments evaluating the ability of LLM-based reward design to guide RL agents towards desirable behaviors in complex scenarios.
Plain English Explanation
The researchers in this paper are working on creating AI systems that don't just try to maximize a specific reward, but also have a sense of ethics and social awareness. They're using large language models (LLMs) - powerful AI systems that can understand and generate human language - to help design the reward systems for reinforcement learning (RL) agents.
RL agents are a type of AI that learn by trial and error, getting rewards or punishments based on their actions. Traditionally, designing the right rewards for RL agents has been challenging, as it's hard to capture all the nuances of what we consider "good" or "ethical" behavior.
The researchers think LLMs could be the key to solving this problem. By tapping into the rich knowledge and language understanding of LLMs, they can create more sophisticated reward systems that guide the RL agents towards behaviors that are not just effective, but also socially and morally responsible.
For example, an RL agent tasked with navigating a city might be rewarded not just for reaching its destination quickly, but also for being courteous to others, following traffic laws, and avoiding harm. The LLM-based reward system would encode these broader ethical considerations, shaping the agent's behavior in a way that aligns with human values.
The paper presents experiments where the researchers test this approach, evaluating how well the LLM-powered RL agents perform compared to traditional reward shaping techniques. The goal is to show that this approach can lead to the development of AI systems that are not only capable, but also socially and morally aware.
Technical Explanation
The paper presents a novel approach to reward design for reinforcement learning (RL) agents, leveraging the capabilities of large language models (LLMs) to imbue the agents with a sense of social and moral awareness.
The researchers propose a framework where an LLM is used to evaluate the desirability of an RL agent's actions, with the LLM's assessment then being used to shape the reward signal provided to the agent. This allows the researchers to integrate contextual understanding and ethical considerations into the reward design process, going beyond traditional reward shaping approaches.
The paper presents several experiments that evaluate the efficacy of this LLM-based reward design approach. The researchers test the RL agents' performance on a range of tasks, including navigation, resource allocation, and social interaction scenarios, and compare the results to those obtained using more conventional reward shaping techniques.
The results suggest that the LLM-powered RL agents are able to learn policies that better align with human values and social norms, while still achieving high levels of task performance. The researchers attribute this to the LLM's ability to reason about the broader implications of the agents' actions and to coordinate with other agents in a socially aware manner.
Critical Analysis
The paper presents a promising approach to the challenge of reward design for RL agents, but it also acknowledges several limitations and areas for further research.
One key limitation is the reliance on the LLM's ability to accurately assess the desirability of the agents' actions. The researchers note that the LLM's evaluations may be biased or inconsistent, and that more work is needed to ensure the LLM's assessments are reliable and aligned with human values.
Additionally, the experiments in the paper are relatively confined to simulated environments, and it's unclear how well the LLM-based reward design would scale to real-world, open-ended scenarios with greater complexity and uncertainty. Further research is needed to explore the robustness and generalization of this approach in more challenging settings.
Another potential issue is the computational and data-intensive nature of the LLM-based reward design process, which may limit its practical applicability, especially for resource-constrained systems. The researchers acknowledge the need to optimize the integration of LLMs with RL agents to improve efficiency and scalability.
Despite these limitations, the paper's overall approach is a thoughtful and innovative step towards the development of socially and morally aware AI systems. The researchers' efforts to leverage LLMs to guide RL agents towards desirable behaviors have the potential to contribute to the ongoing quest for AI that is not only capable, but also aligned with human values and ethical principles.
Conclusion
This paper explores a novel approach to reward design for reinforcement learning (RL) agents, leveraging the capabilities of large language models (LLMs) to imbue the agents with a sense of social and moral awareness.
The researchers' experiments suggest that LLM-based reward design can lead to RL agents that learn policies that better align with human values and social norms, while still achieving high levels of task performance. This is a promising step towards the development of AI systems that are not only effective, but also socially and ethically responsible.
However, the paper also acknowledges several limitations and areas for further research, such as ensuring the reliability and alignment of the LLM's assessments, scaling the approach to more complex real-world scenarios, and improving the computational efficiency of the LLM-RL integration.
Overall, this work represents an important contribution to the growing field of socially and morally aware AI, highlighting the potential of leveraging language models to shape the behavior of reinforcement learning agents in ways that are more attuned to human values and social considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
0
0
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
5/17/2024
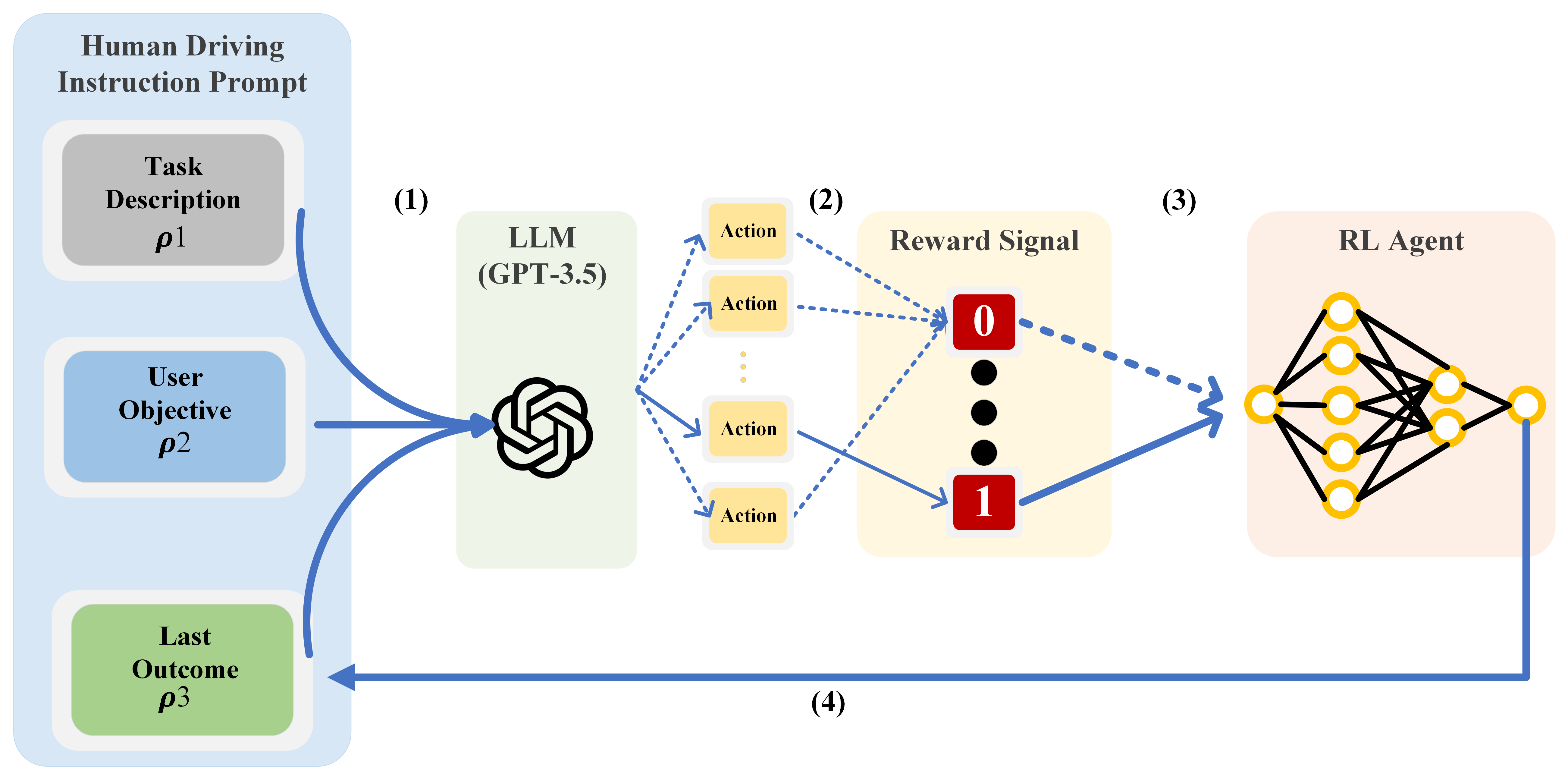
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
0
0
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
5/8/2024
↗️
Learning Machine Morality through Experience and Interaction
Elizaveta Tennant, Stephen Hailes, Mirco Musolesi
0
0
Increasing interest in ensuring safety of next-generation Artificial Intelligence (AI) systems calls for novel approaches to embedding morality into autonomous agents. Traditionally, this has been done by imposing explicit top-down rules or hard constraints on systems, for example by filtering system outputs through pre-defined ethical rules. Recently, instead, entirely bottom-up methods for learning implicit preferences from human behavior have become increasingly popular, such as those for training and fine-tuning Large Language Models. In this paper, we provide a systematization of existing approaches to the problem of introducing morality in machines - modeled as a continuum, and argue that the majority of popular techniques lie at the extremes - either being fully hard-coded, or entirely learned, where no explicit statement of any moral principle is required. Given the relative strengths and weaknesses of each type of methodology, we argue that more hybrid solutions are needed to create adaptable and robust, yet more controllable and interpretable agents. In particular, we present three case studies of recent works which use learning from experience (i.e., Reinforcement Learning) to explicitly provide moral principles to learning agents - either as intrinsic rewards, moral logical constraints or textual principles for language models. For example, using intrinsic rewards in Social Dilemma games, we demonstrate how it is possible to represent classical moral frameworks for agents. We also present an overview of the existing work in this area in order to provide empirical evidence for the potential of this hybrid approach. We then discuss strategies for evaluating the effectiveness of moral learning agents. Finally, we present open research questions and implications for the future of AI safety and ethics which are emerging from this framework.
4/22/2024

Beyond Human Preferences: Exploring Reinforcement Learning Trajectory Evaluation and Improvement through LLMs
Zichao Shen, Tianchen Zhu, Qingyun Sun, Shiqi Gao, Jianxin Li
0
0
Reinforcement learning (RL) faces challenges in evaluating policy trajectories within intricate game tasks due to the difficulty in designing comprehensive and precise reward functions. This inherent difficulty curtails the broader application of RL within game environments characterized by diverse constraints. Preference-based reinforcement learning (PbRL) presents a pioneering framework that capitalizes on human preferences as pivotal reward signals, thereby circumventing the need for meticulous reward engineering. However, obtaining preference data from human experts is costly and inefficient, especially under conditions marked by complex constraints. To tackle this challenge, we propose a LLM-enabled automatic preference generation framework named LLM4PG , which harnesses the capabilities of large language models (LLMs) to abstract trajectories, rank preferences, and reconstruct reward functions to optimize conditioned policies. Experiments on tasks with complex language constraints demonstrated the effectiveness of our LLM-enabled reward functions, accelerating RL convergence and overcoming stagnation caused by slow or absent progress under original reward structures. This approach mitigates the reliance on specialized human knowledge and demonstrates the potential of LLMs to enhance RL's effectiveness in complex environments in the wild.
7/2/2024