Towards Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation: An Empirical Study

0

Sign in to get full access
Overview
- This paper presents an empirical study on testing and evaluating vision-language-action models for robotic manipulation tasks.
- The goal is to better understand the robustness and limitations of these models in real-world scenarios.
- The study involves experiments with various vision-language-action models on a range of robotic manipulation tasks.
Plain English Explanation
The paper explores vision-language-action models, which are AI systems that can perceive the world through vision, understand language, and take physical actions. These models are particularly interesting for robotics, as they could allow robots to follow complex instructions and interact with the world in more natural ways.
The researchers conducted a series of experiments to test the performance and robustness of these models on different robotic manipulation tasks. They wanted to see how well the models could handle real-world challenges like changes in the environment, ambiguous language, and unexpected situations.
By studying the strengths and weaknesses of these vision-language-action models, the researchers hope to provide insights that can help improve their design and deployment in real-world robotic applications. This could ultimately lead to more capable and reliable robots that can better assist humans in a variety of tasks.
Technical Explanation
The paper investigates the performance and robustness of vision-language-action models for robotic manipulation tasks. These models integrate computer vision, natural language processing, and robotic control to allow robots to understand and follow instructions in natural language.
The researchers designed a series of experiments to test the models' abilities in different scenarios, such as:
- Handling changes in the environment (e.g., object positions, lighting conditions)
- Interpreting ambiguous or complex language instructions
- Responding to unexpected events or perturbations during manipulation
The experiments were conducted on various robotic manipulation tasks, such as object picking, placing, and arranging. The researchers evaluated the models' success rates, execution times, and other metrics to assess their overall performance and robustness.
The results of the study provide insights into the strengths and limitations of current vision-language-action models. The researchers found that while the models can generally perform well on basic manipulation tasks, they struggle with more complex or challenging scenarios that require deeper understanding of language and the environment.
Critical Analysis
The paper provides a valuable empirical evaluation of vision-language-action models for robotic manipulation, highlighting both the potential and the limitations of these systems. The authors acknowledge several caveats and areas for further research:
- The experiments were conducted in simulated environments, which may not fully capture the complexity of real-world scenarios. Testing the models on physical robots in the real world could yield different results.
- The study focused on a limited set of robotic manipulation tasks and language instructions. Expanding the scope to a wider range of tasks and more diverse language use cases could reveal additional insights.
- The paper does not provide a comprehensive comparison of different vision-language-action model architectures or training approaches. Exploring a broader set of models could lead to a more holistic understanding of the state of the art.
Additionally, the paper does not delve into the potential ethical or societal implications of these technologies. As vision-language-action models become more advanced and deployed in real-world applications, it will be crucial to consider their impact on issues such as job displacement, human-robot interaction, and algorithmic bias.
Conclusion
This empirical study on vision-language-action models for robotic manipulation provides valuable insights into the current capabilities and limitations of these systems. The findings suggest that while these models show promise for enabling more natural and intuitive human-robot interaction, there is still significant work to be done to improve their robustness and generalization abilities.
The insights from this research can inform the development of more advanced and reliable vision-language-action models, ultimately leading to a new generation of robots that can better assist and collaborate with humans in a wide range of tasks and environments. However, it is important to continue exploring the ethical and societal implications of these technologies as they advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation: An Empirical Study
Zhijie Wang, Zhehua Zhou, Jiayang Song, Yuheng Huang, Zhan Shu, Lei Ma
Multi-modal foundation models and generative AI have demonstrated promising capabilities in applications across various domains. Recently, Vision-language-action (VLA) models have attracted much attention regarding their potential to advance robotic manipulation. Despite the end-to-end perception-control loop offered by the VLA models, there is a lack of comprehensive understanding of the capabilities of such models and an automated testing platform to reveal their robustness and reliability across different robotic manipulation scenarios. To address these challenges, in this work, we present VLATest, a testing framework that automatically generates diverse robotic manipulation scenes to assess the performance of VLA models from various perspectives. Large-scale experiments are considered, including eight VLA models, four types of manipulation tasks, and over 18,604 testing scenes. The experimental results show that existing VAL models still lack imperative robustness for practical applications. Specifically, the performance of VLA models can be significantly affected by several factors from the operation environments, such as camera poses, lighting conditions, and unseen objects. Our framework and the insights derived from the study are expected to pave the way for more advanced and reliable VLA-enabled robotic manipulation systems in practice.
Read more9/20/2024

0
TinyVLA: Towards Fast, Data-Efficient Vision-Language-Action Models for Robotic Manipulation
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, Jian Tang
Vision-Language-Action (VLA) models have shown remarkable potential in visuomotor control and instruction comprehension through end-to-end learning processes. However, current VLA models face significant challenges: they are slow during inference and require extensive pre-training on large amounts of robotic data, making real-world deployment difficult. In this paper, we introduce a new family of compact vision-language-action models, called TinyVLA, which offers two key advantages over existing VLA models: (1) faster inference speeds, and (2) improved data efficiency, eliminating the need for pre-training stage. Our framework incorporates two essential components to build TinyVLA: (1) initializing the policy backbone with robust, high-speed multimodal models, and (2) integrating a diffusion policy decoder during fine-tuning to enable precise robot actions. We conducted extensive evaluations of TinyVLA in both simulation and on real robots, demonstrating that our approach significantly outperforms the state-of-the-art VLA model, OpenVLA, in terms of speed and data efficiency, while delivering comparable or superior performance. Additionally, TinyVLA exhibits strong generalization capabilities across various dimensions, including language instructions, novel objects, unseen positions, changes in object appearance, background variations, and environmental shifts, often matching or exceeding the performance of OpenVLA. We believe that methodname offers an interesting perspective on utilizing pre-trained multimodal models for policy learning. Our project is at https://tiny-vla.github.io.
Read more9/30/2024
🤖
0
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
Read more5/24/2024
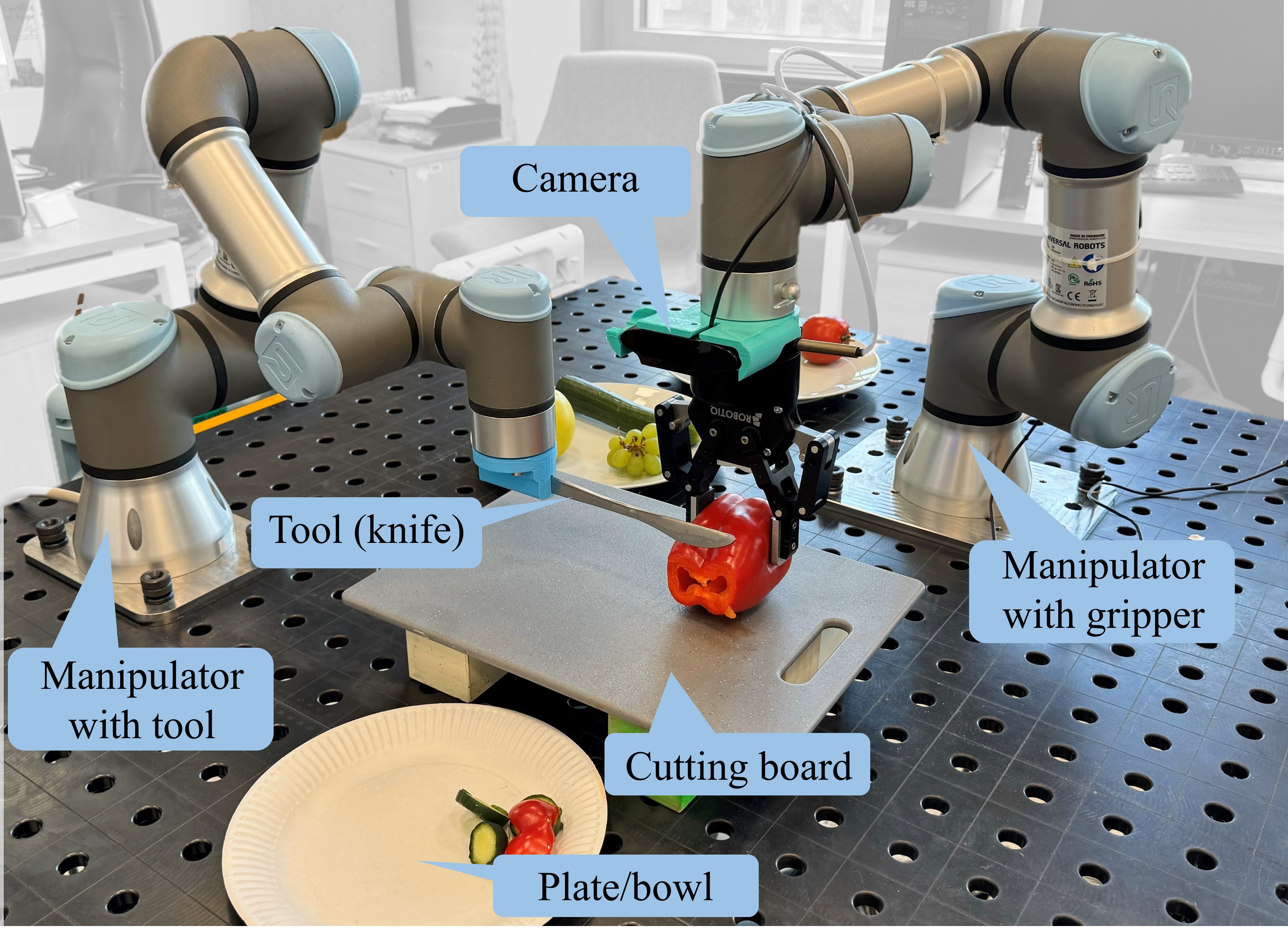
0
Bi-VLA: Vision-Language-Action Model-Based System for Bimanual Robotic Dexterous Manipulations
Koffivi Fid`ele Gbagbe, Miguel Altamirano Cabrera, Ali Alabbas, Oussama Alyunes, Artem Lykov, Dzmitry Tsetserukou
This research introduces the Bi-VLA (Vision-Language-Action) model, a novel system designed for bimanual robotic dexterous manipulation that seamlessly integrates vision for scene understanding, language comprehension for translating human instructions into executable code, and physical action generation. We evaluated the system's functionality through a series of household tasks, including the preparation of a desired salad upon human request. Bi-VLA demonstrates the ability to interpret complex human instructions, perceive and understand the visual context of ingredients, and execute precise bimanual actions to prepare the requested salad. We assessed the system's performance in terms of accuracy, efficiency, and adaptability to different salad recipes and human preferences through a series of experiments. Our results show a 100% success rate in generating the correct executable code by the Language Module, a 96.06% success rate in detecting specific ingredients by the Vision Module, and an overall success rate of 83.4% in correctly executing user-requested tasks.
Read more8/20/2024