A Survey on Vision-Language-Action Models for Embodied AI
2405.14093
0
0
🤖
Abstract
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
Create account to get full access
Overview
- Deep learning has achieved remarkable success in various domains, including computer vision, natural language processing, and reinforcement learning.
- Representative artificial neural networks in these fields include convolutional neural networks, Transformers, and deep Q-networks.
- Numerous multi-modal models have been developed to address tasks like visual question answering, image captioning, and speech recognition.
- The rise of instruction-following robotic policies in embodied AI has led to the emergence of a novel category of multi-modal models known as vision-language-action models (VLAs).
- VLAs have become a foundational element in robot learning, with various methods proposed to enhance traits like versatility, dexterity, and generalizability.
Plain English Explanation
Deep learning is a powerful type of artificial intelligence that has achieved remarkable success in many different areas, such as computer vision (understanding images), natural language processing (working with text), and reinforcement learning (learning through trial and error). The key building blocks of deep learning systems in these fields include convolutional neural networks, Transformers, and deep Q-networks.
Building on these single-input models, researchers have developed numerous multi-modal models that can work with multiple types of data, like images and text. These models have been used for tasks like answering questions about images, describing images in words, and recognizing speech.
More recently, the field of embodied AI, which focuses on teaching robots to follow instructions and learn through interaction with the physical world, has led to the creation of a new type of multi-modal model called a vision-language-action model (VLA). VLAs are able to process visual information, understand language, and take actions, making them a crucial component of robot learning.
Researchers have proposed various methods to enhance the capabilities of VLAs, such as making them more versatile, dexterous, and able to generalize to new situations. This is an active area of research as the field of embodied AI continues to rapidly advance.
Technical Explanation
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks.
Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning.
Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI.
Critical Analysis
The paper provides a comprehensive survey of the evolving landscape of vision-language-action (VLA) models, which have become a foundational element in robot learning. While the technical details and advancements highlighted are impressive, the paper does not delve into the potential limitations or ethical considerations of these models.
One area that could benefit from further discussion is the generalizability and robustness of VLA models. The paper mentions methods to enhance traits like versatility and dexterity, but it is important to understand the extent to which these models can truly generalize to novel situations and environments, especially when deployed in real-world robotics applications.
Additionally, the paper does not address potential biases or safety concerns that may arise from these multi-modal systems. As VLAs become more prominent in embodied AI, it will be crucial to carefully consider their societal impact and ensure they are developed and deployed responsibly.
Overall, the paper provides a valuable overview of the rapid advancements in VLA models, but future research should also prioritize a more critical examination of the limitations and potential risks associated with these powerful AI systems.
Conclusion
This paper showcases the remarkable progress made in the field of deep learning, particularly in the development of vision-language-action models (VLAs) for embodied AI. By combining the processing of visual information, language understanding, and action prediction, VLAs have become a foundational element in robot learning, with various methods proposed to enhance their versatility, dexterity, and generalizability.
The rapid advancement of VLAs reflects the broader progress in the field of deep learning, which has achieved remarkable success across diverse domains, from computer vision to natural language processing and reinforcement learning. As the field of embodied AI continues to evolve, the development of sophisticated VLA models will likely play a crucial role in enabling robots to better understand and interact with the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
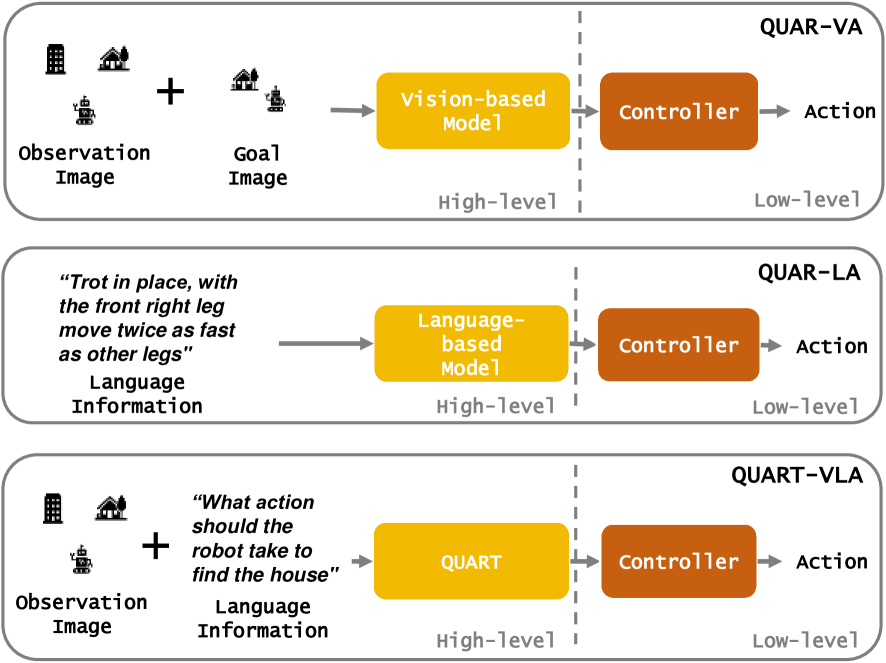
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Pengxiang Ding, Han Zhao, Wenjie Zhang, Wenxuan Song, Ningxi Yang, Donglin Wang
0
0
The important manifestation of robot intelligence is the ability to naturally interact and autonomously make decisions. Traditional approaches to robot control often compartmentalize perception, planning, and decision-making, simplifying system design but limiting the synergy between different information streams. This compartmentalization poses challenges in achieving seamless autonomous reasoning, decision-making, and action execution. To address these limitations, a novel paradigm, named Vision-Language-Action tasks for QUAdruped Robots (QUAR-VLA), has been introduced in this paper. This approach tightly integrates visual information and instructions to generate executable actions, effectively merging perception, planning, and decision-making. The central idea is to elevate the overall intelligence of the robot. Within this framework, a notable challenge lies in aligning fine-grained instructions with visual perception information. This emphasizes the complexity involved in ensuring that the robot accurately interprets and acts upon detailed instructions in harmony with its visual observations. Consequently, we propose QUAdruped Robotic Transformer (QUART), a family of VLA models to integrate visual information and instructions from diverse modalities as input and generates executable actions for real-world robots and present QUAdruped Robot Dataset (QUARD), a large-scale multi-task dataset including navigation, complex terrain locomotion, and whole-body manipulation tasks for training QUART models. Our extensive evaluation (4000 evaluation trials) shows that our approach leads to performant robotic policies and enables QUART to obtain a range of emergent capabilities.
6/18/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
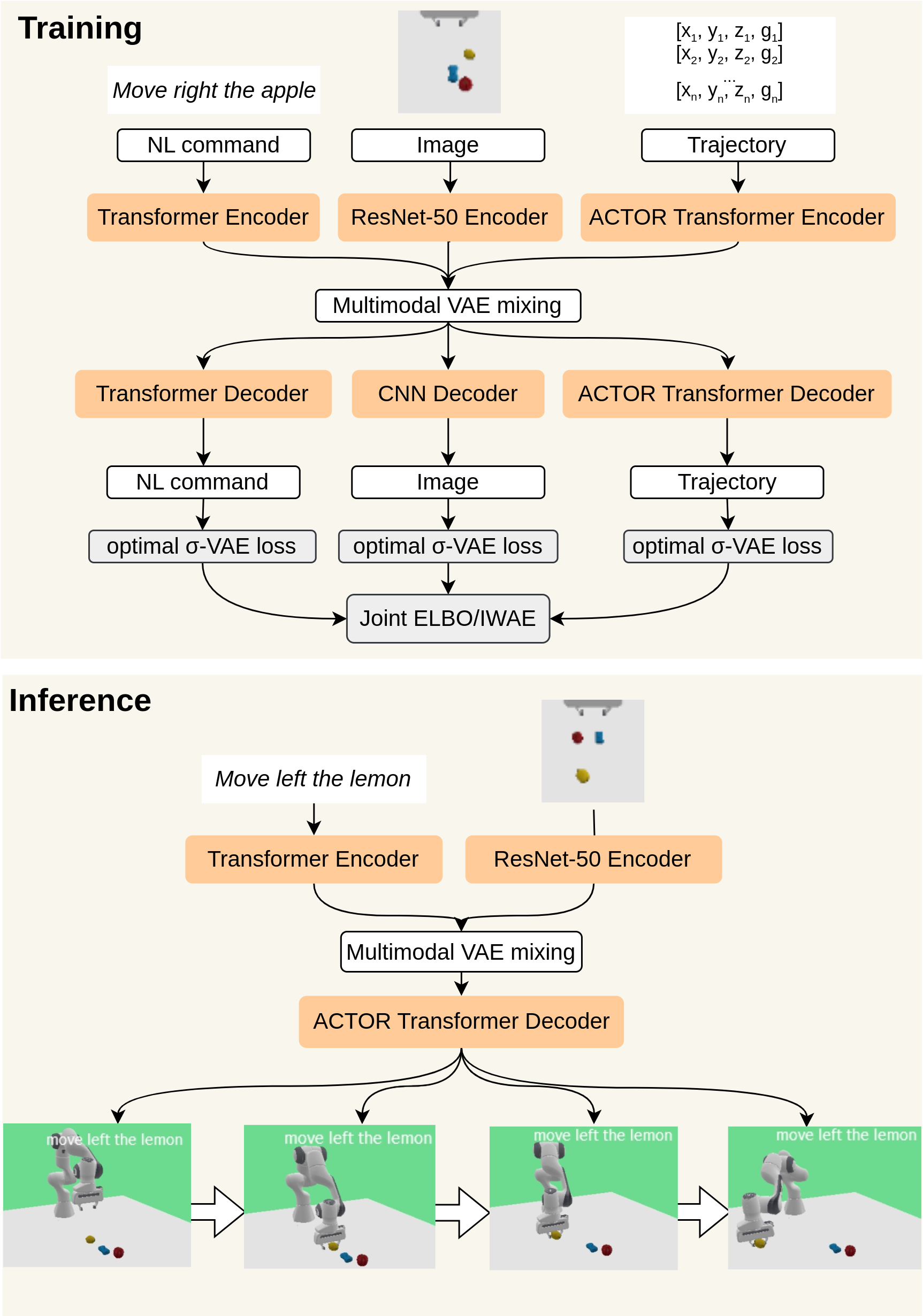
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
0
0
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
4/3/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024