Towards Unsupervised Domain Adaptation via Domain-Transformer

0
🤷
Sign in to get full access
Overview
- Unsupervised Domain Adaptation (UDA) aims to transfer effective feature learning from a labeled source domain to an unlabeled target domain.
- Transformers have shown success in UDA, but simple application only captures patch-level information and lacks interpretability.
- To address these issues, the authors propose the Domain-Transformer (DoT) with a domain-level attention mechanism to capture long-range correspondence between cross-domain samples.
Plain English Explanation
The paper tackles the problem of Unsupervised Domain Adaptation (UDA), which is about taking a machine learning model trained on one dataset (the "source" domain) and adapting it to work well on a different, unlabeled dataset (the "target" domain). This is an important challenge in pattern analysis and machine intelligence.
The authors note that recent successes in UDA have come from using Transformer models as the underlying architecture. However, these simple Transformer applications can only capture information at the patch-level and lack interpretability.
To address these limitations, the authors propose a new model called Domain-Transformer (DoT). DoT uses a domain-level attention mechanism to capture the long-range relationships between samples from the source and target domains. This helps the model better understand the differences between the two domains and learn more transferable features.
The paper provides a mathematical analysis of DoT, connecting the domain-level attention to optimal transport theory and Wasserstein distance. This provides a theoretical foundation for why DoT is effective at knowledge transfer.
Methodologically, DoT integrates the domain-level attention with manifold structure regularization, which helps capture both the sample-level information and the locality consistency of the cross-domain cluster structures. Unlike other UDA methods, DoT does not require explicit modeling of the distribution discrepancy between domains or the use of pseudo-labels.
Overall, the authors show through extensive experiments that DoT outperforms other state-of-the-art UDA techniques on several benchmark datasets.
Technical Explanation
The key technical aspects of the paper are:
-
Domain-Transformer (DoT) Architecture: DoT uses a Transformer-based architecture, but with a novel domain-level attention mechanism that captures long-range correspondences between samples from the source and target domains. This is in contrast to standard Transformers, which only operate at the patch level and lack interpretability.
-
Theoretical Analysis: The authors provide a mathematical understanding of DoT from two perspectives:
- Optimal Transport Theory: They connect the domain-level attention to optimal transport theory, which provides interpretability from the Wasserstein geometry perspective.
- Learning Theory: They derive Wasserstein distance-based generalization bounds, which explain the effectiveness of DoT for knowledge transfer between domains.
-
Methodological Innovations: DoT integrates the domain-level attention with manifold structure regularization, which characterizes both the sample-level information and the locality consistency of the cross-domain cluster structures. Unlike other UDA methods, DoT does not require explicit modeling of the distribution discrepancy between domains or the use of pseudo-labels.
-
Experimental Validation: The authors conduct extensive experiments on several benchmark datasets, demonstrating the effectiveness of DoT compared to other state-of-the-art UDA techniques.
Critical Analysis
The paper presents a novel and well-designed approach to Unsupervised Domain Adaptation (UDA) using a Transformer-based architecture. The key strengths of the work include:
-
Interpretability: By connecting the domain-level attention mechanism to optimal transport theory and Wasserstein geometry, the authors provide a mathematically grounded interpretation of how DoT learns transferable features.
-
Methodological Innovations: The integration of domain-level attention and manifold structure regularization is a unique and effective approach to capturing both the sample-level information and the locality consistency of cross-domain clusters.
-
Practical Advantages: DoT's ability to learn transferable features without the need for pseudo-labels or explicit modeling of domain discrepancy is a significant advantage over other UDA methods.
However, the paper could be strengthened by addressing the following potential limitations:
-
Generalization to Diverse Domains: The experimental evaluation is focused on a limited set of benchmark datasets. It would be valuable to see how DoT performs on a wider range of domain adaptation scenarios, including those with larger distributional shifts or more complex data structures.
-
Computational Efficiency: The use of Transformer-based architectures can be computationally intensive, especially for large-scale real-world applications. The authors could discuss the computational complexity of DoT and explore potential avenues for improving efficiency.
-
Comparison to Other Attention-based Approaches: While the authors highlight the advantages of DoT over standard Transformer models, a more in-depth comparison to other attention-based UDA methods could provide additional insights and a more comprehensive understanding of the state of the art.
Overall, the Domain-Transformer (DoT) proposed in this paper represents a significant contribution to the field of Unsupervised Domain Adaptation, with strong theoretical grounding and promising experimental results. The work opens up interesting avenues for further research and practical applications in the area of pattern analysis and machine intelligence.
Conclusion
This paper tackles the important problem of Unsupervised Domain Adaptation (UDA) by proposing a novel Domain-Transformer (DoT) architecture. DoT addresses the limitations of standard Transformer-based UDA approaches by incorporating a domain-level attention mechanism that captures long-range correspondences between samples from the source and target domains.
The authors provide a strong theoretical foundation for DoT, connecting the domain-level attention to optimal transport theory and deriving Wasserstein distance-based generalization bounds. Methodologically, DoT integrates the domain-level attention with manifold structure regularization, which helps characterize both the sample-level information and the locality consistency of cross-domain cluster structures.
Through extensive experiments, the authors demonstrate the effectiveness of DoT compared to other state-of-the-art UDA techniques on several benchmark datasets. The work offers a promising direction for advancing the field of pattern analysis and machine intelligence, with potential applications in a wide range of real-world scenarios where effective cross-domain knowledge transfer is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Towards Unsupervised Domain Adaptation via Domain-Transformer
Ren Chuan-Xian, Zhai Yi-Ming, Luo You-Wei, Yan Hong
As a vital problem in pattern analysis and machine intelligence, Unsupervised Domain Adaptation (UDA) attempts to transfer an effective feature learner from a labeled source domain to an unlabeled target domain. Inspired by the success of the Transformer, several advances in UDA are achieved by adopting pure transformers as network architectures, but such a simple application can only capture patch-level information and lacks interpretability. To address these issues, we propose the Domain-Transformer (DoT) with domain-level attention mechanism to capture the long-range correspondence between the cross-domain samples. On the theoretical side, we provide a mathematical understanding of DoT: 1) We connect the domain-level attention with optimal transport theory, which provides interpretability from Wasserstein geometry; 2) From the perspective of learning theory, Wasserstein distance-based generalization bounds are derived, which explains the effectiveness of DoT for knowledge transfer. On the methodological side, DoT integrates the domain-level attention and manifold structure regularization, which characterize the sample-level information and locality consistency for cross-domain cluster structures. Besides, the domain-level attention mechanism can be used as a plug-and-play module, so DoT can be implemented under different neural network architectures. Instead of explicitly modeling the distribution discrepancy at domain-level or class-level, DoT learns transferable features under the guidance of long-range correspondence, so it is free of pseudo-labels and explicit domain discrepancy optimization. Extensive experiment results on several benchmark datasets validate the effectiveness of DoT.
Read more8/14/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
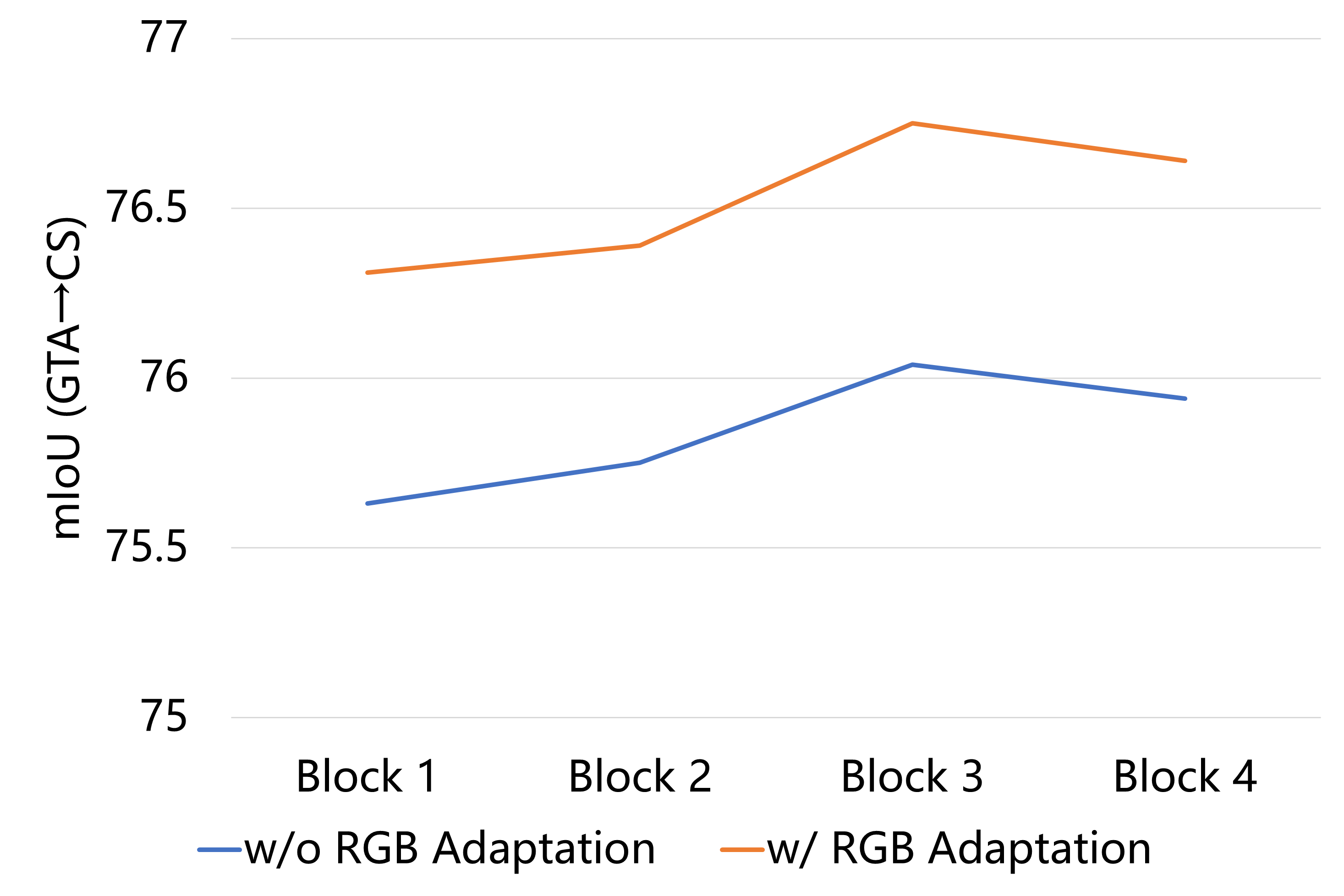
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024
0
TransferAttn: Transferable-guided Attention Is All You Need for Video Domain Adaptation
Andr'e Sacilotti, Samuel Felipe dos Santos, Nicu Sebe, Jurandy Almeida
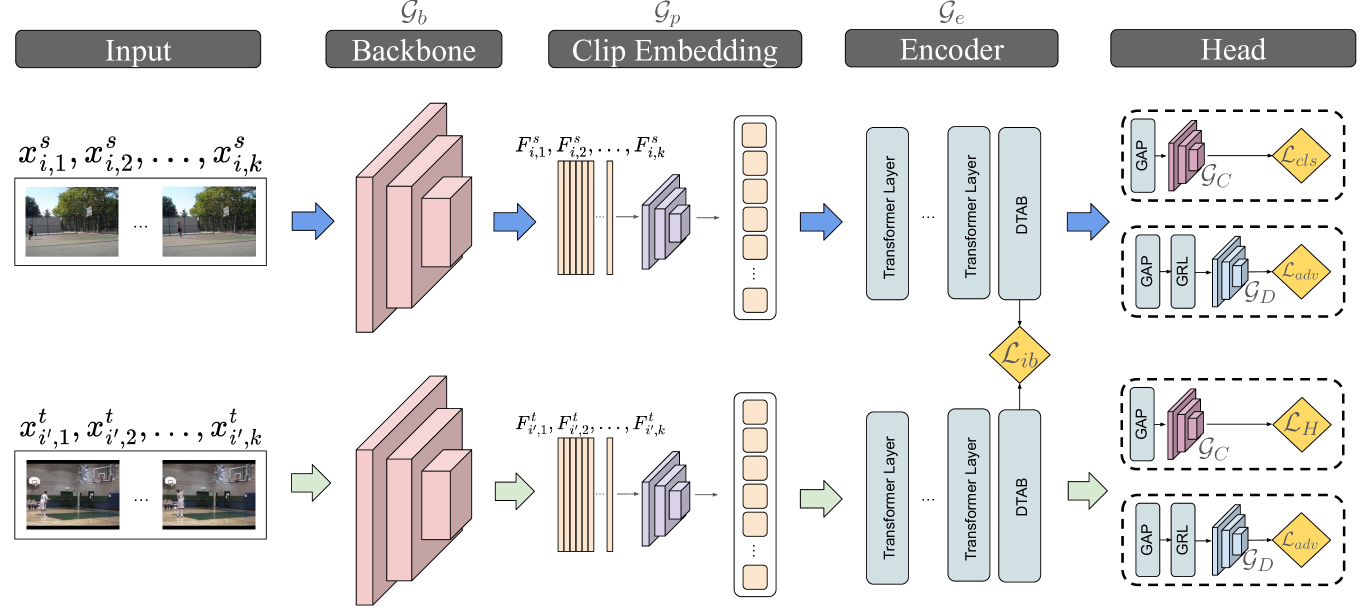
Unsupervised domain adaptation (UDA) in videos is a challenging task that remains not well explored compared to image-based UDA techniques. Although vision transformers (ViT) achieve state-of-the-art performance in many computer vision tasks, their use in video domain adaptation has still been little explored. Our key idea is to use the transformer layers as a feature encoder and incorporate spatial and temporal transferability relationships into the attention mechanism. A Transferable-guided Attention (TransferAttn) framework is then developed to exploit the capacity of the transformer to adapt cross-domain knowledge from different backbones. To improve the transferability of ViT, we introduce a novel and effective module named Domain Transferable-guided Attention Block~(DTAB). DTAB compels ViT to focus on the spatio-temporal transferability relationship among video frames by changing the self-attention mechanism to a transferability attention mechanism. Extensive experiments on UCF-HMDB, Kinetics-Gameplay, and Kinetics-NEC Drone datasets with different backbones, like ResNet101, I3D, and STAM, verify the effectiveness of TransferAttn compared with state-of-the-art approaches. Also, we demonstrate that DTAB yields performance gains when applied to other state-of-the-art transformer-based UDA methods from both video and image domains. The code will be made freely available.
Read more7/2/2024

0
EUDA: An Efficient Unsupervised Domain Adaptation via Self-Supervised Vision Transformer
Ali Abedi, Q. M. Jonathan Wu, Ning Zhang, Farhad Pourpanah
Unsupervised domain adaptation (UDA) aims to mitigate the domain shift issue, where the distribution of training (source) data differs from that of testing (target) data. Many models have been developed to tackle this problem, and recently vision transformers (ViTs) have shown promising results. However, the complexity and large number of trainable parameters of ViTs restrict their deployment in practical applications. This underscores the need for an efficient model that not only reduces trainable parameters but also allows for adjustable complexity based on specific needs while delivering comparable performance. To achieve this, in this paper we introduce an Efficient Unsupervised Domain Adaptation (EUDA) framework. EUDA employs the DINOv2, which is a self-supervised ViT, as a feature extractor followed by a simplified bottleneck of fully connected layers to refine features for enhanced domain adaptation. Additionally, EUDA employs the synergistic domain alignment loss (SDAL), which integrates cross-entropy (CE) and maximum mean discrepancy (MMD) losses, to balance adaptation by minimizing classification errors in the source domain while aligning the source and target domain distributions. The experimental results indicate the effectiveness of EUDA in producing comparable results as compared with other state-of-the-art methods in domain adaptation with significantly fewer trainable parameters, between 42% to 99.7% fewer. This showcases the ability to train the model in a resource-limited environment. The code of the model is available at: https://github.com/A-Abedi/EUDA.
Read more8/1/2024