Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Tracking Meets LoRA" that combines visual object tracking and the Low-Rank Adaptation (LoRA) technique for parameter-efficient fine-tuning.
- The approach enables faster training, the use of larger models, and stronger performance compared to traditional fine-tuning methods.
Plain English Explanation
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance combines two key ideas:
- Visual object tracking: This is a computer vision technique that helps track the location of an object in a video.
- LoRA (Low-Rank Adaptation): This is a method for fine-tuning large language models by only updating a small number of parameters, rather than the entire model. This makes the fine-tuning process faster and more efficient.
By bringing these two ideas together, the researchers created a new approach that allows for:
- Faster training: The LoRA technique requires updating only a small number of parameters, so the fine-tuning process is much quicker.
- Using larger models: Since only a small portion of the model needs to be updated, larger and more powerful models can be used without significantly increasing training time.
- Stronger performance: The combination of tracking and LoRA results in better performance on visual object tracking tasks compared to traditional fine-tuning methods.
In summary, this paper presents a clever way to leverage the strengths of visual object tracking and parameter-efficient fine-tuning to create a more powerful and efficient approach for working with large language models.
Technical Explanation
The paper first reviews the existing paradigms of Transformer-based trackers, which typically require fine-tuning the entire model on a specific task.
To address the limitations of this approach, the authors propose "Tracking Meets LoRA," which combines visual object tracking with the LoRA fine-tuning technique.
The key elements of their approach include:
- Using a pre-trained Transformer model as the backbone.
- Applying LoRA to fine-tune only a small number of parameters, rather than the entire model.
- Leveraging visual object tracking to capture the spatial and temporal relationships in the input data.
Through extensive experiments, the authors demonstrate that their approach outperforms traditional fine-tuning methods in terms of training speed, model size, and tracking performance on various benchmarks.
Critical Analysis
The paper provides a compelling solution to the challenges of fine-tuning large language models for visual object tracking tasks. The authors acknowledge that their approach has some limitations, such as the need for task-specific LoRA layers and the potential for overfitting on small datasets.
Additionally, while the paper showcases strong results, it would be useful to see further analysis on the generalizability of the approach to a wider range of tracking tasks and datasets. Exploring the trade-offs between the number of LoRA parameters and overall performance could also yield valuable insights.
Overall, the "Tracking Meets LoRA" method represents an innovative and promising direction for leveraging the power of large language models in a more efficient and effective manner. The ideas presented in this paper could have broader implications for parameter-efficient fine-tuning of large models across a variety of domains.
Conclusion
This paper introduces a novel approach called "Tracking Meets LoRA" that combines visual object tracking and the LoRA fine-tuning technique. By leveraging the strengths of these two ideas, the authors demonstrate a way to train larger models more efficiently, resulting in faster training and stronger performance on visual object tracking tasks.
The work represents an important step forward in the field of parameter-efficient fine-tuning, and the insights from this research could have broader applications in other areas of machine learning and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance
Liting Lin, Heng Fan, Zhipeng Zhang, Yaowei Wang, Yong Xu, Haibin Ling
Motivated by the Parameter-Efficient Fine-Tuning (PEFT) in large language models, we propose LoRAT, a method that unveils the power of large ViT model for tracking within laboratory-level resources. The essence of our work lies in adapting LoRA, a technique that fine-tunes a small subset of model parameters without adding inference latency, to the domain of visual tracking. However, unique challenges and potential domain gaps make this transfer not as easy as the first intuition. Firstly, a transformer-based tracker constructs unshared position embedding for template and search image. This poses a challenge for the transfer of LoRA, usually requiring consistency in the design when applied to the pre-trained backbone, to downstream tasks. Secondly, the inductive bias inherent in convolutional heads diminishes the effectiveness of parameter-efficient fine-tuning in tracking models. To overcome these limitations, we first decouple the position embeddings in transformer-based trackers into shared spatial ones and independent type ones. The shared embeddings, which describe the absolute coordinates of multi-resolution images (namely, the template and search images), are inherited from the pre-trained backbones. In contrast, the independent embeddings indicate the sources of each token and are learned from scratch. Furthermore, we design an anchor-free head solely based on MLP to adapt PETR, enabling better performance with less computational overhead. With our design, 1) it becomes practical to train trackers with the ViT-g backbone on GPUs with only memory of 25.8GB (batch size of 16); 2) we reduce the training time of the L-224 variant from 35.0 to 10.8 GPU hours; 3) we improve the LaSOT SUC score from 0.703 to 0.742 with the L-224 variant; 4) we fast the inference speed of the L-224 variant from 52 to 119 FPS. Code and models are available at https://github.com/LitingLin/LoRAT.
Read more7/29/2024
🌿
2
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
Read more5/3/2024

0
$textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
Runqian Wang, Soumya Ghosh, David Cox, Diego Antognini, Aude Oliva, Rogerio Feris, Leonid Karlinsky
Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
Read more5/28/2024
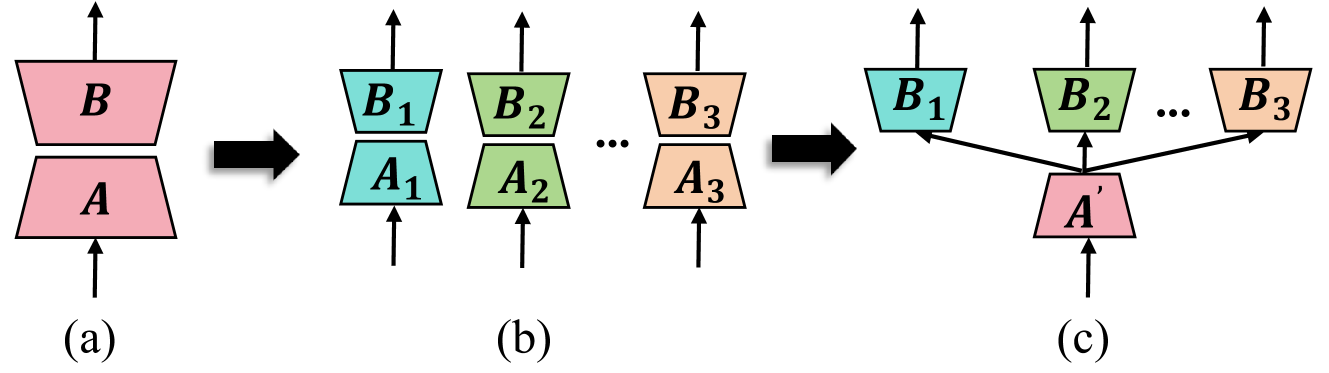
0
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, Chengzhong Xu
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases.
Read more5/24/2024