Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?

0
Sign in to get full access
Overview
- Investigates whether AI models may be secretly trained on data created by others
- Proposes techniques to detect unauthorized use of training data
- Focuses on text-to-image models, a popular AI technology
Plain English Explanation
The paper explores the potential issue of AI models being secretly trained on data created by others, without the creators' knowledge or consent. This is an important concern as AI models, particularly text-to-image systems, are becoming increasingly powerful and widespread.
The researchers present techniques to detect unauthorized use of training data. By analyzing the outputs of AI models, they aim to determine if the models were trained on data created by specific individuals or organizations. This could help protect intellectual property and ensure AI development is transparent and ethical.
The paper focuses on text-to-image models, which generate images from textual descriptions. These models have gained significant attention and are seen as a promising AI technology. However, the potential for misuse of training data is a valid concern that the researchers seek to address.
Technical Explanation
The paper proposes several techniques to attribute the source of training data used by text-to-image models. One approach involves embedding unique watermarks into the training data, which can then be detected in the model's outputs. Another method analyzes the textual descriptions and visual features of the generated images to identify patterns that may indicate the use of specific datasets.
The researchers also discuss ways to scale these attribution techniques to handle large-scale AI models and datasets. This includes developing efficient algorithms and leveraging contextual information to improve the accuracy of data source identification.
Additionally, the paper explores techniques for detecting unauthorized use of training data in text-to-image diffusion models, which are a type of AI system that has gained popularity in recent years. The researchers propose methods to analyze the visual and textual properties of the generated images to identify potential misuse of training data.
Critical Analysis
The paper raises important concerns about the potential misuse of training data in AI systems, particularly in the rapidly evolving field of text-to-image models. The proposed techniques for data attribution and unauthorized use detection are a valuable contribution to the ongoing efforts to ensure the transparency and ethical development of AI.
However, the effectiveness of these approaches may be limited by the ability of AI models to bypass or overcome the proposed detection methods. As AI systems become more sophisticated, the research community will need to continuously develop new techniques to stay ahead of potential attempts to circumvent the attribution and detection mechanisms.
Furthermore, the paper does not address potential privacy concerns or the implications of these techniques on the rights of individuals whose data may be used in AI training. Careful consideration should be given to balancing the need for data protection and the desire for AI transparency.
Conclusion
The paper highlights the critical issue of training data attribution in AI models, particularly in the context of text-to-image systems. The proposed techniques offer a promising approach to detecting unauthorized use of training data, which could help protect intellectual property and promote ethical AI development.
As AI technologies continue to evolve, ongoing research and collaboration between AI developers, data creators, and policymakers will be essential to address the complex challenges around data attribution and ensure the responsible use of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Likun Zhang, Hao Wu, Lingcui Zhang, Fengyuan Xu, Jin Cao, Fenghua Li, Ben Niu
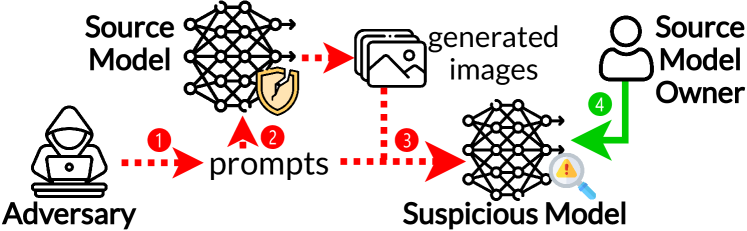
The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
Read more9/25/2024
📊
0
DIAGNOSIS: Detecting Unauthorized Data Usages in Text-to-image Diffusion Models
Zhenting Wang, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, Shiqing Ma
Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized data usage during the training or fine-tuning process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission and giving credit to the artist. To address this issue, we propose a method for detecting such unauthorized data usage by planting the injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected images by adding unique contents on these images using stealthy image warping functions that are nearly imperceptible to humans but can be captured and memorized by diffusion models. By analyzing whether the model has memorized the injected content (i.e., whether the generated images are processed by the injected post-processing function), we can detect models that had illegally utilized the unauthorized data. Experiments on Stable Diffusion and VQ Diffusion with different model training or fine-tuning methods (i.e, LoRA, DreamBooth, and standard training) demonstrate the effectiveness of our proposed method in detecting unauthorized data usages. Code: https://github.com/ZhentingWang/DIAGNOSIS.
Read more4/10/2024

0
Data Attribution for Text-to-Image Models by Unlearning Synthesized Images
Sheng-Yu Wang, Aaron Hertzmann, Alexei A. Efros, Jun-Yan Zhu, Richard Zhang
The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. We can define influence by saying that, for a given output, if a model is retrained from scratch without that output's most influential images, the model should then fail to generate that output image. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining from scratch. We propose a new approach that efficiently identifies highly-influential images. Specifically, we simulate unlearning the synthesized image, proposing a method to increase the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. Then, we find training images that are forgotten by proxy, identifying ones with significant loss deviations after the unlearning process, and label these as influential. We evaluate our method with a computationally intensive but gold-standard retraining from scratch and demonstrate our method's advantages over previous methods.
Read more6/14/2024

0
Protect-Your-IP: Scalable Source-Tracing and Attribution against Personalized Generation
Runyi Li, Xuanyu Zhang, Zhipei Xu, Yongbing Zhang, Jian Zhang
With the advent of personalized generation models, users can more readily create images resembling existing content, heightening the risk of violating portrait rights and intellectual property (IP). Traditional post-hoc detection and source-tracing methods for AI-generated content (AIGC) employ proactive watermark approaches; however, these are less effective against personalized generation models. Moreover, attribution techniques for AIGC rely on passive detection but often struggle to differentiate AIGC from authentic images, presenting a substantial challenge. Integrating these two processes into a cohesive framework not only meets the practical demands for protection and forensics but also improves the effectiveness of attribution tasks. Inspired by this insight, we propose a unified approach for image copyright source-tracing and attribution, introducing an innovative watermarking-attribution method that blends proactive and passive strategies. We embed copyright watermarks into protected images and train a watermark decoder to retrieve copyright information from the outputs of personalized models, using this watermark as an initial step for confirming if an image is AIGC-generated. To pinpoint specific generation techniques, we utilize powerful visual backbone networks for classification. Additionally, we implement an incremental learning strategy to adeptly attribute new personalized models without losing prior knowledge, thereby enhancing the model's adaptability to novel generation methods. We have conducted experiments using various celebrity portrait series sourced online, and the results affirm the efficacy of our method in source-tracing and attribution tasks, as well as its robustness against knowledge forgetting.
Read more5/28/2024