Data Attribution for Text-to-Image Models by Unlearning Synthesized Images

0

Sign in to get full access
Overview
- This paper explores a novel approach to address the issue of data attribution in text-to-image models.
- The key idea is to "unlearn" the influence of synthesized images during model training, which can help identify the original data sources used to train the model.
- The proposed method has the potential to improve transparency and accountability in the development of text-to-image AI systems.
Plain English Explanation
Text-to-image models, such as DALL-E and Stable Diffusion, have made remarkable progress in generating realistic images from text descriptions. However, these models are often trained on large, diverse datasets that can include both real and synthetic (or generated) images. This raises concerns about the provenance and attribution of the data used to train these models.
The researchers in this paper present a technique to "unlearn" the influence of synthesized images during the training process. By identifying and minimizing the model's reliance on these synthetic images, the researchers aim to improve the transparency of text-to-image models and better understand the sources of the original data used for training.
This approach could help address issues of invisible relevance bias in text-image retrieval models and the unmet promise of synthetic training images. Overall, the paper explores an important step towards detecting image attribution and unlearning traces of influential training data in these powerful AI systems.
Technical Explanation
The researchers propose a novel technique called "Unlearning Synthesized Images" (USI) to address the data attribution problem in text-to-image models. The key idea is to identify and minimize the model's reliance on synthetic images during the training process, which can help reveal the original data sources used to train the model.
The USI method works by first training a text-to-image model in the standard way, using a dataset that includes both real and synthetic images. The researchers then introduce an additional "unlearning" step, where the model is further trained to minimize its ability to generate images that are too similar to the synthetic images in the original dataset.
This unlearning process encourages the model to rely more on the real images in the dataset, effectively "forgetting" the influence of the synthetic data. By analyzing the model's behavior after this unlearning step, the researchers can then infer information about the original data sources used to train the model.
The paper presents experiments that demonstrate the effectiveness of the USI method in improving data attribution for text-to-image models. The researchers show that their approach can help identify the original data sources used to train the model, even when a significant portion of the training data is synthetic.
Critical Analysis
The paper presents a promising approach to addressing the important issue of data attribution in text-to-image models. However, the authors acknowledge several limitations and areas for further research:
- The unlearning process may not completely eliminate the influence of synthetic images, and some residual bias may still remain in the model.
- The effectiveness of the USI method may depend on the specific characteristics of the synthetic images in the training dataset, and it may not work as well for more advanced or diverse synthetic data.
- The paper focuses on text-to-image models, but the principles could potentially be extended to other AI systems that rely on large, heterogeneous training datasets.
Additionally, one could raise questions about the broader implications of this research. While the USI method aims to improve transparency and accountability, it could also be used to obfuscate the true nature of the training data or the model's capabilities. There are complex ethical considerations around the responsible development and deployment of these powerful AI systems.
Conclusion
This paper presents a novel technique called "Unlearning Synthesized Images" (USI) to address the data attribution problem in text-to-image models. By minimizing the model's reliance on synthetic images during training, the USI method can help reveal the original data sources used to develop these AI systems.
The proposed approach has the potential to improve transparency and accountability in the field of text-to-image generation, which is an important step towards responsible AI development. While the paper acknowledges some limitations, the core ideas explored here could have far-reaching implications for the broader challenge of detecting and mitigating bias in AI models.
As the capabilities of text-to-image AI continue to advance, it is crucial that we develop techniques to better understand the data and processes underlying these powerful systems. The USI method represents an important contribution towards this goal, and it will be interesting to see how this research evolves and is applied in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Attribution for Text-to-Image Models by Unlearning Synthesized Images
Sheng-Yu Wang, Aaron Hertzmann, Alexei A. Efros, Jun-Yan Zhu, Richard Zhang
The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. We can define influence by saying that, for a given output, if a model is retrained from scratch without that output's most influential images, the model should then fail to generate that output image. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining from scratch. We propose a new approach that efficiently identifies highly-influential images. Specifically, we simulate unlearning the synthesized image, proposing a method to increase the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. Then, we find training images that are forgotten by proxy, identifying ones with significant loss deviations after the unlearning process, and label these as influential. We evaluate our method with a computationally intensive but gold-standard retraining from scratch and demonstrate our method's advantages over previous methods.
Read more6/14/2024
0
New!Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Likun Zhang, Hao Wu, Lingcui Zhang, Fengyuan Xu, Jin Cao, Fenghua Li, Ben Niu
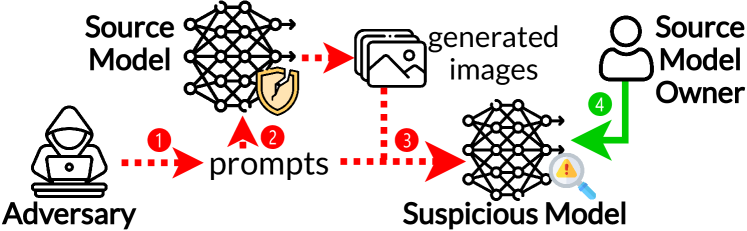
The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
Read more9/25/2024

0
A Dataset and Benchmark for Copyright Infringement Unlearning from Text-to-Image Diffusion Models
Rui Ma, Qiang Zhou, Yizhu Jin, Daquan Zhou, Bangjun Xiao, Xiuyu Li, Yi Qu, Aishani Singh, Kurt Keutzer, Jingtong Hu, Xiaodong Xie, Zhen Dong, Shanghang Zhang, Shiji Zhou
Copyright law confers upon creators the exclusive rights to reproduce, distribute, and monetize their creative works. However, recent progress in text-to-image generation has introduced formidable challenges to copyright enforcement. These technologies enable the unauthorized learning and replication of copyrighted content, artistic creations, and likenesses, leading to the proliferation of unregulated content. Notably, models like stable diffusion, which excel in text-to-image synthesis, heighten the risk of copyright infringement and unauthorized distribution.Machine unlearning, which seeks to eradicate the influence of specific data or concepts from machine learning models, emerges as a promising solution by eliminating the enquote{copyright memories} ingrained in diffusion models. Yet, the absence of comprehensive large-scale datasets and standardized benchmarks for evaluating the efficacy of unlearning techniques in the copyright protection scenarios impedes the development of more effective unlearning methods. To address this gap, we introduce a novel pipeline that harmonizes CLIP, ChatGPT, and diffusion models to curate a dataset. This dataset encompasses anchor images, associated prompts, and images synthesized by text-to-image models. Additionally, we have developed a mixed metric based on semantic and style information, validated through both human and artist assessments, to gauge the effectiveness of unlearning approaches. Our dataset, benchmark library, and evaluation metrics will be made publicly available to foster future research and practical applications (https://rmpku.github.io/CPDM-page/, website / http://149.104.22.83/unlearning.tar.gz, dataset).
Read more6/24/2024

2
Unlearning Traces the Influential Training Data of Language Models
Masaru Isonuma, Ivan Titov
Identifying the training datasets that influence a language model's outputs is essential for minimizing the generation of harmful content and enhancing its performance. Ideally, we can measure the influence of each dataset by removing it from training; however, it is prohibitively expensive to retrain a model multiple times. This paper presents UnTrac: unlearning traces the influence of a training dataset on the model's performance. UnTrac is extremely simple; each training dataset is unlearned by gradient ascent, and we evaluate how much the model's predictions change after unlearning. Furthermore, we propose a more scalable approach, UnTrac-Inv, which unlearns a test dataset and evaluates the unlearned model on training datasets. UnTrac-Inv resembles UnTrac, while being efficient for massive training datasets. In the experiments, we examine if our methods can assess the influence of pretraining datasets on generating toxic, biased, and untruthful content. Our methods estimate their influence much more accurately than existing methods while requiring neither excessive memory space nor multiple checkpoints.
Read more6/14/2024