Training-free Graph Neural Networks and the Power of Labels as Features
2404.19288
0
5
🧠
Abstract
We propose training-free graph neural networks (TFGNNs), which can be used without training and can also be improved with optional training, for transductive node classification. We first advocate labels as features (LaF), which is an admissible but not explored technique. We show that LaF provably enhances the expressive power of graph neural networks. We design TFGNNs based on this analysis. In the experiments, we confirm that TFGNNs outperform existing GNNs in the training-free setting and converge with much fewer training iterations than traditional GNNs.
Create account to get full access
Overview
- The paper proposes "training-free graph neural networks" (TFGNNs) that can be used without training and can also be improved with optional training for transductive node classification.
- It introduces "labels as features" (LaF), an admissible but unexplored technique, and shows that LaF can enhance the expressive power of graph neural networks.
- The experiments confirm that TFGNNs outperform existing GNNs in the training-free setting and converge with much fewer training iterations than traditional GNNs.
Plain English Explanation
The paper introduces a new type of graph neural network (GNN) called "training-free graph neural networks" (TFGNNs). GNNs are a class of machine learning models that can work with data represented as graphs, which consist of nodes (or vertices) connected by edges.
Typically, GNNs need to be trained on a large dataset before they can be used for tasks like classifying the nodes in a graph. The researchers propose a way to use GNNs without any training at all, which they call the "training-free" setting. They also show that TFGNNs can be further improved with optional training, if desired.
The key innovation in this paper is the use of "labels as features" (LaF). Traditionally, GNNs use the features (or attributes) of the nodes to make predictions. The researchers show that by also incorporating the labels (the correct classifications) of the nodes as additional features, the GNN can become more powerful and accurate, even without any training.
In their experiments, the researchers demonstrate that TFGNNs outperform existing GNNs in the training-free setting and require much less training time to achieve good performance compared to traditional GNNs.
Technical Explanation
The researchers propose "training-free graph neural networks" (TFGNNs) that can be used without any training and can also be improved with optional training for the task of transductive node classification.
The key innovation in this work is the introduction of "labels as features" (LaF), which the researchers show can enhance the expressive power of graph neural networks. Traditionally, GNNs use the features (or attributes) of the nodes to make predictions. The researchers demonstrate that by also incorporating the labels (the correct classifications) of the nodes as additional features, the GNN can become more powerful and accurate, even without any training.
The researchers design TFGNNs based on this LaF analysis. In their experiments, they confirm that TFGNNs outperform existing GNNs in the training-free setting and converge with much fewer training iterations than traditional GNNs.
Critical Analysis
The paper provides a novel and interesting approach to using graph neural networks without requiring extensive training. The researchers' insights about the benefits of incorporating label information as features (LaF) are compelling and could have broader implications for graph-based machine learning.
However, the paper does not address some potential limitations or caveats of the TFGNN approach. For example, it's unclear how well TFGNNs would perform on larger, more complex graphs or in settings with noisier or sparser label information. The researchers also don't discuss how the performance of TFGNNs might compare to other training-free or few-shot learning approaches for graph-based problems.
Additionally, the paper focuses primarily on the transductive node classification task. It would be interesting to see how well the TFGNN approach generalizes to other graph-based learning problems, such as link prediction, anomaly detection, or graph classification.
Despite these potential areas for further research, the paper makes a valuable contribution by introducing a novel and potentially useful approach to graph-based machine learning that could have applications in interpretable GNNs or defending against label inference attacks.
Conclusion
The proposed "training-free graph neural networks" (TFGNNs) offer a promising approach to using graph neural networks without the need for extensive training. By incorporating label information as features (LaF), the researchers have shown that GNNs can become more expressive and accurate, even in a training-free setting.
The experimental results demonstrating the advantages of TFGNNs over existing GNNs are encouraging and suggest that this approach could have practical applications in a variety of graph-based machine learning tasks. Further research is needed to explore the limitations and generalizability of the TFGNN approach, but this paper represents an important step forward in making graph neural networks more accessible and versatile.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Global-Local Graph Neural Networks for Node-Classification
Moshe Eliasof, Eran Treister
0
0
The task of graph node classification is often approached by utilizing a local Graph Neural Network (GNN), that learns only local information from the node input features and their adjacency. In this paper, we propose to improve the performance of node classification GNNs by utilizing both global and local information, specifically by learning label- and node- features. We therefore call our method Global-Local-GNN (GLGNN). To learn proper label features, for each label, we maximize the similarity between its features and nodes features that belong to the label, while maximizing the distance between nodes that do not belong to the considered label. We then use the learnt label features to predict the node classification map. We demonstrate our GLGNN using three different GNN backbones, and show that our approach improves baseline performance, revealing the importance of global information utilization for node classification.
6/18/2024
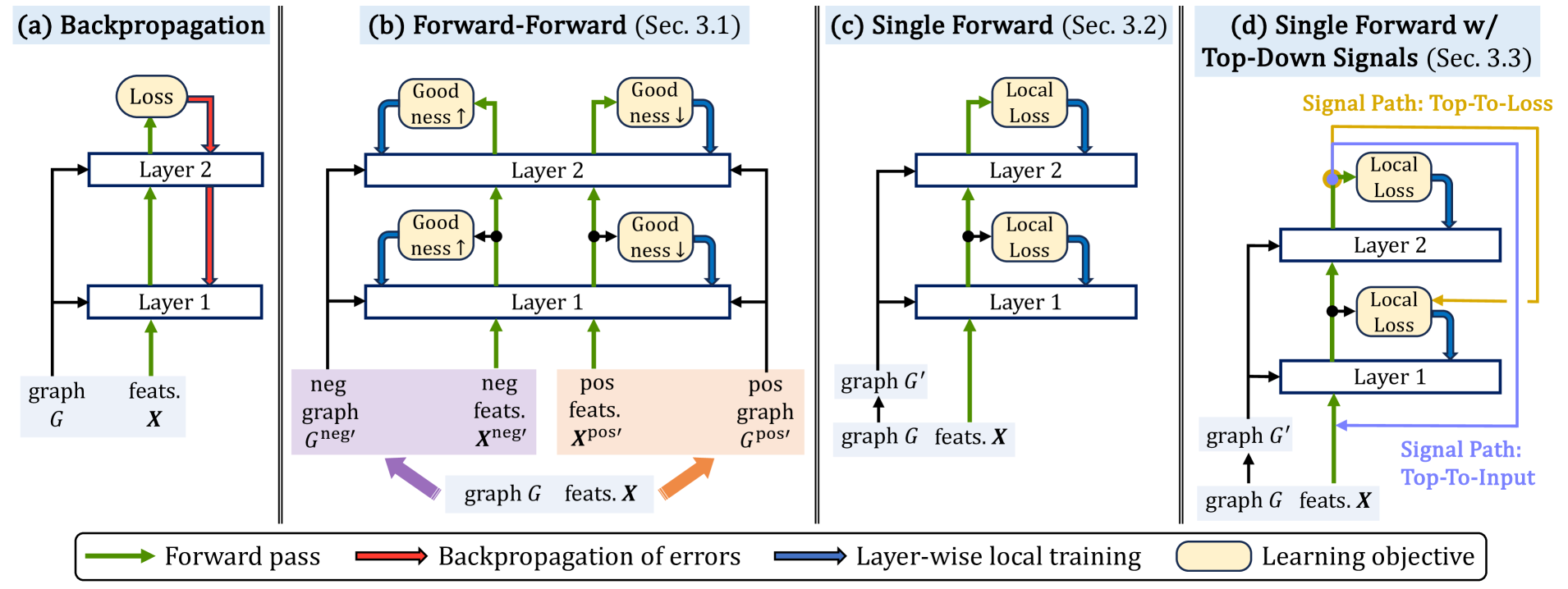
Forward Learning of Graph Neural Networks
Namyong Park, Xing Wang, Antoine Simoulin, Shuai Yang, Grey Yang, Ryan Rossi, Puja Trivedi, Nesreen Ahmed
0
0
Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.
4/16/2024
🏷️
Article Classification with Graph Neural Networks and Multigraphs
Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
0
0
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Network (GNN) pipelines with multi-graph representations that simultaneously encode multiple signals of article relatedness, e.g. references, co-authorship, shared publication source, shared subject headings, as distinct edge types. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark OGBN-arXiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph and PubMed Central, respectively. The results demonstrate that multi-graphs consistently improve the performance of a variety of GNN models compared to the default graphs. When deployed with SOTA textual node embedding methods, the transformed multi-graphs enable simple and shallow 2-layer GNN pipelines to achieve results on par with more complex architectures.
5/29/2024

A Pure Transformer Pretraining Framework on Text-attributed Graphs
Yu Song, Haitao Mao, Jiachen Xiao, Jingzhe Liu, Zhikai Chen, Wei Jin, Carl Yang, Jiliang Tang, Hui Liu
0
0
Pretraining plays a pivotal role in acquiring generalized knowledge from large-scale data, achieving remarkable successes as evidenced by large models in CV and NLP. However, progress in the graph domain remains limited due to fundamental challenges such as feature heterogeneity and structural heterogeneity. Recently, increasing efforts have been made to enhance node feature quality with Large Language Models (LLMs) on text-attributed graphs (TAGs), demonstrating superiority to traditional bag-of-words or word2vec techniques. These high-quality node features reduce the previously critical role of graph structure, resulting in a modest performance gap between Graph Neural Networks (GNNs) and structure-agnostic Multi-Layer Perceptrons (MLPs). Motivated by this, we introduce a feature-centric pretraining perspective by treating graph structure as a prior and leveraging the rich, unified feature space to learn refined interaction patterns that generalizes across graphs. Our framework, Graph Sequence Pretraining with Transformer (GSPT), samples node contexts through random walks and employs masked feature reconstruction to capture pairwise proximity in the LLM-unified feature space using a standard Transformer. By utilizing unified text representations rather than varying structures, our framework achieves significantly better transferability among graphs within the same domain. GSPT can be easily adapted to both node classification and link prediction, demonstrating promising empirical success on various datasets.
6/21/2024