Training-Free Large Model Priors for Multiple-in-One Image Restoration

0

Sign in to get full access
Overview
• This paper proposes a novel approach for all-in-one image restoration that leverages large pre-trained models as priors, without requiring any further training.
• The method, dubbed Training-Free Large Model Priors (TFLMP), demonstrates state-of-the-art performance on a wide range of image restoration tasks, including photo-realistic image restoration, leveraging degradation-aligned language prompts, and unleashing visual prompts for diffusion-based restoration.
Plain English Explanation
The researchers in this paper have developed a new way to restore and improve the quality of images without having to train a model from scratch. Instead, they use large pre-trained models as a starting point, which means the model has already been trained on a massive amount of data and learned to recognize patterns and features in images.
By using these pre-trained models as a base, the researchers can then apply their method to restore a wide variety of image types, such as blurry, noisy, or low-resolution images, without having to train a new model for each specific task. This makes the process much more efficient and accessible, as it doesn't require the time and computational resources needed to train a model from the ground up.
The key innovation in this paper is the "training-free" aspect, which means the researchers don't have to go through the typical machine learning training process to get the model to work for their specific image restoration tasks. Instead, they've found a way to leverage the knowledge and capabilities of the large pre-trained models to achieve state-of-the-art results on a diverse range of image restoration problems.
Technical Explanation
The paper introduces a novel approach called Training-Free Large Model Priors (TFLMP) that leverages the knowledge and capabilities of large pre-trained models to tackle a wide range of image restoration tasks, without the need for any additional training.
The researchers hypothesize that these large pre-trained models, such as diffusion models, have already learned rich and general visual representations that can be effectively used as strong priors for various image restoration problems.
To demonstrate the effectiveness of their approach, the authors conduct extensive experiments on a diverse set of image restoration tasks, including photo-realistic image restoration, leveraging degradation-aligned language prompts, and unleashing visual prompts for diffusion-based restoration. The results show that TFLMP consistently outperforms existing state-of-the-art methods across these diverse tasks, without requiring any further training.
Critical Analysis
The key strength of the TFLMP approach is its ability to leverage the rich visual representations learned by large pre-trained models, without the need for task-specific training. This makes the method highly scalable and efficient, as it can be applied to a wide range of image restoration problems without the computational and time-intensive overhead of retraining a model from scratch.
However, the paper does not provide a detailed analysis of the limitations of the TFLMP approach. It's unclear how the method would perform on more specialized or domain-specific image restoration tasks, where the pre-trained model's knowledge may not be as directly applicable. Additionally, the paper does not explore the interpretability of the TFLMP approach, which could be an important consideration for certain applications.
Further research could also delve into the generalizability of the TFLMP approach, investigating its performance on a broader range of image restoration tasks and its robustness to different types of image degradations. Exploring the combination of TFLMP with task-specific fine-tuning or other complementary techniques could also be a promising avenue for future work.
Conclusion
The Training-Free Large Model Priors (TFLMP) approach proposed in this paper represents a significant advancement in the field of image restoration. By leveraging the powerful visual representations learned by large pre-trained models, the method is able to achieve state-of-the-art performance on a diverse range of image restoration tasks, without the need for any additional training.
This innovative approach has the potential to democratize image restoration, making it more accessible and efficient for a wide range of applications, from photo editing to medical imaging and security surveillance. The ability to apply a single, pre-trained model to multiple restoration tasks could lead to significant cost savings and time savings in various industries.
As the field of machine learning continues to evolve, the TFLMP method serves as an exciting example of how large pre-trained models can be leveraged to tackle complex real-world problems in a scalable and efficient manner. The insights and techniques presented in this paper are likely to inspire further research and innovation in the field of image restoration and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training-Free Large Model Priors for Multiple-in-One Image Restoration
Xuanhua He, Lang Li, Yingying Wang, Hui Zheng, Ke Cao, Keyu Yan, Rui Li, Chengjun Xie, Jie Zhang, Man Zhou
Image restoration aims to reconstruct the latent clear images from their degraded versions. Despite the notable achievement, existing methods predominantly focus on handling specific degradation types and thus require specialized models, impeding real-world applications in dynamic degradation scenarios. To address this issue, we propose Large Model Driven Image Restoration framework (LMDIR), a novel multiple-in-one image restoration paradigm that leverages the generic priors from large multi-modal language models (MMLMs) and the pretrained diffusion models. In detail, LMDIR integrates three key prior knowledges: 1) global degradation knowledge from MMLMs, 2) scene-aware contextual descriptions generated by MMLMs, and 3) fine-grained high-quality reference images synthesized by diffusion models guided by MMLM descriptions. Standing on above priors, our architecture comprises a query-based prompt encoder, degradation-aware transformer block injecting global degradation knowledge, content-aware transformer block incorporating scene description, and reference-based transformer block incorporating fine-grained image priors. This design facilitates single-stage training paradigm to address various degradations while supporting both automatic and user-guided restoration. Extensive experiments demonstrate that our designed method outperforms state-of-the-art competitors on multiple evaluation benchmarks.
Read more7/19/2024

0
Large Language Models for Multimodal Deformable Image Registration
Mingrui Ma, Weijie Wang, Jie Ning, Jianfeng He, Nicu Sebe, Bruno Lepri
The challenge of Multimodal Deformable Image Registration (MDIR) lies in the conversion and alignment of features between images of different modalities. Generative models (GMs) cannot retain the necessary information enough from the source modality to the target one, while non-GMs struggle to align features across these two modalities. In this paper, we propose a novel coarse-to-fine MDIR framework,LLM-Morph, which is applicable to various pre-trained Large Language Models (LLMs) to solve these concerns by aligning the deep features from different modal medical images. Specifically, we first utilize a CNN encoder to extract deep visual features from cross-modal image pairs, then we use the first adapter to adjust these tokens, and use LoRA in pre-trained LLMs to fine-tune their weights, both aimed at eliminating the domain gap between the pre-trained LLMs and the MDIR task. Third, for the alignment of tokens, we utilize other four adapters to transform the LLM-encoded tokens into multi-scale visual features, generating multi-scale deformation fields and facilitating the coarse-to-fine MDIR task. Extensive experiments in MR-CT Abdomen and SR-Reg Brain datasets demonstrate the effectiveness of our framework and the potential of pre-trained LLMs for MDIR task. Our code is availabel at: https://github.com/ninjannn/LLM-Morph.
Read more8/21/2024

0
MRIR: Integrating Multimodal Insights for Diffusion-based Realistic Image Restoration
Yuhong Zhang, Hengsheng Zhang, Xinning Chai, Rong Xie, Li Song, Wenjun Zhang
Realistic image restoration is a crucial task in computer vision, and the use of diffusion-based models for image restoration has garnered significant attention due to their ability to produce realistic results. However, the quality of the generated images is still a significant challenge due to the severity of image degradation and the uncontrollability of the diffusion model. In this work, we delve into the potential of utilizing pre-trained stable diffusion for image restoration and propose MRIR, a diffusion-based restoration method with multimodal insights. Specifically, we explore the problem from two perspectives: textual level and visual level. For the textual level, we harness the power of the pre-trained multimodal large language model to infer meaningful semantic information from low-quality images. Furthermore, we employ the CLIP image encoder with a designed Refine Layer to capture image details as a supplement. For the visual level, we mainly focus on the pixel level control. Thus, we utilize a Pixel-level Processor and ControlNet to control spatial structures. Finally, we integrate the aforementioned control information into the denoising U-Net using multi-level attention mechanisms and realize controllable image restoration with multimodal insights. The qualitative and quantitative results demonstrate our method's superiority over other state-of-the-art methods on both synthetic and real-world datasets.
Read more7/8/2024
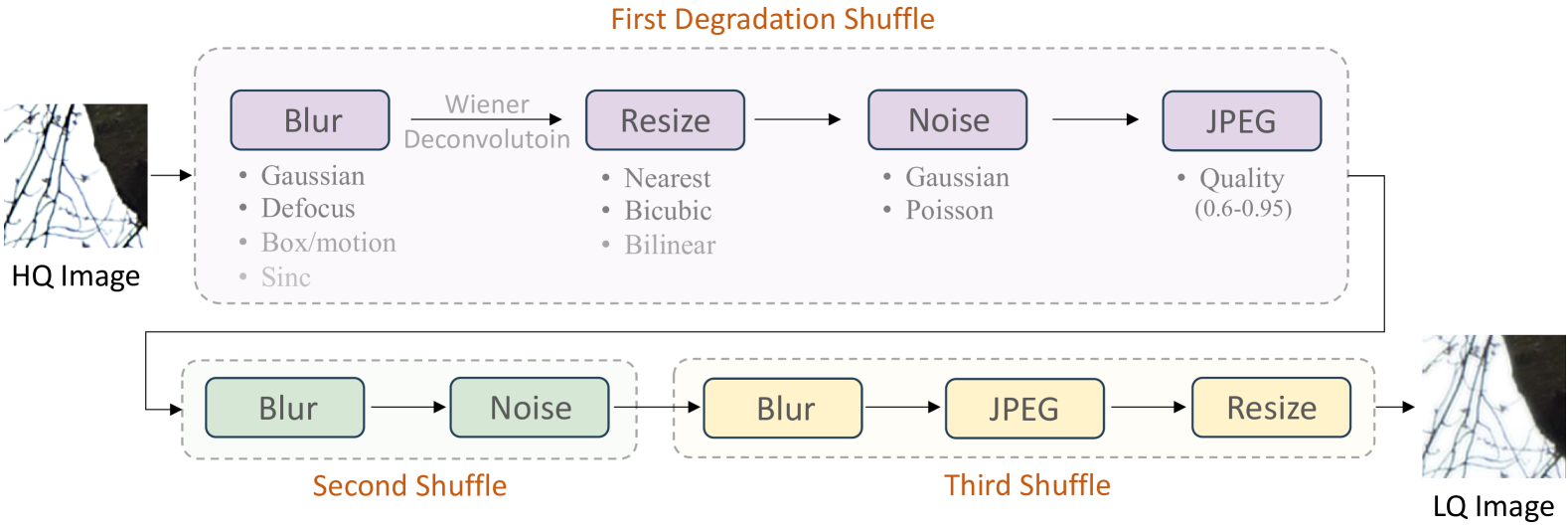
0
Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjolund, Thomas B. Schon
Though diffusion models have been successfully applied to various image restoration (IR) tasks, their performance is sensitive to the choice of training datasets. Typically, diffusion models trained in specific datasets fail to recover images that have out-of-distribution degradations. To address this problem, this work leverages a capable vision-language model and a synthetic degradation pipeline to learn image restoration in the wild (wild IR). More specifically, all low-quality images are simulated with a synthetic degradation pipeline that contains multiple common degradations such as blur, resize, noise, and JPEG compression. Then we introduce robust training for a degradation-aware CLIP model to extract enriched image content features to assist high-quality image restoration. Our base diffusion model is the image restoration SDE (IR-SDE). Built upon it, we further present a posterior sampling strategy for fast noise-free image generation. We evaluate our model on both synthetic and real-world degradation datasets. Moreover, experiments on the unified image restoration task illustrate that the proposed posterior sampling improves image generation quality for various degradations.
Read more4/16/2024