Trajectory Consistency Distillation: Improved Latent Consistency Distillation by Semi-Linear Consistency Function with Trajectory Mapping
2402.19159
0
0

Abstract
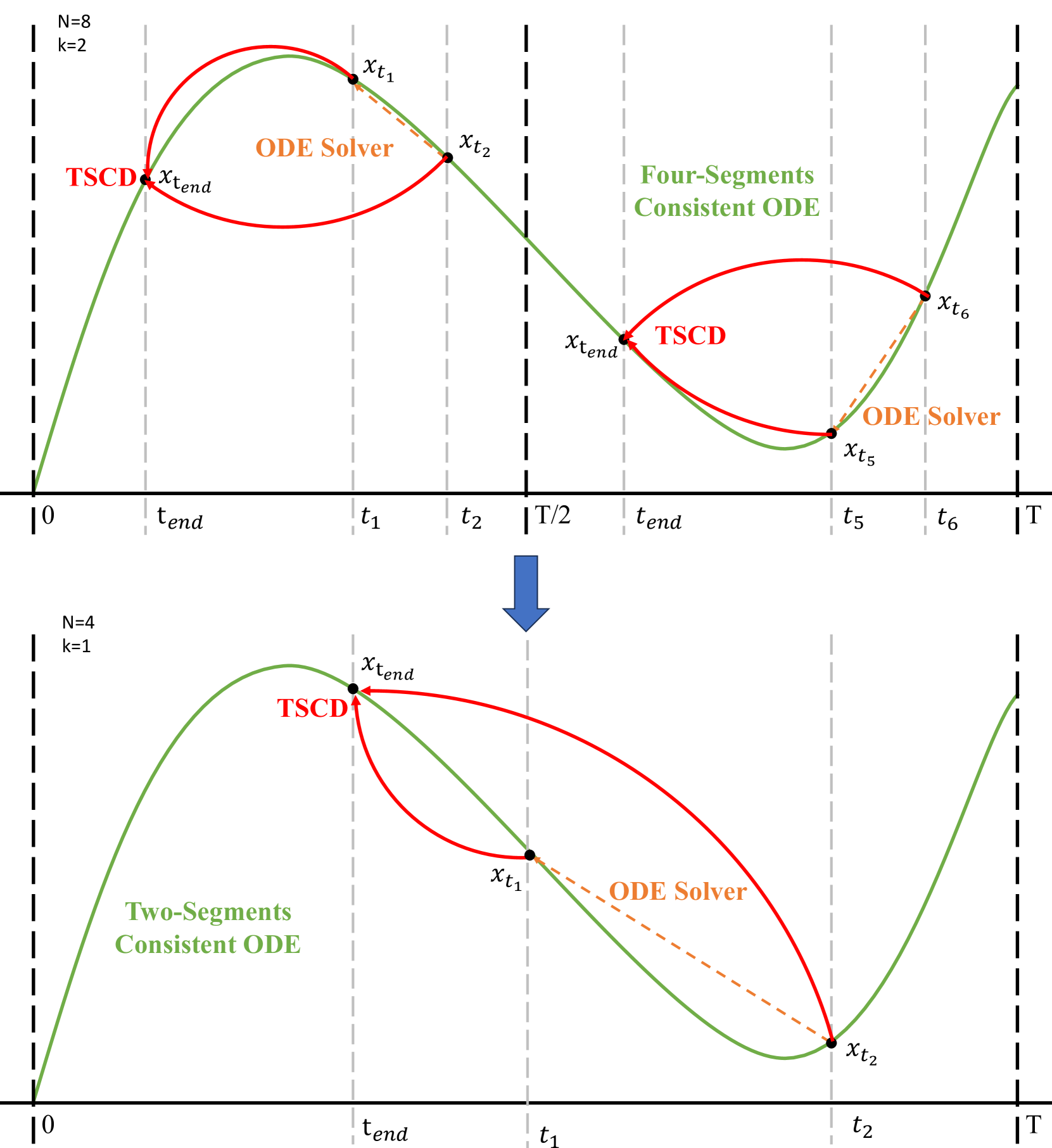
Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the parameterisation and distillation errors by broadening the scope of the self-consistency boundary condition with trajectory mapping and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE in semi-linear form with an Exponential Integrator. Additionally, strategic stochastic sampling provides explicit control of stochastic and circumvents the accumulated errors inherent in multi-step consistency sampling. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Diffusion models are a powerful class of generative AI models that can generate high-quality images from text descriptions.
- This paper introduces a new technique called "Trajectory Consistency Distillation" that can make diffusion models more efficient and accurate.
- The key idea is to train the diffusion model to not just generate the final image, but to match the entire sequence of intermediate steps (or "trajectory") that the model takes to get there.
Plain English Explanation
Diffusion models are a type of AI system that can create new images based on text descriptions. These models work by gradually adding "noise" to an image, then learning how to reverse that process to generate new images.
The paper proposes a new training technique called "Trajectory Consistency Distillation" that can make diffusion models more efficient and accurate. The key idea is to not just train the model to generate the final image, but to also match the entire sequence of intermediate steps the model takes to get there. This helps the model learn a more robust and consistent process for image generation.
By ensuring the model's "trajectory" - the full series of steps it takes - is consistent, it becomes better at generating high-quality images in an efficient manner. This builds on prior work exploring the benefits of "consistency" in diffusion models for faster and more reliable generation.
Technical Explanation
The paper introduces a new training technique called "Trajectory Consistency Distillation" for diffusion models. Diffusion models work by gradually adding noise to an image, then learning to reverse that process to generate new images.
The key innovation is that, in addition to training the model to generate the final image, the authors also train it to match the entire sequence of intermediate steps (the "trajectory") the model takes to get there. This "semantic approach to quantifying consistency in diffusion models" helps the model learn a more robust and consistent image generation process.
Experiments show this Trajectory Consistency Distillation technique leads to faster, more efficient, and more accurate diffusion models compared to standard training. The authors also introduce a new "ConsistencyDet" model that applies these consistency principles to improve object detection.
Critical Analysis
The paper presents a strong technical contribution in advancing diffusion model training. The Trajectory Consistency Distillation technique is a clever and well-motivated idea that builds on prior work in this area.
One potential limitation is that the additional training overhead of matching the full trajectory may limit applicability to very large or computationally constrained models. The authors acknowledge this and suggest future work to reduce the computational burden.
Additionally, the paper does not deeply explore the underlying reasons why trajectory consistency leads to better performance. More analysis of the learned model dynamics and failure modes could provide additional insights.
Overall, this is a technically robust and impactful piece of research that pushes the state-of-the-art in diffusion models. The consistency principles introduced here are likely to have broader applicability beyond just image generation tasks.
Conclusion
This paper introduces a new "Trajectory Consistency Distillation" training technique for diffusion models that improves their efficiency, accuracy, and robustness. By ensuring the model's full generative process is consistent, rather than just the final output, the technique leads to better performing diffusion models.
The work builds on and advances prior research exploring consistency in generative models, with potential applications beyond just image generation. While there are some practical limitations to consider, this is an important contribution that pushes the field of diffusion models forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, Xuefeng Xiao
0
0
Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
4/23/2024
🛸
Efficient Text-driven Motion Generation via Latent Consistency Training
Mengxian Hu, Minghao Zhu, Xun Zhou, Qingqing Yan, Shu Li, Chengju Liu, Qijun Chen
0
0
Motion diffusion models have recently proven successful for text-driven human motion generation. Despite their excellent generation performance, they are challenging to infer in real time due to the multi-step sampling mechanism that involves tens or hundreds of repeat function evaluation iterations. To this end, we investigate a motion latent consistency Training (MLCT) for motion generation to alleviate the computation and time consumption during iteration inference. It applies diffusion pipelines to low-dimensional motion latent spaces to mitigate the computational burden of each function evaluation. Explaining the diffusion process with probabilistic flow ordinary differential equation (PF-ODE) theory, the MLCT allows extremely few steps infer between the prior distribution to the motion latent representation distribution via maintaining consistency of the outputs over the trajectory of PF-ODE. Especially, we introduce a quantization constraint to optimize motion latent representations that are bounded, regular, and well-reconstructed compared to traditional variational constraints. Furthermore, we propose a conditional PF-ODE trajectory simulation method, which improves the conditional generation performance with minimal additional training costs. Extensive experiments on two human motion generation benchmarks show that the proposed model achieves state-of-the-art performance with less than 10% time cost.
5/7/2024

SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Hongjian Liu, Qingsong Xie, Zhijie Deng, Chen Chen, Shixiang Tang, Fueyang Fu, Zheng-jun Zha, Haonan Lu
0
0
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
4/16/2024
🛸
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
Wenxun Dai, Ling-Hao Chen, Jingbo Wang, Jinpeng Liu, Bo Dai, Yansong Tang
0
0
This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial control in text-conditioned motion generation suffer from significant runtime inefficiency. To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building upon the latent diffusion model (MLD). By employing one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation. To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (e.g., pelvis trajectory) in the vanilla motion space to control the generation process directly, similar to controlling other latent-free diffusion models for motion generation. By employing these techniques, our approach can generate human motions with text and control signals in real-time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.
5/1/2024