TrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation

0

Sign in to get full access
Overview
- Introduces TrAME, a new method for editing 3D Gaussian splats using text prompts
- Allows for multi-view consistent editing by leveraging trajectory information
- Designed to enable intuitive and flexible 3D content manipulation
Plain English Explanation
The paper presents a new technique called TrAME (Trajectory-Anchored Multi-View Editing) that allows users to edit 3D content, such as virtual scenes or models, using text-based instructions.
The key innovation of TrAME is that it takes into account the trajectories, or movement paths, of the 3D elements when making edits. This ensures that the changes made in one view of the 3D content are consistently reflected across multiple viewpoints. For example, if you instruct the system to "make the object bigger," it will scale the object appropriately while maintaining its shape and position relative to the rest of the scene when viewed from different angles.
This multi-view consistency is achieved by leveraging the trajectory information of the 3D elements. The system understands how the elements are moving and positioned within the 3D space, allowing it to apply edits in a way that preserves the overall spatial relationships.
The text-based editing approach of TrAME is designed to be intuitive and accessible, enabling users to express their desired changes using natural language prompts, rather than having to manually manipulate the 3D content directly. This makes the 3D editing process more user-friendly and flexible.
Technical Explanation
The TrAME method works by first representing the 3D content as a collection of Gaussian splats, which are essentially 3D data points with associated probability distributions. This Gaussian splatting representation allows for efficient processing and manipulation of the 3D elements.
The key component of TrAME is the Trajectory-Anchored Editing module, which uses the trajectory information of the 3D elements to ensure multi-view consistency during the editing process. This module maps the text-based editing instructions to the appropriate transformations (e.g., scaling, rotation, translation) that should be applied to the Gaussian splats, while preserving their spatial relationships.
The Multi-View Consistency component of TrAME further enhances the editing experience by generating consistent edits across multiple viewpoints of the 3D scene. This is achieved by optimizing the editing parameters to minimize the differences between the edited views, ensuring a coherent and visually pleasing result.
The Text-Guided Editing mechanism allows users to provide natural language instructions to the system, which are then interpreted and translated into the appropriate 3D editing operations.
Critical Analysis
The paper acknowledges that the Gaussian splatting representation may not be suitable for all types of 3D content, and that further research is needed to explore alternative representations that could expand the applicability of the TrAME method.
Additionally, the text-based editing approach, while intuitive, may have limitations in terms of the complexity and specificity of the edits that can be expressed through natural language prompts. Exploring more advanced language understanding techniques could potentially enhance the flexibility and precision of the text-guided editing capabilities.
Conclusion
The TrAME method represents a significant advance in the field of 3D content manipulation, as it enables users to edit 3D scenes in a more intuitive and multi-view consistent manner using text-based instructions. By leveraging trajectory information and Gaussian splatting, TrAME offers a promising approach to enhancing the accessibility and flexibility of 3D editing workflows, which could have valuable applications in various domains, such as virtual environments, 3D modeling, and content creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation
Chaofan Luo, Donglin Di, Xun Yang, Yongjia Ma, Zhou Xue, Chen Wei, Yebin Liu
Despite significant strides in the field of 3D scene editing, current methods encounter substantial challenge, particularly in preserving 3D consistency in multi-view editing process. To tackle this challenge, we propose a progressive 3D editing strategy that ensures multi-view consistency via a Trajectory-Anchored Scheme (TAS) with a dual-branch editing mechanism. Specifically, TAS facilitates a tightly coupled iterative process between 2D view editing and 3D updating, preventing error accumulation yielded from text-to-image process. Additionally, we explore the relationship between optimization-based methods and reconstruction-based methods, offering a unified perspective for selecting superior design choice, supporting the rationale behind the designed TAS. We further present a tuning-free View-Consistent Attention Control (VCAC) module that leverages cross-view semantic and geometric reference from the source branch to yield aligned views from the target branch during the editing of 2D views. To validate the effectiveness of our method, we analyze 2D examples to demonstrate the improved consistency with the VCAC module. Further extensive quantitative and qualitative results in text-guided 3D scene editing indicate that our method achieves superior editing quality compared to state-of-the-art methods. We will make the complete codebase publicly available following the conclusion of the review process.
Read more8/22/2024

0
View-Consistent 3D Editing with Gaussian Splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, Hanwang Zhang
The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations. Currently, diffusion-based 2D editing models are harnessed to modify multi-view rendered images, which then guide the editing of 3DGS models. However, this approach faces a critical issue of multi-view inconsistency, where the guidance images exhibit significant discrepancies across views, leading to mode collapse and visual artifacts of 3DGS. To this end, we introduce View-consistent Editing (VcEdit), a novel framework that seamlessly incorporates 3DGS into image editing processes, ensuring multi-view consistency in edited guidance images and effectively mitigating mode collapse issues. VcEdit employs two innovative consistency modules: the Cross-attention Consistency Module and the Editing Consistency Module, both designed to reduce inconsistencies in edited images. By incorporating these consistency modules into an iterative pattern, VcEdit proficiently resolves the issue of multi-view inconsistency, facilitating high-quality 3DGS editing across a diverse range of scenes. Further code and video results are re- leased at http://yuxuanw.me/vcedit/.
Read more5/22/2024

0
GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Jing Wu, Jia-Wang Bian, Xinghui Li, Guangrun Wang, Ian Reid, Philip Torr, Victor Adrian Prisacariu
We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS). Our method first renders a collection of images by using the 3DGS and edits them by using a pre-trained 2D diffusion model (ControlNet) based on the input prompt, which is then used to optimise the 3D model. Our key contribution is multi-view consistent editing, which enables editing all images together instead of iteratively editing one image while updating the 3D model as in previous works. It leads to faster editing as well as higher visual quality. This is achieved by the two terms: (a) depth-conditioned editing that enforces geometric consistency across multi-view images by leveraging naturally consistent depth maps. (b) attention-based latent code alignment that unifies the appearance of edited images by conditioning their editing to several reference views through self and cross-view attention between images' latent representations. Experiments demonstrate that our method achieves faster editing and better visual results than previous state-of-the-art methods.
Read more7/16/2024
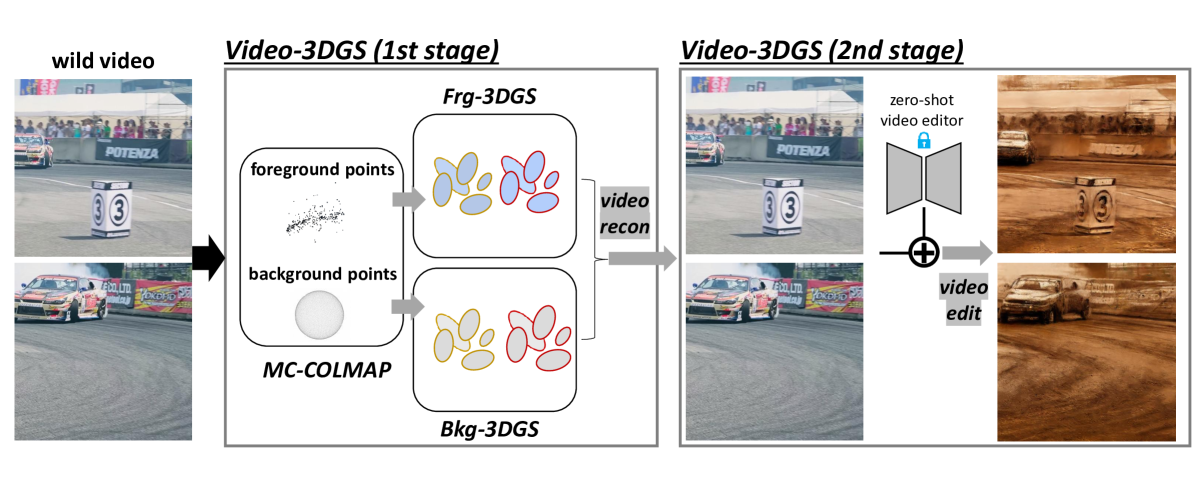
0
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Inkyu Shin, Qihang Yu, Xiaohui Shen, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
Read more6/7/2024