Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
2406.02541
0
0
Abstract
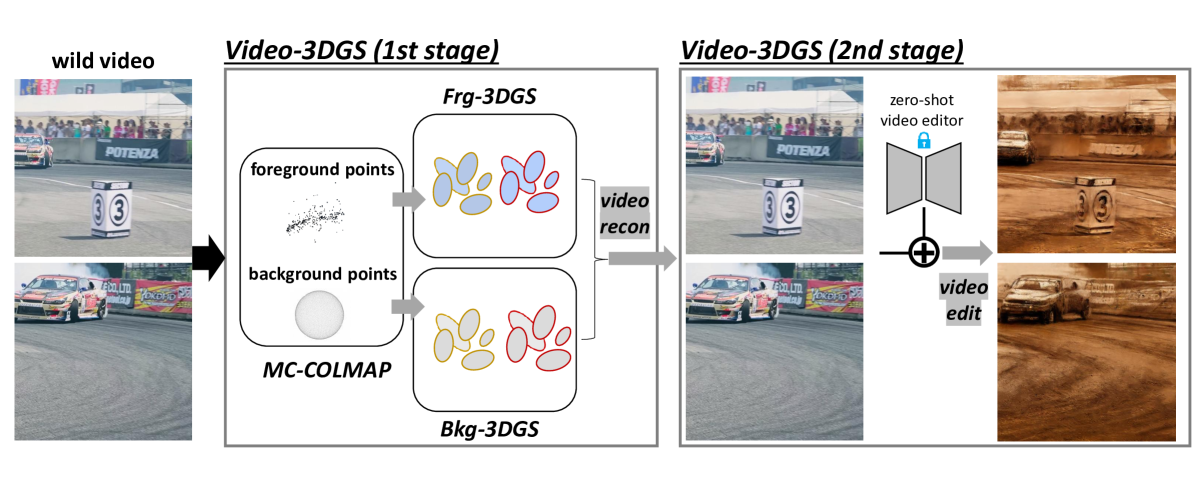
Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
Create account to get full access
Overview
- This paper presents a novel method for enhancing the temporal consistency of video editing by reconstructing videos using 3D Gaussian splatting.
- The proposed approach aims to address the issue of temporal inconsistencies that can arise during video editing, where changes made to individual frames may not seamlessly integrate with the surrounding frames.
- The method leverages the view-consistent 3D editing with Gaussian splatting technique to reconstruct the video and self-calibrating 4D novel view synthesis to generate temporally consistent outputs.
- The authors also introduce a robust Gaussian splatting technique and a GS-SLAM method for dense visual SLAM with 3D Gaussian splatting.
- Additionally, the paper explores the use of CLIP-GS, a CLIP-informed Gaussian splatting approach, for real-world applications.
Plain English Explanation
The paper focuses on improving the consistency of video editing over time. When you edit a video, changes made to individual frames may not always blend seamlessly with the surrounding frames, leading to a jarring or inconsistent viewing experience. The researchers developed a method that uses 3D Gaussian splatting to reconstruct the entire video, which helps ensure that any edits are integrated more smoothly across the entire sequence of frames.
The key idea is to treat the video as a 3D space, with two spatial dimensions and one temporal dimension. By using 3D Gaussian splatting, the method can capture the relationships between pixels not just within a single frame, but also across multiple frames. This allows the system to maintain a consistent visual appearance even when changes are made to individual frames.
To achieve this, the researchers built upon several existing techniques, including view-consistent 3D editing, self-calibrating 4D novel view synthesis, robust Gaussian splatting, and a dense visual SLAM (Simultaneous Localization and Mapping) method that uses 3D Gaussian splatting. They also explored the use of CLIP-GS, which combines a powerful image recognition model (CLIP) with Gaussian splatting, for real-world applications.
By combining these various techniques, the researchers were able to develop a system that can reconstruct videos in a way that preserves the temporal consistency, even when significant edits are made to the content.
Technical Explanation
The paper presents a method for enhancing the temporal consistency of video editing by reconstructing videos using 3D Gaussian splatting. The key elements of the approach are as follows:
-
View-consistent 3D Editing with Gaussian Splatting: The researchers build upon the view-consistent 3D editing with Gaussian splatting technique, which allows for 3D-aware editing of videos while preserving view consistency.
-
Self-calibrating 4D Novel View Synthesis: The method utilizes the self-calibrating 4D novel view synthesis approach to generate temporally consistent outputs from the reconstructed 3D video.
-
Robust Gaussian Splatting: The authors introduce a robust Gaussian splatting technique that improves the quality and efficiency of the splatting process.
-
GS-SLAM for Dense Visual SLAM: The paper also presents a GS-SLAM method for dense visual SLAM with 3D Gaussian splatting, which provides the necessary 3D information for the video reconstruction.
-
CLIP-GS for Real-world Applications: The researchers explore the use of CLIP-GS, a CLIP-informed Gaussian splatting approach, for applying the method to real-world video editing scenarios.
By combining these various techniques, the proposed method is able to reconstruct videos in a way that enhances the temporal consistency, even when significant edits are made to the content. This helps to ensure a more seamless and visually cohesive viewing experience for the audience.
Critical Analysis
The paper provides a comprehensive approach to enhancing the temporal consistency of video editing, addressing several key challenges in this area. The authors have built upon a range of existing techniques, including view-consistent 3D editing, self-calibrating 4D novel view synthesis, robust Gaussian splatting, and dense visual SLAM with 3D Gaussian splatting.
One potential limitation of the method is its computational complexity, as the video reconstruction process may be resource-intensive, especially for longer or higher-resolution video content. The authors acknowledge this and suggest that further optimizations may be necessary for real-time or large-scale applications.
Additionally, the paper does not provide a detailed evaluation of the method's performance in real-world video editing scenarios, such as its ability to handle complex camera movements, occlusions, or diverse video content. Further research and user studies may be needed to fully assess the method's practical impact and identify any potential edge cases or limitations.
It would also be interesting to explore the integration of the proposed technique with other video editing tools and workflows, as well as its potential applications in areas such as video content creation, visual effects, or virtual production.
Conclusion
The paper presents a novel method for enhancing the temporal consistency of video editing by reconstructing videos using 3D Gaussian splatting. The approach leverages a range of existing techniques, including view-consistent 3D editing, self-calibrating 4D novel view synthesis, robust Gaussian splatting, and dense visual SLAM with 3D Gaussian splatting, to achieve this goal.
The key contribution of the paper is the development of a comprehensive system that can maintain visual coherence and temporal consistency even when significant edits are made to video content. This has the potential to significantly improve the quality and seamlessness of video editing workflows, ultimately providing a better viewing experience for audiences.
While the method may face some computational challenges, the authors have demonstrated its effectiveness and laid the groundwork for further research and development in this area. By continuing to refine and optimize the technique, the researchers may be able to unlock new possibilities for video editing and content creation, with applications across a wide range of industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

View-Consistent 3D Editing with Gaussian Splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, Hanwang Zhang
0
0
The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations. Currently, diffusion-based 2D editing models are harnessed to modify multi-view rendered images, which then guide the editing of 3DGS models. However, this approach faces a critical issue of multi-view inconsistency, where the guidance images exhibit significant discrepancies across views, leading to mode collapse and visual artifacts of 3DGS. To this end, we introduce View-consistent Editing (VcEdit), a novel framework that seamlessly incorporates 3DGS into image editing processes, ensuring multi-view consistency in edited guidance images and effectively mitigating mode collapse issues. VcEdit employs two innovative consistency modules: the Cross-attention Consistency Module and the Editing Consistency Module, both designed to reduce inconsistencies in edited images. By incorporating these consistency modules into an iterative pattern, VcEdit proficiently resolves the issue of multi-view inconsistency, facilitating high-quality 3DGS editing across a diverse range of scenes. Further code and video results are re- leased at http://yuxuanw.me/vcedit/.
5/22/2024

Self-Calibrating 4D Novel View Synthesis from Monocular Videos Using Gaussian Splatting
Fang Li, Hao Zhang, Narendra Ahuja
0
0
Gaussian Splatting (GS) has significantly elevated scene reconstruction efficiency and novel view synthesis (NVS) accuracy compared to Neural Radiance Fields (NeRF), particularly for dynamic scenes. However, current 4D NVS methods, whether based on GS or NeRF, primarily rely on camera parameters provided by COLMAP and even utilize sparse point clouds generated by COLMAP for initialization, which lack accuracy as well are time-consuming. This sometimes results in poor dynamic scene representation, especially in scenes with large object movements, or extreme camera conditions e.g. small translations combined with large rotations. Some studies simultaneously optimize the estimation of camera parameters and scenes, supervised by additional information like depth, optical flow, etc. obtained from off-the-shelf models. Using this unverified information as ground truth can reduce robustness and accuracy, which does frequently occur for long monocular videos (with e.g. > hundreds of frames). We propose a novel approach that learns a high-fidelity 4D GS scene representation with self-calibration of camera parameters. It includes the extraction of 2D point features that robustly represent 3D structure, and their use for subsequent joint optimization of camera parameters and 3D structure towards overall 4D scene optimization. We demonstrate the accuracy and time efficiency of our method through extensive quantitative and qualitative experimental results on several standard benchmarks. The results show significant improvements over state-of-the-art methods for 4D novel view synthesis. The source code will be released soon at https://github.com/fangli333/SC-4DGS.
6/4/2024

Robust Gaussian Splatting
Franc{c}ois Darmon, Lorenzo Porzi, Samuel Rota-Bul`o, Peter Kontschieder
0
0
In this paper, we address common error sources for 3D Gaussian Splatting (3DGS) including blur, imperfect camera poses, and color inconsistencies, with the goal of improving its robustness for practical applications like reconstructions from handheld phone captures. Our main contribution involves modeling motion blur as a Gaussian distribution over camera poses, allowing us to address both camera pose refinement and motion blur correction in a unified way. Additionally, we propose mechanisms for defocus blur compensation and for addressing color in-consistencies caused by ambient light, shadows, or due to camera-related factors like varying white balancing settings. Our proposed solutions integrate in a seamless way with the 3DGS formulation while maintaining its benefits in terms of training efficiency and rendering speed. We experimentally validate our contributions on relevant benchmark datasets including Scannet++ and Deblur-NeRF, obtaining state-of-the-art results and thus consistent improvements over relevant baselines.
4/8/2024

Event3DGS: Event-based 3D Gaussian Splatting for Fast Egomotion
Tianyi Xiong, Jiayi Wu, Botao He, Cornelia Fermuller, Yiannis Aloimonos, Heng Huang, Christopher A. Metzler
0
0
By combining differentiable rendering with explicit point-based scene representations, 3D Gaussian Splatting (3DGS) has demonstrated breakthrough 3D reconstruction capabilities. However, to date 3DGS has had limited impact on robotics, where high-speed egomotion is pervasive: Egomotion introduces motion blur and leads to artifacts in existing frame-based 3DGS reconstruction methods. To address this challenge, we introduce Event3DGS, an {em event-based} 3DGS framework. By exploiting the exceptional temporal resolution of event cameras, Event3GDS can reconstruct high-fidelity 3D structure and appearance under high-speed egomotion. Extensive experiments on multiple synthetic and real-world datasets demonstrate the superiority of Event3DGS compared with existing event-based dense 3D scene reconstruction frameworks; Event3DGS substantially improves reconstruction quality (+3dB) while reducing computational costs by 95%. Our framework also allows one to incorporate a few motion-blurred frame-based measurements into the reconstruction process to further improve appearance fidelity without loss of structural accuracy.
6/19/2024