Transcrib3D: 3D Referring Expression Resolution through Large Language Models
2404.19221
0
0

Abstract
If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging -- it requires the ability to both parse the 3D structure of the scene and correctly ground free-form language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Project site is at https://ripl.github.io/Transcrib3D.
Create account to get full access
Overview
- Presents a novel method called Transcrib3D for resolving 3D referring expressions using large language models
- Demonstrates how language models can be used to ground and understand 3D object references in complex scenes
- Outlines a technique for fine-tuning language models to perform 3D referring expression resolution effectively
Plain English Explanation
Transcrib3D is a new approach that allows computers to better understand how people refer to 3D objects in complex, three-dimensional environments. This is an important ability, as being able to interpret and respond to how humans describe objects around them is key for applications like augmented reality, robotics, and other interactive technologies.
The core idea behind Transcrib3D is to use large language models - powerful AI systems trained on massive amounts of text data - to ground and make sense of how people refer to 3D objects. By fine-tuning these language models on relevant datasets, the researchers show they can get the models to accurately locate and identify the specific objects a person is describing, even in cluttered, three-dimensional scenes.
This is a significant advancement, as previous methods for 3D referring expression resolution often struggled with complex real-world scenarios. By leveraging the impressive language understanding capabilities of large language models, Transcrib3D demonstrates a more robust and flexible approach to this challenge.
Technical Explanation
The Transcrib3D paper outlines a novel technique for 3D referring expression resolution that relies on fine-tuning large language models. The authors first construct a dataset of 3D scenes with associated referring expressions, which they use to train and evaluate their model.
The core of their approach is to take a pre-trained language model, such as BERT or GPT, and fine-tune it on the 3D referring expression dataset. This allows the model to learn the associations between the linguistic descriptions and the corresponding 3D objects and locations. At inference time, the model can then take a new referring expression as input and output the most likely 3D referent within the scene.
The authors experiment with different fine-tuning approaches and architectural modifications, and find that their Transcrib3D model outperforms previous state-of-the-art methods on 3D referring expression resolution tasks. They attribute this success to the language model's strong grasp of semantics and context, which enables more robust and flexible 3D grounding.
Critical Analysis
The Transcrib3D paper presents a compelling approach to the challenging problem of 3D referring expression resolution. By leveraging the impressive language understanding capabilities of large language models, the authors demonstrate a significant advance over previous methods.
That said, the paper does acknowledge some limitations of their current work. For example, the authors note that their model may struggle with rare or unfamiliar referring expressions, and that incorporating additional modalities (e.g. visual features) could further improve performance.
Additionally, while the results on the authors' curated dataset are strong, it remains to be seen how well the Transcrib3D approach would generalize to more diverse, real-world scenarios. Rigorous testing on a broader range of 3D environments and referring expressions would help validate the broader applicability of this technique.
Overall, the Transcrib3D paper presents an intriguing new direction for 3D referring expression resolution that warrants further exploration and refinement. As language models continue to advance, the potential to apply their powerful semantic understanding to grounding 3D objects and scenes is an exciting frontier.
Conclusion
The Transcrib3D paper introduces a novel approach to the challenge of 3D referring expression resolution that leverages large language models. By fine-tuning these powerful AI systems on relevant datasets, the researchers demonstrate significant improvements over prior methods, highlighting the potential of language understanding to ground and make sense of complex 3D scenes.
As interactive technologies like augmented reality and robotics continue to advance, the ability to reliably interpret how humans describe their 3D environments will become increasingly important. The Transcrib3D work represents an important step forward in this direction, and the authors' emphasis on the flexibility and robustness of their language model-based approach suggests exciting possibilities for future research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
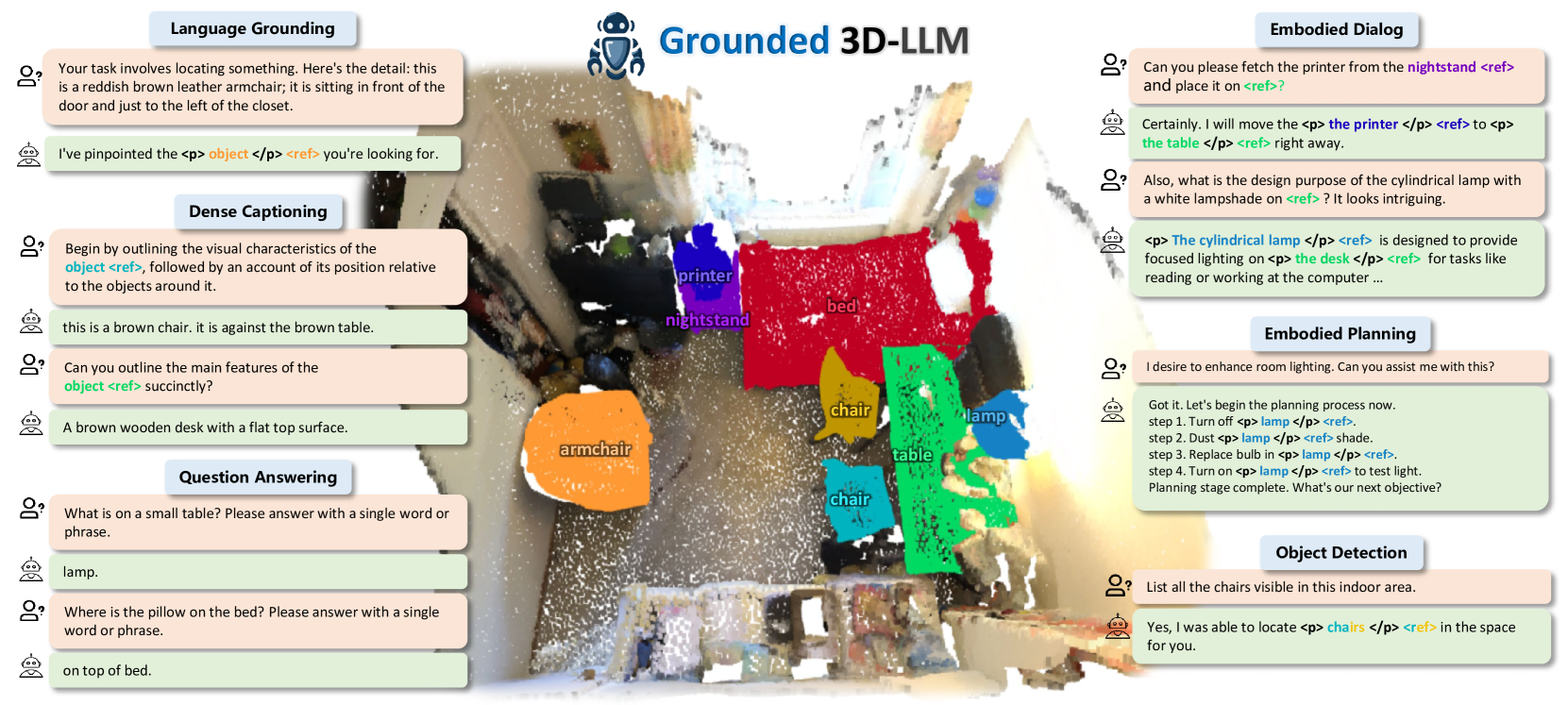
Grounded 3D-LLM with Referent Tokens
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang
0
0
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
5/20/2024
💬
Think-Program-reCtify: 3D Situated Reasoning with Large Language Models
Qingrong He, Kejun Lin, Shizhe Chen, Anwen Hu, Qin Jin
0
0
This work addresses the 3D situated reasoning task which aims to answer questions given egocentric observations in a 3D environment. The task remains challenging as it requires comprehensive 3D perception and complex reasoning skills. End-to-end models trained on supervised data for 3D situated reasoning suffer from data scarcity and generalization ability. Inspired by the recent success of leveraging large language models (LLMs) for visual reasoning, we propose LLM-TPC, a novel framework that leverages the planning, tool usage, and reflection capabilities of LLMs through a ThinkProgram-reCtify loop. The Think phase first decomposes the compositional question into a sequence of steps, and then the Program phase grounds each step to a piece of code and calls carefully designed 3D visual perception modules. Finally, the Rectify phase adjusts the plan and code if the program fails to execute. Experiments and analysis on the SQA3D benchmark demonstrate the effectiveness, interpretability and robustness of our method. Our code is publicly available at https://qingrongh.github.io/LLM-TPC/.
4/24/2024

Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
0
0
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
5/28/2024
🌿
Talk2Radar: Bridging Natural Language with 4D mmWave Radar for 3D Referring Expression Comprehension
Runwei Guan, Ruixiao Zhang, Ningwei Ouyang, Jianan Liu, Ka Lok Man, Xiaohao Cai, Ming Xu, Jeremy Smith, Eng Gee Lim, Yutao Yue, Hui Xiong
0
0
Embodied perception is essential for intelligent vehicles and robots, enabling more natural interaction and task execution. However, these advancements currently embrace vision level, rarely focusing on using 3D modeling sensors, which limits the full understanding of surrounding objects with multi-granular characteristics. Recently, as a promising automotive sensor with affordable cost, 4D Millimeter-Wave radar provides denser point clouds than conventional radar and perceives both semantic and physical characteristics of objects, thus enhancing the reliability of perception system. To foster the development of natural language-driven context understanding in radar scenes for 3D grounding, we construct the first dataset, Talk2Radar, which bridges these two modalities for 3D Referring Expression Comprehension. Talk2Radar contains 8,682 referring prompt samples with 20,558 referred objects. Moreover, we propose a novel model, T-RadarNet for 3D REC upon point clouds, achieving state-of-the-art performances on Talk2Radar dataset compared with counterparts, where Deformable-FPN and Gated Graph Fusion are meticulously designed for efficient point cloud feature modeling and cross-modal fusion between radar and text features, respectively. Further, comprehensive experiments are conducted to give a deep insight into radar-based 3D REC. We release our project at https://github.com/GuanRunwei/Talk2Radar.
5/22/2024