Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
2406.08914
0
0

Abstract
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Create account to get full access
Overview
- This paper explores improving automatic speech recognition (ASR) systems in noisy and reverberant environments by fine-tuning speech separation models without transcription data.
- The researchers developed a transcription-free fine-tuning approach that can adapt speech separation models to handle challenging acoustic conditions, leading to better ASR performance.
- This work was supported by the Centre for Doctoral Training in Speech and Language Technologies (SLT) and their Applications, as well as Solventum and Toshiba Cambridge Research Laboratory.
Plain English Explanation
Speech recognition systems often struggle in real-world environments with background noise, echoes, and multiple speakers. This paper presents a new way to improve these systems without relying on expensive transcribed speech data.
The key idea is to "fine-tune" or adapt pre-trained speech separation models to the specific acoustic conditions of a given environment. Speech separation models can isolate individual speakers from a mixed audio signal, which is crucial for accurate speech recognition. By fine-tuning these models without needing full transcriptions, the researchers found they could significantly boost the performance of automatic speech recognition in challenging noisy and reverberant settings.
This is an important advance, as obtaining large datasets of transcribed speech for model training is a major bottleneck. The approach described in this paper provides an efficient way to adapt speech separation and recognition systems to new environments, potentially making high-quality speech interfaces more accessible in real-world applications.
Technical Explanation
The paper proposes a "transcription-free fine-tuning" approach to adapt pre-trained speech separation models for improved automatic speech recognition (ASR) in noisy and reverberant conditions.
The researchers used a pre-trained speech separation model as the starting point. This model was then fine-tuned using only the raw mixed audio signals, without requiring any transcribed speech data. The fine-tuning process allows the speech separation model to better handle the specific acoustic characteristics of the target environment, such as background noise and room reverberation.
Once the speech separation model was fine-tuned, it was used to preprocess the input audio for an off-the-shelf ASR system. By isolating the individual speaker signals, the ASR system could focus on recognizing speech more accurately, even in challenging acoustic conditions.
The authors evaluated their approach on both simulated and real-world noisy and reverberant multi-speaker datasets. They found that their transcription-free fine-tuning method led to significant improvements in ASR performance compared to using the original pre-trained speech separation model or adapting the ASR system alone.
Critical Analysis
The key strength of this work is the ability to adapt speech separation models to new environments without requiring costly transcribed data. This is an important advancement, as data collection and annotation are major bottlenecks for building robust speech recognition systems.
That said, the paper does not fully explore the limits of this transcription-free fine-tuning approach. The experiments were conducted on relatively small datasets, and it's unclear how well the method would scale to larger, more diverse acoustic conditions. Additionally, the paper does not provide a thorough analysis of the types of acoustic environments where this approach works best.
Further research could investigate the performance of this technique on a wider range of noisy and reverberant scenarios, as well as explore alternative fine-tuning strategies or architectural modifications to improve robustness. Integrating this transcription-free fine-tuning approach with other techniques, such as keyword-guided adaptation or neural blind source separation, could also lead to even greater improvements in multi-speaker ASR performance.
Conclusion
This paper presents a novel approach for fine-tuning pre-trained speech separation models without relying on transcribed speech data. By adapting the speech separation models to specific acoustic environments, the researchers were able to significantly improve the performance of automatic speech recognition in noisy and reverberant settings.
This work represents an important step towards building more robust and accessible speech interfaces that can operate effectively in real-world conditions, without the need for extensive data collection and annotation. As speech recognition systems become more widely deployed, techniques like this transcription-free fine-tuning can help make high-quality speech interfaces more attainable, benefiting a wide range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
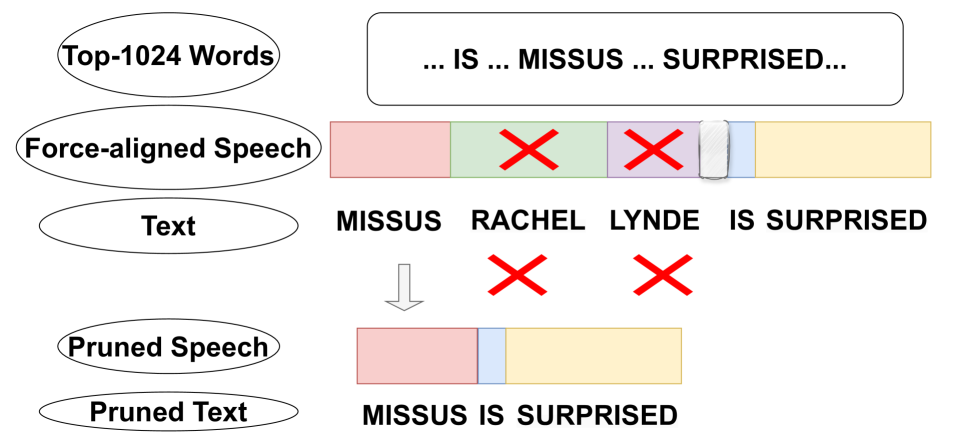
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
0
0
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
6/13/2024

Noise-robust Speech Separation with Fast Generative Correction
Helin Wang, Jesus Villalba, Laureano Moro-Velazquez, Jiarui Hai, Thomas Thebaud, Najim Dehak
0
0
Speech separation, the task of isolating multiple speech sources from a mixed audio signal, remains challenging in noisy environments. In this paper, we propose a generative correction method to enhance the output of a discriminative separator. By leveraging a generative corrector based on a diffusion model, we refine the separation process for single-channel mixture speech by removing noises and perceptually unnatural distortions. Furthermore, we optimize the generative model using a predictive loss to streamline the diffusion model's reverse process into a single step and rectify any associated errors by the reverse process. Our method achieves state-of-the-art performance on the in-domain Libri2Mix noisy dataset, and out-of-domain WSJ with a variety of noises, improving SI-SNR by 22-35% relative to SepFormer, demonstrating robustness and strong generalization capabilities.
6/12/2024

Keyword-Guided Adaptation of Automatic Speech Recognition
Aviv Shamsian, Aviv Navon, Neta Glazer, Gill Hetz, Joseph Keshet
0
0
Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
6/6/2024
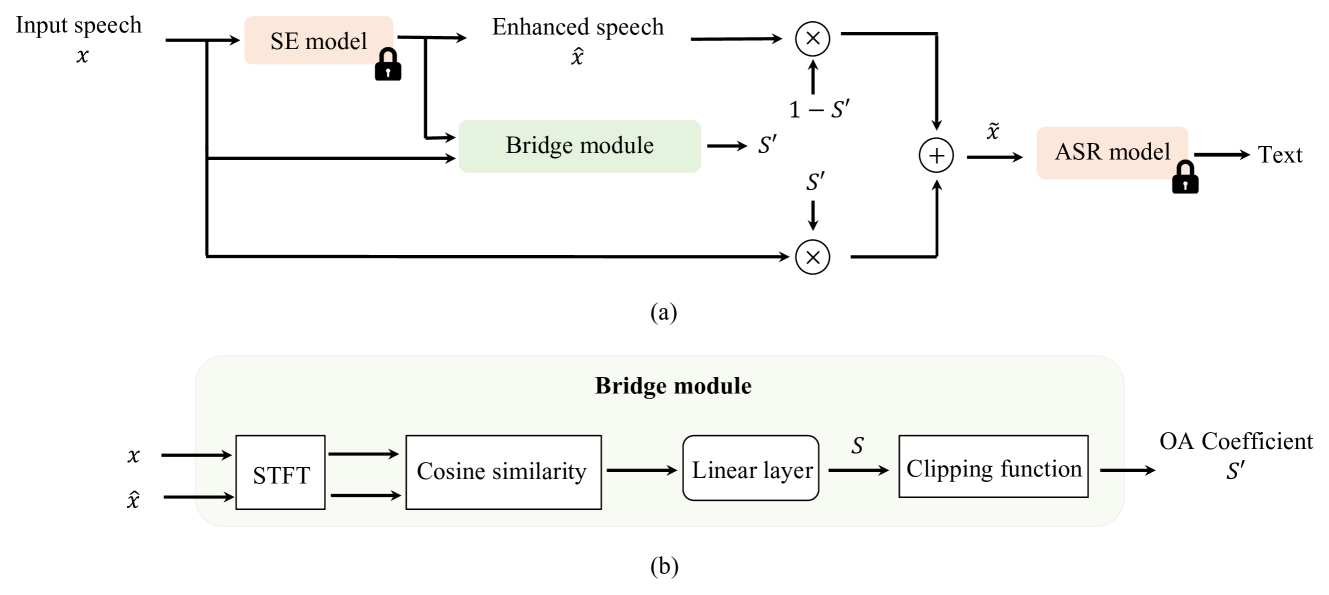
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024