Towards Unsupervised Speech Recognition Without Pronunciation Models

0
Sign in to get full access
Overview
- This paper explores a new approach to unsupervised speech recognition that does not rely on pronunciation models.
- The key idea is to use self-supervised learning to extract useful speech representations without the need for labeled data or a predefined pronunciation lexicon.
- The proposed method aims to advance the field of speech recognition by reducing the need for costly manual annotations and hand-crafted resources.
Plain English Explanation
In the world of speech recognition, traditional approaches often require a lot of manual work. Developers need to create specialized dictionaries that map spoken sounds to written words. This can be a time-consuming and expensive process.
The researchers behind this paper wanted to find a better way. They developed a new technique that can learn to recognize speech without needing those carefully curated pronunciation models. Instead, the system uses a <u>,self-supervised learning,</u> approach to automatically discover useful patterns in the speech data.
The key insight is that speech has an inherent structure - certain combinations of sounds tend to co-occur and form words, phrases, and sentences. By letting the algorithm find these patterns on its own, the researchers were able to build a speech recognition model that works well without relying on manual annotations or predefined rules.
This approach has several potential benefits:
- It reduces the amount of human effort required to develop speech recognition systems
- It can potentially work with a wider range of accents, dialects, and languages that may not have extensive pronunciation dictionaries available
- The self-supervised learning allows the model to adapt and improve over time as it encounters more data
Overall, this research represents an important step towards more flexible and scalable speech recognition that is not as dependent on labor-intensive manual processes.
Technical Explanation
The core of this paper's approach is a <u>,self-supervised,</u> speech representation learning framework. The key components are:
-
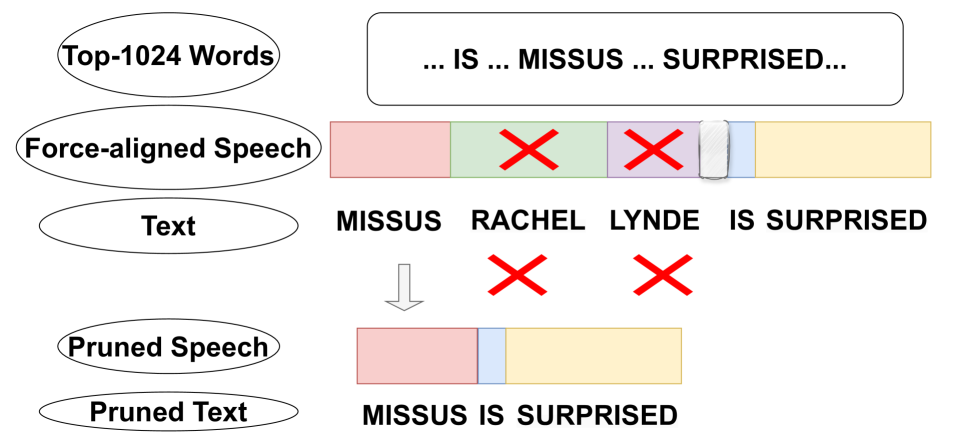
Speech Segmentation: The system first divides the continuous speech signal into discrete "speech units" (e.g. phones, syllables) without relying on any pronunciation models. This is done using an unsupervised segmentation algorithm that identifies potential word boundaries based on acoustic cues.
-
Representation Learning: The system then learns numerical representations (embeddings) for these discovered speech units in a self-supervised manner. It uses a contrastive objective to encourage the model to encode information that is useful for distinguishing between different speech units.
-
Downstream Tasks: With the learned speech representations, the system can be fine-tuned on various downstream tasks like speech recognition, without requiring any additional pronunciation dictionaries or labeled training data.
The experiments demonstrate that this unsupervised approach can achieve competitive performance on benchmark speech recognition tasks, <u>while eliminating the need for manually curated pronunciation models</u>. The authors also show that the learned representations are robust and transferable, enabling zero-shot adaptation to new speakers and domains.
Critical Analysis
A key strength of this work is that it tackles an important practical limitation of traditional speech recognition systems - their heavy reliance on labor-intensive, language-specific pronunciation resources. By taking a more data-driven, self-supervised approach, the proposed method has the potential to enable more flexible and scalable speech recognition that can better handle diverse accents, dialects, and even under-resourced languages.
However, the paper also acknowledges several limitations and areas for future work:
- The speech segmentation component is still a potential bottleneck, and the authors suggest exploring joint segmentation and representation learning approaches.
- The evaluation is primarily focused on English, and further research is needed to understand the performance and generalization of the method across a wider range of languages.
- While the self-supervised pre-training helps with data efficiency, some task-specific fine-tuning on labeled data is still required for optimal performance on downstream tasks.
Additionally, it would be helpful to see more analysis on the types of errors the system makes compared to traditional pronunciation-based approaches, and how the learned representations differ from those derived from manual phonetic transcriptions.
Overall, this work represents an exciting step towards more flexible and scalable speech recognition systems. By reducing the reliance on manually curated resources, it opens up new possibilities for deploying speech technologies in a wider range of real-world applications and settings.
Conclusion
This paper presents a novel approach to unsupervised speech recognition that does not rely on pronunciation models. By leveraging self-supervised learning to discover useful speech representations directly from the data, the proposed method can achieve competitive performance on benchmark tasks while eliminating the need for labor-intensive manual annotations.
The key innovation is the ability to learn speech representations in an unsupervised manner, without requiring predefined pronunciations or labeled training data. This has the potential to enable more flexible and adaptable speech recognition systems that can better handle diverse accents, dialects, and under-resourced languages.
While the research still has some limitations and areas for future work, it represents an important step towards more scalable and accessible speech technologies. By reducing the reliance on manual curation, this approach could ultimately help bring the benefits of speech recognition to a wider range of applications and user communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
Read more6/13/2024

0
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
William Ravenscroft, George Close, Stefan Goetze, Thomas Hain, Mohammad Soleymanpour, Anurag Chowdhury, Mark C. Fuhs
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Read more6/14/2024

0
Error-preserving Automatic Speech Recognition of Young English Learners' Language
Janick Michot, Manuela Hurlimann, Jan Deriu, Luzia Sauer, Katsiaryna Mlynchyk, Mark Cieliebak
One of the central skills that language learners need to practice is speaking the language. Currently, students in school do not get enough speaking opportunities and lack conversational practice. Recent advances in speech technology and natural language processing allow for the creation of novel tools to practice their speaking skills. In this work, we tackle the first component of such a pipeline, namely, the automated speech recognition module (ASR), which faces a number of challenges: first, state-of-the-art ASR models are often trained on adult read-aloud data by native speakers and do not transfer well to young language learners' speech. Second, most ASR systems contain a powerful language model, which smooths out errors made by the speakers. To give corrective feedback, which is a crucial part of language learning, the ASR systems in our setting need to preserve the errors made by the language learners. In this work, we build an ASR system that satisfies these requirements: it works on spontaneous speech by young language learners and preserves their errors. For this, we collected a corpus containing around 85 hours of English audio spoken by learners in Switzerland from grades 4 to 6 on different language learning tasks, which we used to train an ASR model. Our experiments show that our model benefits from direct fine-tuning on children's voices and has a much higher error preservation rate than other models.
Read more6/6/2024
0
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
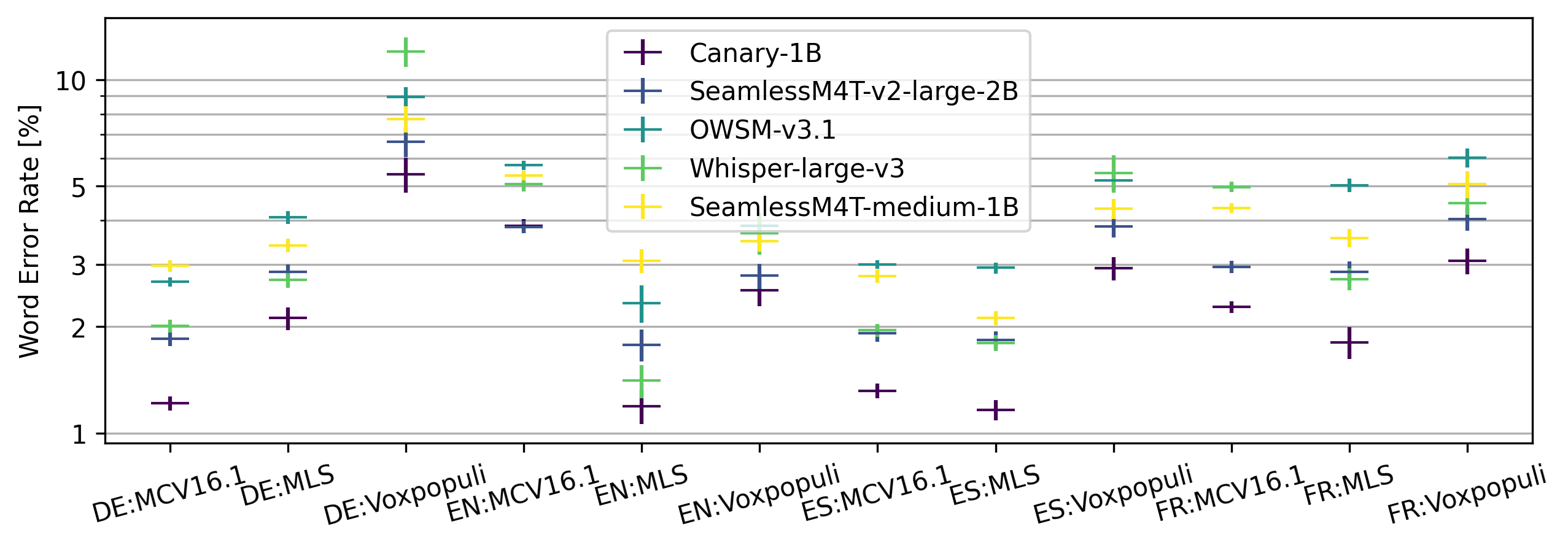
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
Read more7/1/2024