Transfer Q Star: Principled Decoding for LLM Alignment

0

Sign in to get full access
Overview
- This paper proposes a new approach called "Transfer Q⋆" for aligning large language models (LLMs) with desired properties or behaviors.
- The key idea is to use a "reference model" that encodes the desired properties, and then train the LLM to produce outputs that match the reference model's outputs through a controlled decoding process.
- This allows the LLM to be "aligned" with the reference model's behaviors, while still leveraging the LLM's powerful language modeling capabilities.
Plain English Explanation
The main challenge with large language models (LLMs) like GPT-3 is that they can sometimes produce outputs that don't align with the desired properties or behaviors we want the model to have. For example, an LLM trained on a broad corpus of internet data might generate text that contains biases, factual inaccuracies, or undesirable content.
To address this, the authors of this paper propose a new technique called "Transfer Q⋆". The key idea is to first train a "reference model" that encodes the specific properties and behaviors we want the LLM to have. This reference model might be smaller and more specialized than the LLM, but it serves as a guide for the desired outputs.
During the training process, the LLM is then encouraged to produce outputs that match the reference model's outputs, through a technique called "controlled decoding". This allows the LLM to leverage its powerful language modeling capabilities, while also aligning its outputs with the reference model's desirable properties.
The authors demonstrate the effectiveness of this approach on several tasks, showing that the LLM can be successfully aligned with the reference model's behaviors without sacrificing its overall performance. This could be a valuable tool for developing LLMs that are more reliable, trustworthy, and aligned with our values and objectives.
Technical Explanation
The authors frame the problem of aligning LLMs as one of "controlled decoding", where the goal is to train the LLM to produce outputs that match the desired properties encoded in a "reference model". Specifically, they define a loss function that encourages the LLM's outputs to be similar to the reference model's outputs, while still allowing the LLM to leverage its powerful language modeling capabilities.
The key technical elements of the proposed "Transfer Q⋆" approach include:
- Reference Model: A smaller, more specialized model that encodes the desired properties and behaviors that the LLM should align with.
- Controlled Decoding: A training process where the LLM is encouraged to produce outputs that match the reference model's outputs, through a loss function that compares the two.
- Iterative Fine-tuning: The LLM is fine-tuned on the reference model's outputs in an iterative fashion, gradually aligning it with the desired properties.
The authors evaluate their approach on several tasks, including language modeling, question answering, and text generation, and show that the LLM can be successfully aligned with the reference model's behaviors without sacrificing overall performance.
Critical Analysis
The authors present a well-designed and compelling approach for aligning LLMs with desired properties and behaviors. The use of a reference model as a guide, combined with the controlled decoding technique, is a promising solution to a challenging problem in AI safety and alignment.
One potential limitation of the approach is the reliance on a reference model, which may be difficult to develop or obtain in practice, especially for complex or subjective properties. The authors acknowledge this challenge and suggest that the reference model could be learned from human feedback or other sources.
Additionally, the authors do not explore the potential for unintended consequences or edge cases that could arise from this approach. For example, if the reference model itself has biases or flaws, those could be propagated to the aligned LLM. Further research and testing would be needed to understand the broader implications and limitations of this technique.
Overall, the "Transfer Q⋆" approach represents an important step forward in the quest to develop LLMs that are more reliable, trustworthy, and aligned with human values. The authors' work provides a solid foundation for future research and applications in this critical area of AI safety and alignment.
Conclusion
The "Transfer Q⋆" paper presents a novel approach for aligning large language models (LLMs) with desired properties and behaviors, using a "reference model" and a controlled decoding process. This technique holds promise for developing LLMs that are more reliable, trustworthy, and aligned with human values, while still leveraging the powerful language modeling capabilities of these models.
The key contributions of this work include the formal framing of the alignment problem, the technical details of the "Transfer Q⋆" approach, and the empirical evaluation demonstrating its effectiveness. While the approach has some limitations and challenges that require further exploration, it represents an important step forward in the critical field of AI safety and alignment.
As LLMs continue to grow in capability and influence, developing techniques like "Transfer Q⋆" will be essential for ensuring these powerful models are deployed in a responsible and beneficial manner. The authors' work lays the groundwork for future research and applications that could have far-reaching implications for the development of safe and aligned artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transfer Q Star: Principled Decoding for LLM Alignment
Souradip Chakraborty, Soumya Suvra Ghosal, Ming Yin, Dinesh Manocha, Mengdi Wang, Amrit Singh Bedi, Furong Huang
Aligning foundation models is essential for their safe and trustworthy deployment. However, traditional fine-tuning methods are computationally intensive and require updating billions of model parameters. A promising alternative, alignment via decoding, adjusts the response distribution directly without model updates to maximize a target reward $r$, thus providing a lightweight and adaptable framework for alignment. However, principled decoding methods rely on oracle access to an optimal Q-function ($Q^*$), which is often unavailable in practice. Hence, prior SoTA methods either approximate this $Q^*$ using $Q^{pi_{texttt{sft}}}$ (derived from the reference $texttt{SFT}$ model) or rely on short-term rewards, resulting in sub-optimal decoding performance. In this work, we propose Transfer $Q^*$, which implicitly estimates the optimal value function for a target reward $r$ through a baseline model $rho_{texttt{BL}}$ aligned with a baseline reward $rho_{texttt{BL}}$ (which can be different from the target reward $r$). Theoretical analyses of Transfer $Q^*$ provide a rigorous characterization of its optimality, deriving an upper bound on the sub-optimality gap and identifying a hyperparameter to control the deviation from the pre-trained reference $texttt{SFT}$ model based on user needs. Our approach significantly reduces the sub-optimality gap observed in prior SoTA methods and demonstrates superior empirical performance across key metrics such as coherence, diversity, and quality in extensive tests on several synthetic and real datasets.
Read more6/3/2024

0
Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
The complexity of the alignment problem stems from the fact that existing methods are considered unstable. Reinforcement Learning from Human Feedback (RLHF) addresses this issue by minimizing the KL divergence between the trained policy and the initial supervised fine-tuned policy (SFT) to avoid generating out-of-domain samples for the reward model (RM). Recently, many methods have emerged that shift from online to offline optimization, reformulating the RLHF objective and removing the reward model (DPO, IPO, KTO). Despite eliminating the reward model and the challenges it posed, these algorithms are still constrained in terms of closeness of the trained policy to the SFT one. In our paper, we argue that this implicit limitation in the offline optimization methods leads to suboptimal results. To address this issue, we propose a class of new methods called Trust Region (TR-DPO, TR-IPO, TR-KTO), which update the reference policy during training. With this straightforward update approach, we demonstrate the effectiveness of the new paradigm of language model alignment against the classical one on the Anthropic-HH and Reddit TL;DR datasets. Most notably, when automatically comparing TR methods and baselines side by side using pretrained Pythia 6.9B models on the Reddit TL;DR task, the difference in win rates reaches 8.4% for DPO, 14.3% for IPO, and 15% for KTO. Finally, by assessing model response ratings grounded on criteria such as coherence, correctness, helpfulness, and harmlessness, we demonstrate that our proposed methods significantly outperform existing techniques.
Read more5/22/2024
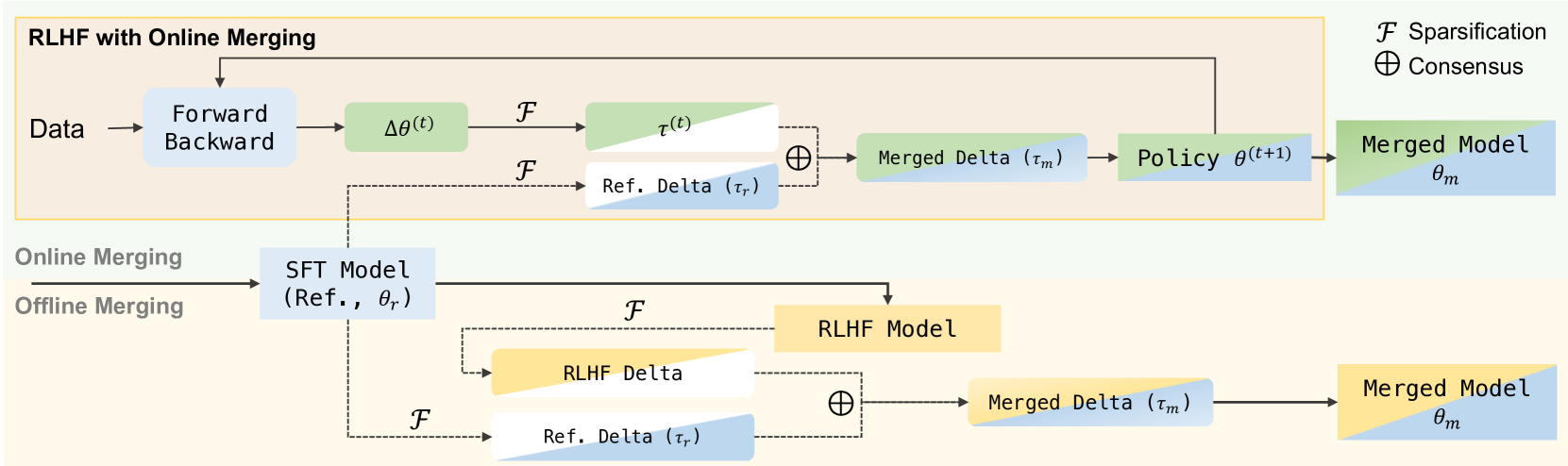
0
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
Read more5/29/2024
🏋️
0
Beyond Imitation: Leveraging Fine-grained Quality Signals for Alignment
Geyang Guo, Ranchi Zhao, Tianyi Tang, Wayne Xin Zhao, Ji-Rong Wen
Alignment with human preference is a desired property of large language models (LLMs). Currently, the main alignment approach is based on reinforcement learning from human feedback (RLHF). Despite the effectiveness of RLHF, it is intricate to implement and train, thus recent studies explore how to develop alternative alignment approaches based on supervised fine-tuning (SFT). A major limitation of SFT is that it essentially does imitation learning, which cannot fully understand what are the expected behaviors. To address this issue, we propose an improved alignment approach named FIGA. Different from prior methods, we incorporate fine-grained (i.e., token or phrase level) quality signals that are derived by contrasting good and bad responses. Our approach has made two major contributions. Firstly, we curate a refined alignment dataset that pairs initial responses and the corresponding revised ones. Secondly, we devise a new loss function can leverage fine-grained quality signals to instruct the learning of LLMs for alignment. Extensive experiments have demonstrated the effectiveness of our approaches by comparing a number of competitive baselines.
Read more4/16/2024