Transferable speech-to-text large language model alignment module
2406.13357
0
0

Abstract
By leveraging the power of Large Language Models(LLMs) and speech foundation models, state of the art speech-text bimodal works can achieve challenging tasks like spoken translation(ST) and question answering(SQA) altogether with much simpler architectures. In this paper, we utilize the capability of Whisper encoder and pre-trained Yi-6B. Empirical results reveal that modal alignment can be achieved with one layer module and hundred hours of speech-text multitask corpus. We further swap the Yi-6B with human preferences aligned version of Yi-6B-Chat during inference, and discover that the alignment capability is applicable as well. In addition, the alignment subspace revealed by singular value decomposition(SVD) also implies linear alignment subspace is sparse, which leaves the possibility to concatenate other features like voice-print or video to expand modality.
Create account to get full access
Overview
- Presents a transferable speech-to-text large language model alignment module
- Focuses on improving speech recognition performance by aligning speech models with large language models
- Experimental setup involves fine-tuning speech models on a large text corpus to leverage the knowledge in language models
Plain English Explanation
This paper explores a method to enhance speech recognition models by aligning them with powerful language models. <a href="https://aimodels.fyi/papers/arxiv/transforming-llms-into-cross-modal-cross-lingual">Large language models</a> have become extremely capable at understanding and generating human language, but they are typically trained on text data alone. The researchers wanted to leverage this linguistic knowledge to boost the performance of speech recognition models, which can struggle with certain accents, dialects, or speaking styles.
The key idea is to take a pre-trained speech recognition model and fine-tune it on a large text corpus, in addition to the typical speech data. This allows the speech model to learn from the language patterns and knowledge captured in the language model, making it better able to transcribe speech accurately. The researchers hypothesized that this "alignment" between the speech and language models would lead to improved speech recognition, especially on challenging or diverse speech samples.
Technical Explanation
The paper presents a transferable speech-to-text large language model alignment module that aims to improve speech recognition performance. The approach involves fine-tuning a pre-trained speech recognition model on a large text corpus, in addition to the standard speech data, to leverage the knowledge captured in large language models.
Specifically, the researchers start with a well-performing <a href="https://aimodels.fyi/papers/arxiv/discrete-multimodal-transformers-pretrained-large-language-model">pre-trained speech recognition model</a>. They then fine-tune this model on a large text corpus, such as books or web pages, using a novel training objective that aligns the speech model with the language model. This allows the speech model to learn from the rich linguistic patterns and world knowledge present in the language model.
The experiments show that this alignment procedure leads to significant improvements in speech recognition accuracy, especially on challenging test sets that involve diverse accents, speaking styles, and topic domains. The researchers hypothesize that the speech model is able to draw on the language model's understanding of syntax, semantics, and common knowledge to better transcribe ambiguous or noisy speech.
Critical Analysis
The paper presents a promising approach to improving speech recognition by leveraging large language models. The authors provide a thorough experimental evaluation, demonstrating the effectiveness of their alignment technique on a variety of speech recognition benchmarks.
One potential limitation is that the approach relies on access to a pre-trained language model, which may not always be available or easily adaptable to specific domains or languages. <a href="https://aimodels.fyi/papers/arxiv/using-large-language-model-end-to-end">Further research</a> could explore ways to train the speech and language models in a more integrated, end-to-end fashion.
Additionally, the paper does not delve into the specific mechanisms by which the alignment process improves speech recognition. <a href="https://aimodels.fyi/papers/arxiv/seamlessexpressivelm-speech-language-model-expressive-speech-to">Future work</a> could investigate the internal representations and behaviors of the aligned models to gain a deeper understanding of how the language model knowledge is being leveraged.
Overall, this research represents an important step towards more robust and versatile speech recognition systems, with potential applications in areas like voice assistants, transcription, and accessibility technologies. Continued advancements in this direction, <a href="https://aimodels.fyi/papers/arxiv/efficient-compression-multitask-multilingual-speech-models">including efficient compression and multilingual support</a>, could have significant real-world impact.
Conclusion
This paper presents a transferable speech-to-text large language model alignment module that can improve the performance of speech recognition systems. By fine-tuning a pre-trained speech model on a large text corpus, the researchers are able to leverage the linguistic knowledge captured in powerful language models to enhance the speech model's accuracy, particularly on challenging speech samples.
The experimental results demonstrate the effectiveness of this approach, and the paper highlights the potential for further advancements in this area to drive progress in speech-based technologies. As language models continue to advance and become more widely accessible, techniques like the one described in this paper could play a crucial role in developing more robust and versatile speech recognition systems that can benefit a wide range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Discrete Multimodal Transformers with a Pretrained Large Language Model for Mixed-Supervision Speech Processing
Viet Anh Trinh, Rosy Southwell, Yiwen Guan, Xinlu He, Zhiyong Wang, Jacob Whitehill
0
0
Recent work on discrete speech tokenization has paved the way for models that can seamlessly perform multiple tasks across modalities, e.g., speech recognition, text to speech, speech to speech translation. Moreover, large language models (LLMs) pretrained from vast text corpora contain rich linguistic information that can improve accuracy in a variety of tasks. In this paper, we present a decoder-only Discrete Multimodal Language Model (DMLM), which can be flexibly applied to multiple tasks (ASR, T2S, S2TT, etc.) and modalities (text, speech, vision). We explore several critical aspects of discrete multi-modal models, including the loss function, weight initialization, mixed training supervision, and codebook. Our results show that DMLM benefits significantly, across multiple tasks and datasets, from a combination of supervised and unsupervised training. Moreover, for ASR, it benefits from initializing DMLM from a pretrained LLM, and from a codebook derived from Whisper activations.
6/26/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024

Using Large Language Model for End-to-End Chinese ASR and NER
Yuang Li, Jiawei Yu, Min Zhang, Mengxin Ren, Yanqing Zhao, Xiaofeng Zhao, Shimin Tao, Jinsong Su, Hao Yang
0
0
Mapping speech tokens to the same feature space as text tokens has become the paradigm for the integration of speech modality into decoder-only large language models (LLMs). An alternative approach is to use an encoder-decoder architecture that incorporates speech features through cross-attention. This approach, however, has received less attention in the literature. In this work, we connect the Whisper encoder with ChatGLM3 and provide in-depth comparisons of these two approaches using Chinese automatic speech recognition (ASR) and name entity recognition (NER) tasks. We evaluate them not only by conventional metrics like the F1 score but also by a novel fine-grained taxonomy of ASR-NER errors. Our experiments reveal that encoder-decoder architecture outperforms decoder-only architecture with a short context, while decoder-only architecture benefits from a long context as it fully exploits all layers of the LLM. By using LLM, we significantly reduced the entity omission errors and improved the entity ASR accuracy compared to the Conformer baseline. Additionally, we obtained a state-of-the-art (SOTA) F1 score of 0.805 on the AISHELL-NER test set by using chain-of-thought (CoT) NER which first infers long-form ASR transcriptions and then predicts NER labels.
6/7/2024
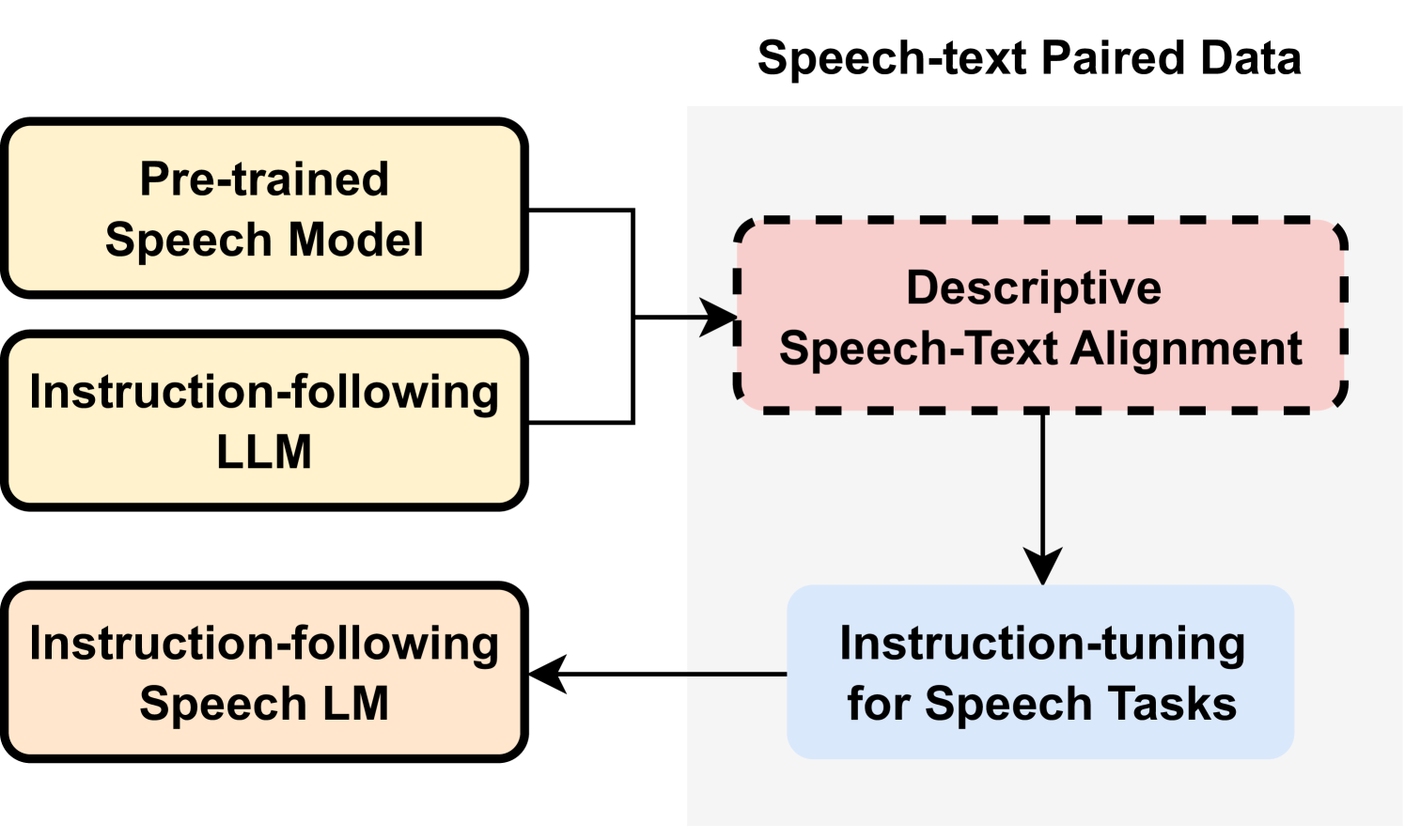
DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, He Huang, Boris Ginsburg, Yu-Chiang Frank Wang, Hung-yi Lee
0
0
Recent speech language models (SLMs) typically incorporate pre-trained speech models to extend the capabilities from large language models (LLMs). In this paper, we propose a Descriptive Speech-Text Alignment approach that leverages speech captioning to bridge the gap between speech and text modalities, enabling SLMs to interpret and generate comprehensive natural language descriptions, thereby facilitating the capability to understand both linguistic and non-linguistic features in speech. Enhanced with the proposed approach, our model demonstrates superior performance on the Dynamic-SUPERB benchmark, particularly in generalizing to unseen tasks. Moreover, we discover that the aligned model exhibits a zero-shot instruction-following capability without explicit speech instruction tuning. These findings highlight the potential to reshape instruction-following SLMs by incorporating rich, descriptive speech captions.
6/28/2024