DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
2406.18871
0
0
Abstract
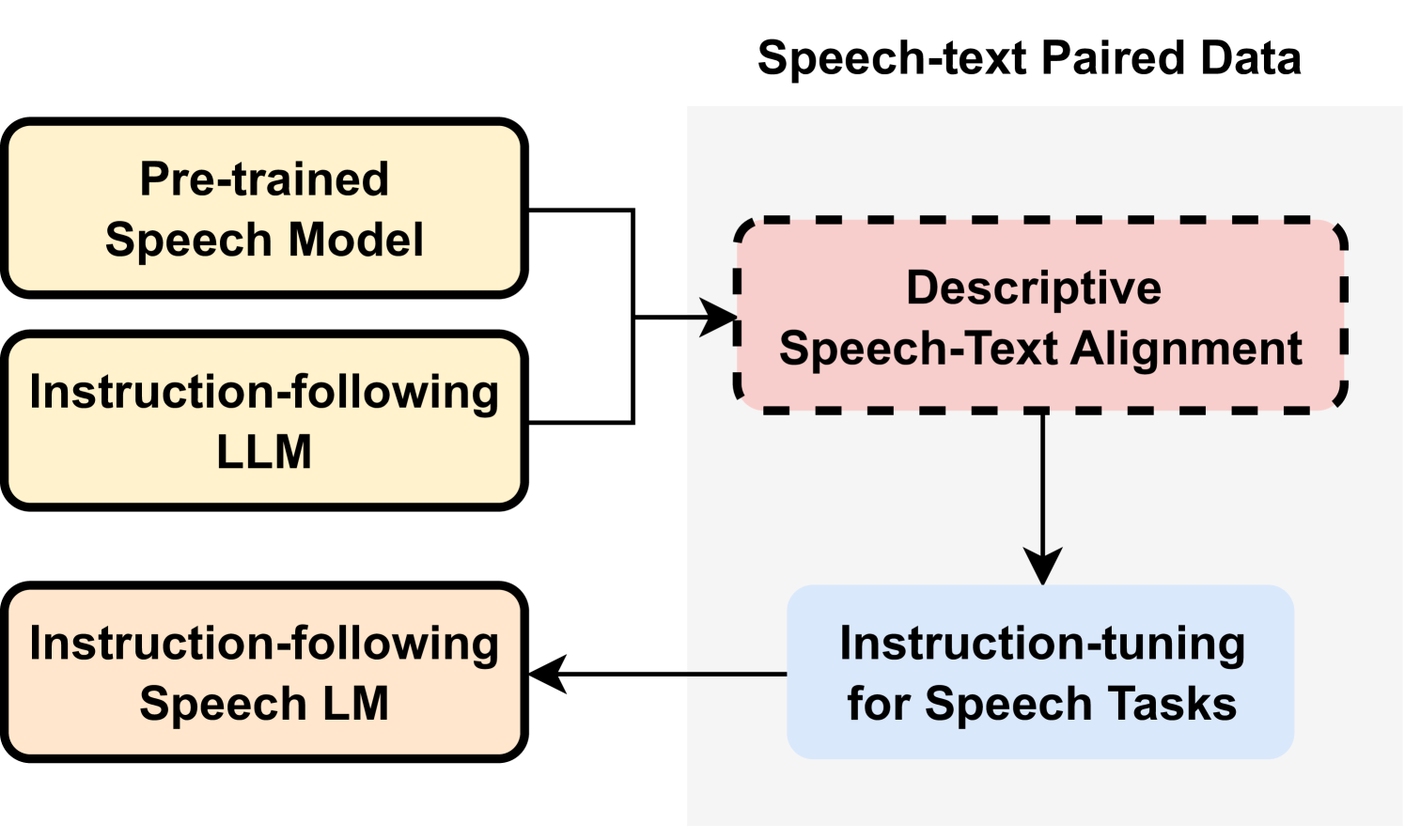
Recent speech language models (SLMs) typically incorporate pre-trained speech models to extend the capabilities from large language models (LLMs). In this paper, we propose a Descriptive Speech-Text Alignment approach that leverages speech captioning to bridge the gap between speech and text modalities, enabling SLMs to interpret and generate comprehensive natural language descriptions, thereby facilitating the capability to understand both linguistic and non-linguistic features in speech. Enhanced with the proposed approach, our model demonstrates superior performance on the Dynamic-SUPERB benchmark, particularly in generalizing to unseen tasks. Moreover, we discover that the aligned model exhibits a zero-shot instruction-following capability without explicit speech instruction tuning. These findings highlight the potential to reshape instruction-following SLMs by incorporating rich, descriptive speech captions.
Create account to get full access
Overview
- This paper introduces DeSTA, a method for enhancing speech language models by aligning speech and text data through descriptive speech-text alignment.
- The key idea is to leverage descriptive speech-text alignments, which capture the relationship between spoken language and its textual description, to improve the performance of speech language models.
- The researchers demonstrate that DeSTA can significantly boost the performance of speech language models on various benchmarks, including Transferable Speech-to-Text with Large Language Models, Bridging Language Gaps for Audio-Text Retrieval, Improving Robustness of LLM-based Speech Synthesis, BLSP: Bootstrapping Language-Speech Pre-training, and Transforming LLMs into Cross-Modal, Cross-Lingual Models.
Plain English Explanation
The paper presents a new way to improve speech language models, which are AI systems that can understand and generate spoken language. The key idea is to use the relationship between spoken language and its written description to help the model learn better.
Imagine you're trying to teach a child a new word. You might say the word out loud and then show them the written version. The child can then learn to associate the spoken word with the written text. Similarly, the researchers use this "speech-text alignment" to help the AI model learn the connection between speech and text more effectively.
By incorporating this descriptive speech-text alignment into the model's training process, the researchers show that it can significantly boost the model's performance on a variety of tasks, such as transcribing speech, retrieving audio based on text, and generating more natural-sounding synthetic speech. This is an important advance because it can make speech language models more accurate and useful in real-world applications.
Technical Explanation
The paper introduces a method called Descriptive Speech-Text Alignment (DeSTA) that enhances the performance of speech language models by leveraging the relationship between spoken language and its textual description.
The key insight behind DeSTA is that the alignment between speech and its descriptive text can provide valuable information to help speech language models learn more effectively. The researchers hypothesize that by incorporating this alignment into the model's training process, it can better capture the nuances and context of spoken language, leading to improved performance on a variety of tasks.
To implement DeSTA, the researchers first collect a dataset of speech recordings and their corresponding textual descriptions. They then use this data to train a model that can align the speech and text, capturing the relationship between the two modalities.
Next, they incorporate the aligned speech-text pairs into the training of the speech language model, using the alignment information to guide the model's learning process. This is done by augmenting the model's training objective to include a term that encourages the model to correctly predict the corresponding textual description for a given speech input.
The researchers evaluate the effectiveness of DeSTA on several benchmark tasks, including Transferable Speech-to-Text with Large Language Models, Bridging Language Gaps for Audio-Text Retrieval, Improving Robustness of LLM-based Speech Synthesis, BLSP: Bootstrapping Language-Speech Pre-training, and Transforming LLMs into Cross-Modal, Cross-Lingual Models. The results demonstrate that DeSTA can significantly improve the performance of speech language models across these diverse applications.
Critical Analysis
The paper presents a compelling approach to enhancing speech language models, and the results are impressive. However, there are a few potential limitations and areas for further research that could be considered:
-
Dataset Quality and Diversity: The effectiveness of DeSTA likely depends on the quality and diversity of the speech-text alignment dataset used for training. The researchers should investigate the impact of dataset size, language coverage, and domain specificity on the model's performance.
-
Scalability and Computational Efficiency: Incorporating the additional speech-text alignment objective into the model training process may increase the computational complexity and training time. The researchers should explore ways to make DeSTA more scalable and efficient, especially for large-scale speech language models.
-
Generalization to Low-Resource Languages: The paper focuses on evaluating DeSTA on high-resource languages, such as English. It would be interesting to see how well the approach generalizes to low-resource languages, where data scarcity is a significant challenge for speech language models.
-
Interpretability and Explainability: While the performance improvements are clear, it would be valuable to better understand the internal workings of DeSTA and how the speech-text alignment information is being leveraged by the model. Improving the interpretability of the approach could lead to further insights and advancements.
Overall, the DeSTA method presented in this paper is a promising step forward in enhancing the capabilities of speech language models. The researchers have demonstrated the effectiveness of their approach, and the critical analysis suggests avenues for future research to further expand the capabilities and applicability of this technology.
Conclusion
The paper introduces DeSTA, a novel method for enhancing speech language models by leveraging the relationship between spoken language and its textual description. By incorporating descriptive speech-text alignment into the model's training process, DeSTA can significantly improve the performance of speech language models on a variety of tasks, including speech transcription, audio-text retrieval, and speech synthesis.
The key contribution of this work is the insight that the alignment between speech and its descriptive text can provide valuable information to help speech language models learn more effectively. The researchers demonstrate the effectiveness of DeSTA across multiple benchmark tasks, showcasing its potential to advance the state of the art in speech language understanding and generation.
While the paper presents a compelling approach, the critical analysis highlights potential avenues for further research, such as exploring the impact of dataset quality and diversity, improving the scalability and computational efficiency of DeSTA, and investigating its generalization to low-resource languages. By addressing these areas, the researchers could further enhance the capabilities and real-world applicability of speech language models.
Overall, the DeSTA method represents an important step forward in the field of speech language processing, with the potential to unlock new possibilities in a wide range of applications, from voice assistants and transcription services to multimodal language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Transferable speech-to-text large language model alignment module
Boyong Wu, Chao Yan, Haoran Pu
0
0
By leveraging the power of Large Language Models(LLMs) and speech foundation models, state of the art speech-text bimodal works can achieve challenging tasks like spoken translation(ST) and question answering(SQA) altogether with much simpler architectures. In this paper, we utilize the capability of Whisper encoder and pre-trained Yi-6B. Empirical results reveal that modal alignment can be achieved with one layer module and hundred hours of speech-text multitask corpus. We further swap the Yi-6B with human preferences aligned version of Yi-6B-Chat during inference, and discover that the alignment capability is applicable as well. In addition, the alignment subspace revealed by singular value decomposition(SVD) also implies linear alignment subspace is sparse, which leaves the possibility to concatenate other features like voice-print or video to expand modality.
6/21/2024

Bridging Language Gaps in Audio-Text Retrieval
Zhiyong Yan, Heinrich Dinkel, Yongqing Wang, Jizhong Liu, Junbo Zhang, Yujun Wang, Bin Wang
0
0
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
6/18/2024
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Rafael Valle, Rohan Badlani, Boris Ginsburg
0
0
Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
6/27/2024
🤔
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Chen Wang, Minpeng Liao, Zhongqiang Huang, Jinliang Lu, Junhong Wu, Yuchen Liu, Chengqing Zong, Jiajun Zhang
0
0
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
5/29/2024