Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models

0

Sign in to get full access
Overview
- This paper explores how to distill the knowledge from complex quadratic models, like Transformers, into more efficient subquadratic models like State Space Models (SSMs).
- The key idea is to use the predictions of the quadratic model to train a simpler SSM, allowing the SSM to learn the underlying patterns without the full computational cost.
- The authors demonstrate this approach on several language modeling tasks, showing the SSMs can achieve similar performance to Transformers but with much faster inference times.
Plain English Explanation
Transformers are a powerful type of machine learning model that have revolutionized many language and text-based tasks. However, Transformers are also computationally expensive, requiring a lot of memory and processing power to run.
This paper looks at a way to take the knowledge learned by a Transformer model and "distill" it into a simpler and more efficient model called a State Space Model (SSM). The key idea is to use the Transformer's predictions on a dataset to train the SSM, essentially allowing the SSM to learn the same underlying patterns, but with a much lower computational cost.
The authors show that this distillation process works quite well, with the SSM models achieving similar performance to the original Transformers, but running much faster during inference (when you're actually using the model). This could make it practical to deploy these types of language models in resource-constrained settings like on mobile devices or low-power servers.
Technical Explanation
The paper proposes a method to "distill" the knowledge from complex quadratic models like Transformers into more efficient subquadratic models like State Space Models (SSMs). The core idea is to use the predictions of the quadratic model to train the parameters of the SSM, allowing it to learn the same underlying patterns but with a much lower computational cost.
Specifically, the authors first train a Transformer model on a language modeling task. They then use the Transformer's predictions on the training data to supervise the training of an SSM. This allows the SSM to mimic the Transformer's behavior without having to learn the full quadratic structure from scratch.
The authors evaluate this approach on several benchmarks, including WikiText-103 and PG-19. They show that the SSM models are able to achieve similar perplexity scores to the original Transformers, but with inference times that are 5-10x faster. This demonstrates the ability to distill the "quadratic knowledge" of Transformers into a more efficient subquadratic form.
The authors also provide theoretical analysis showing that under certain assumptions, the SSM can provably approximate the Transformer with arbitrary accuracy. This provides a solid theoretical foundation for the empirical results.
Critical Analysis
The key strength of this work is the ability to drastically improve the efficiency of language models without sacrificing too much performance. Transformers have become the dominant architecture, but their computational requirements have limited their deployment, especially on resource-constrained devices.
The authors' distillation approach is an elegant solution to this problem, allowing the benefits of Transformer models to be enjoyed more widely. The rigorous theoretical analysis also lends strong support to the empirical findings.
That said, the paper does not address some potential limitations or areas for further research. For instance, it's unclear how this distillation process would work for more complex downstream tasks beyond just language modeling. The authors also don't explore the effects of different distillation hyperparameters or training regimes.
Additionally, while the SSM models are much more efficient than Transformers, they are still more complex than some other lightweight language models like n-grams or LSTMs. Further research could investigate whether the distilled knowledge can be compressed even further without too much loss in accuracy.
Overall, this is an impressive piece of work that makes an important contribution to the field of efficient and scalable natural language processing. The ideas presented here could have wide-ranging implications as machine learning models become more ubiquitous in our daily lives.
Conclusion
This paper introduces a novel approach to distill the knowledge from complex quadratic models like Transformers into more efficient subquadratic State Space Models (SSMs). By using the Transformer's predictions to supervise the training of the SSM, the authors are able to achieve similar performance to the original Transformer, but with much faster inference times.
This work has significant practical implications, as it opens the door to deploying powerful language models in resource-constrained settings like mobile devices or edge computing. The theoretical analysis also provides a strong foundation for the empirical results, suggesting the distillation process is a principled way to compress quadratic knowledge into a simpler form.
While there are still some open questions and potential limitations, this paper represents an important step forward in making advanced natural language processing more widely accessible and usable. As machine learning becomes more ubiquitous, techniques like this will be crucial for ensuring the benefits are enjoyed by all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models
Aviv Bick, Kevin Y. Li, Eric P. Xing, J. Zico Kolter, Albert Gu
Transformer architectures have become a dominant paradigm for domains like language modeling but suffer in many inference settings due to their quadratic-time self-attention. Recently proposed subquadratic architectures, such as Mamba, have shown promise, but have been pretrained with substantially less computational resources than the strongest Transformer models. In this work, we present a method that is able to distill a pretrained Transformer architecture into alternative architectures such as state space models (SSMs). The key idea to our approach is that we can view both Transformers and SSMs as applying different forms of mixing matrices over the token sequences. We can thus progressively distill the Transformer architecture by matching different degrees of granularity in the SSM: first matching the mixing matrices themselves, then the hidden units at each block, and finally the end-to-end predictions. Our method, called MOHAWK, is able to distill a Mamba-2 variant based on the Phi-1.5 architecture (Phi-Mamba) using only 3B tokens and a hybrid version (Hybrid Phi-Mamba) using 5B tokens. Despite using less than 1% of the training data typically used to train models from scratch, Phi-Mamba boasts substantially stronger performance compared to all past open-source non-Transformer models. MOHAWK allows models like SSMs to leverage computational resources invested in training Transformer-based architectures, highlighting a new avenue for building such models.
Read more8/20/2024
🧠
1
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Tri Dao, Albert Gu
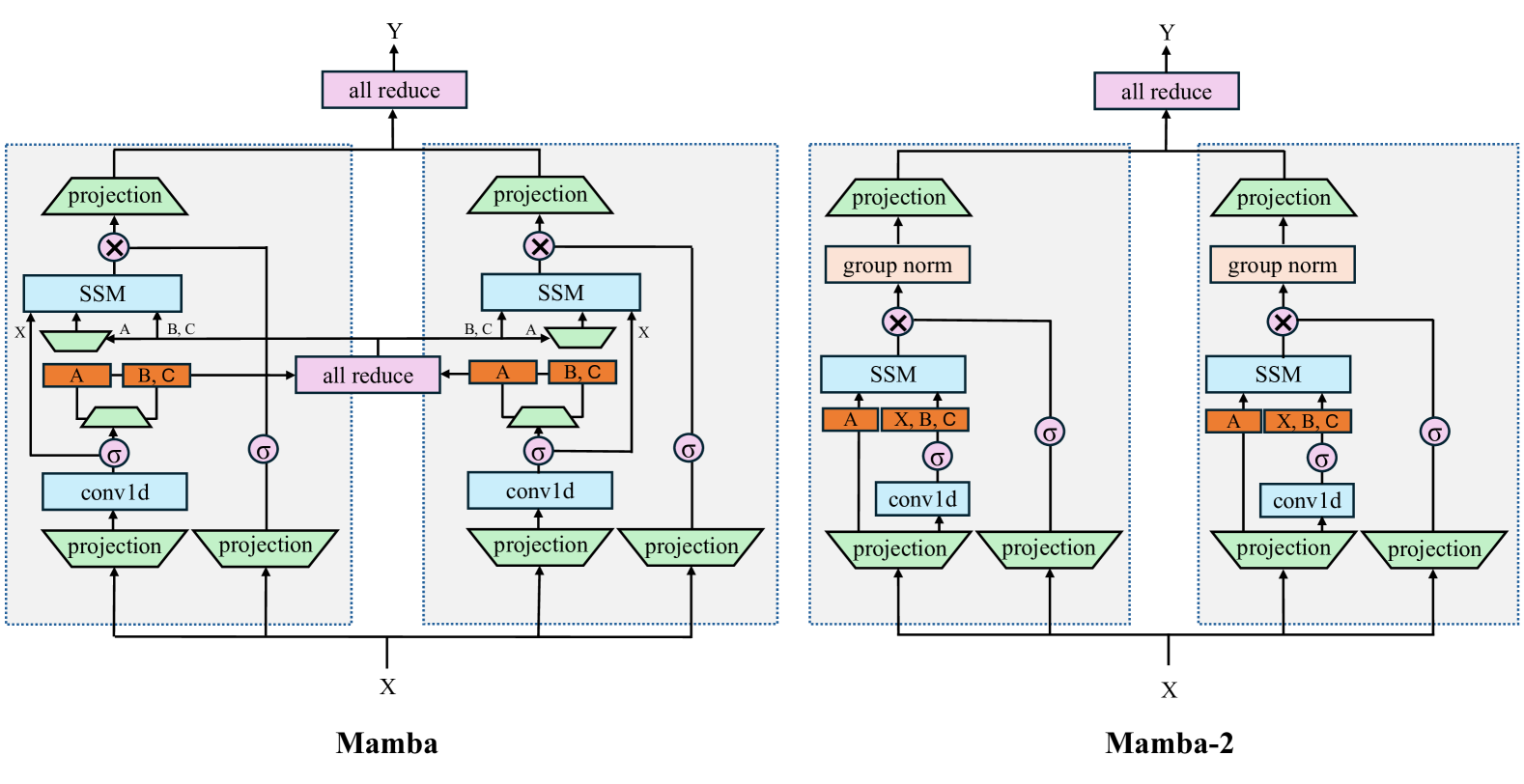
While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale. We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices. Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is an a refinement of Mamba's selective SSM that is 2-8X faster, while continuing to be competitive with Transformers on language modeling.
Read more6/3/2024
30
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Read more6/13/2024
🤷
91
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Read more6/3/2024