Transforming Dutch: Debiasing Dutch Coreference Resolution Systems for Non-binary Pronouns
2405.00134
0
0
Abstract
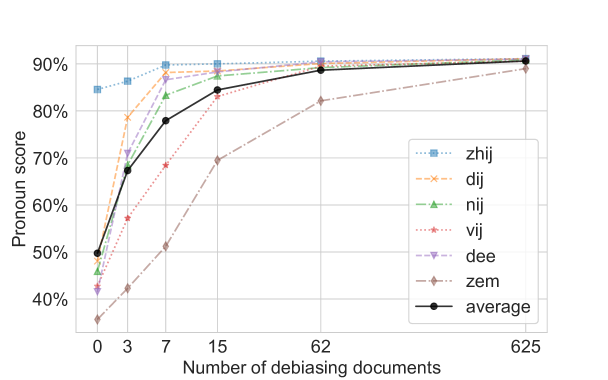
Gender-neutral pronouns are increasingly being introduced across Western languages. Recent evaluations have however demonstrated that English NLP systems are unable to correctly process gender-neutral pronouns, with the risk of erasing and misgendering non-binary individuals. This paper examines a Dutch coreference resolution system's performance on gender-neutral pronouns, specifically hen and die. In Dutch, these pronouns were only introduced in 2016, compared to the longstanding existence of singular they in English. We additionally compare two debiasing techniques for coreference resolution systems in non-binary contexts: Counterfactual Data Augmentation (CDA) and delexicalisation. Moreover, because pronoun performance can be hard to interpret from a general evaluation metric like LEA, we introduce an innovative evaluation metric, the pronoun score, which directly represents the portion of correctly processed pronouns. Our results reveal diminished performance on gender-neutral pronouns compared to gendered counterparts. Nevertheless, although delexicalisation fails to yield improvements, CDA substantially reduces the performance gap between gendered and gender-neutral pronouns. We further show that CDA remains effective in low-resource settings, in which a limited set of debiasing documents is used. This efficacy extends to previously unseen neopronouns, which are currently infrequently used but may gain popularity in the future, underscoring the viability of effective debiasing with minimal resources and low computational costs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores debiasing Dutch coreference resolution systems to better handle non-binary pronouns.
- It examines gender biases in existing Dutch language models and proposes methods to reduce these biases.
- The research aims to make Dutch NLP systems more inclusive and respectful of gender diversity.
Plain English Explanation
Coreference resolution is the process of determining which words or phrases in a text refer to the same entity. This is an important task in natural language processing (NLP) that helps computers better understand the meaning of a text.
However, many existing coreference resolution systems have been found to exhibit gender biases. For example, they may be more likely to associate certain words or roles with men or women. This can be problematic, as it can perpetuate harmful stereotypes and exclude people who don't identify as male or female.
This paper focuses on addressing these biases in Dutch coreference resolution systems. Dutch is a language spoken in the Netherlands and Belgium, and it has some unique gender-neutral pronouns like "het" that can be used to refer to people in a non-binary way.
The researchers examined how well existing Dutch language models handle these non-binary pronouns, and they found significant biases. To address this, they developed methods to "debias" the models and make them more inclusive. This involved techniques like [adding internal link: https://aimodels.fyi/papers/arxiv/robust-pronoun-use-fidelity-english-llms-are] fine-tuning the models on gender-diverse data and [adding internal link: https://aimodels.fyi/papers/arxiv/investigating-markers-drivers-gender-bias-machine-translations] modifying the model architectures.
The goal is to create Dutch NLP systems that are more respectful and accurate when dealing with people of all gender identities. This is an important step towards building technology that is inclusive and reflective of the diversity in our society.
Technical Explanation
The paper first provides an overview of coreference resolution and the challenges of gender bias in NLP systems. It then discusses the unique linguistic context of the Dutch language, which has gender-neutral pronouns like "het" that can be used to refer to people who don't identify as male or female.
The researchers analyze the performance of existing Dutch coreference resolution models on gender-diverse text, and they find significant biases. For example, the models tend to associate certain roles and occupations more strongly with male pronouns.
To address these biases, the researchers explore several debiasing techniques:
-
Data Augmentation: They fine-tune the models on datasets that include more gender-diverse examples, such as [adding internal link: https://aimodels.fyi/papers/arxiv/tokenization-matters-navigating-data-scarce-tokenization-gender] texts that use neopronouns or gender-neutral language.
-
Architecture Modifications: The researchers experiment with changes to the model architecture, such as [adding internal link: https://aimodels.fyi/papers/arxiv/are-models-biased-text-without-gender-related] adding dedicated layers to handle gender-neutral pronouns.
-
Adversarial Training: They use adversarial training techniques to encourage the models to be less sensitive to gender-related features, while maintaining strong coreference resolution performance.
The paper presents the results of these debiasing approaches, showing that they can significantly reduce gender biases in Dutch coreference resolution without compromising overall system accuracy.
Critical Analysis
The paper provides a thorough and well-designed examination of gender biases in Dutch coreference resolution systems. The researchers have identified an important issue and proposed concrete solutions to address it.
One potential limitation is the scope of the evaluation, which focuses primarily on a single language (Dutch) and a specific task (coreference resolution). It would be interesting to see if the debiasing techniques could be applied more broadly to other NLP tasks and languages, such as [adding internal link: https://aimodels.fyi/papers/arxiv/investigating-gender-bias-turkish-language-models] exploring gender bias in other gender-diverse languages.
Additionally, the paper does not delve deeply into the potential societal impacts of this research. While the goal of building more inclusive NLP systems is laudable, the authors could have discussed the real-world implications and how this work might help make technology more equitable and representative of diverse communities.
Overall, this is a valuable contribution to the growing body of research on mitigating gender biases in NLP. The techniques and insights presented here could be influential in guiding future efforts to develop more inclusive and respectful language technologies.
Conclusion
This paper tackles the important issue of gender bias in Dutch coreference resolution systems. By examining the performance of existing models on gender-diverse text and developing debiasing techniques, the researchers have made significant progress towards building NLP systems that are more inclusive and representative of people of all gender identities.
The findings and methods presented in this work could have wide-ranging implications for the development of language technologies that are ethical, equitable, and reflective of the diversity in our societies. As the field of NLP continues to evolve, this research serves as a valuable example of how we can work to create more inclusive and responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
Anaelia Ovalle, Ninareh Mehrabi, Palash Goyal, Jwala Dhamala, Kai-Wei Chang, Richard Zemel, Aram Galstyan, Yuval Pinter, Rahul Gupta
0
0
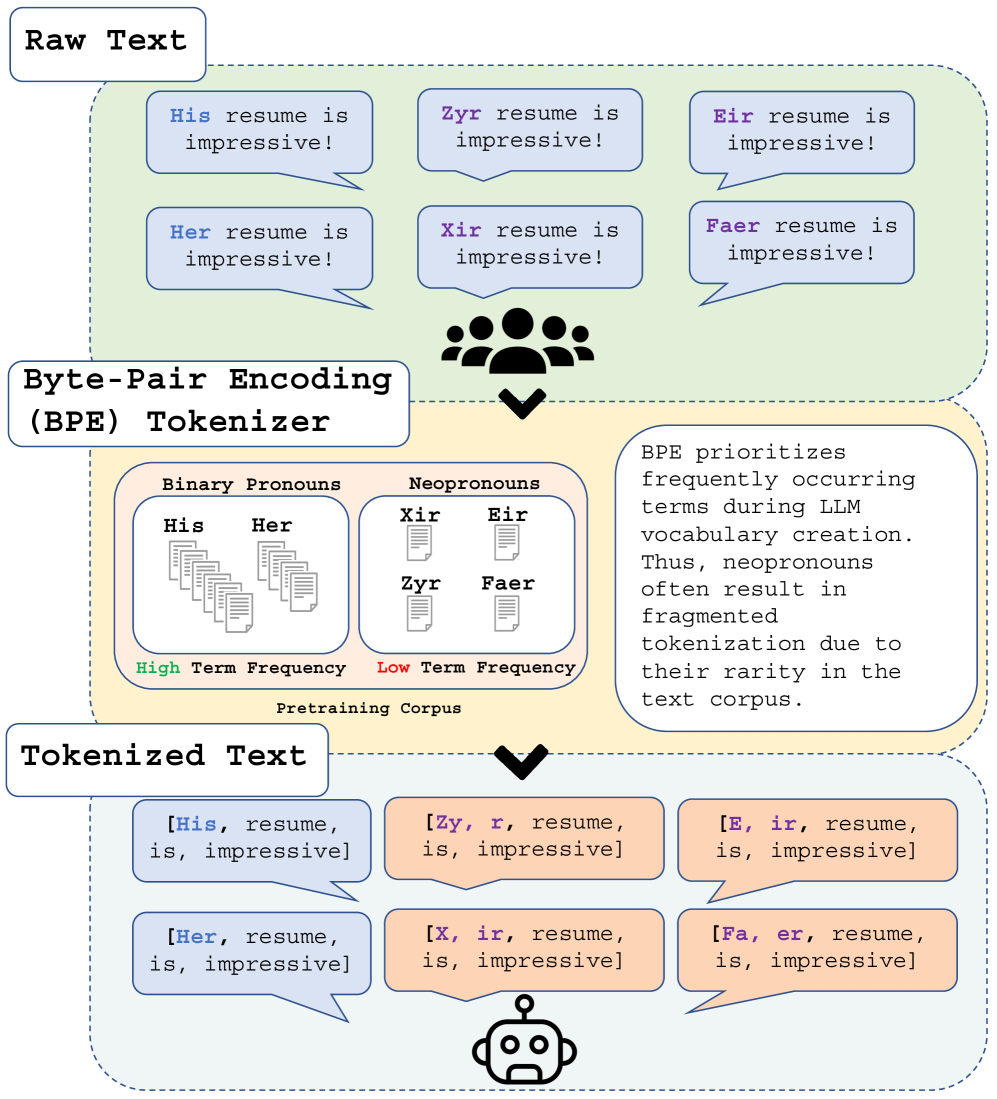
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
4/9/2024
🧠
New!Persian Pronoun Resolution: Leveraging Neural Networks and Language Models
Hassan Haji Mohammadi, Alireza Talebpour, Ahmad Mahmoudi Aznaveh, Samaneh Yazdani
0
0
Coreference resolution, critical for identifying textual entities referencing the same entity, faces challenges in pronoun resolution, particularly identifying pronoun antecedents. Existing methods often treat pronoun resolution as a separate task from mention detection, potentially missing valuable information. This study proposes the first end-to-end neural network system for Persian pronoun resolution, leveraging pre-trained Transformer models like ParsBERT. Our system jointly optimizes both mention detection and antecedent linking, achieving a 3.37 F1 score improvement over the previous state-of-the-art system (which relied on rule-based and statistical methods) on the Mehr corpus. This significant improvement demonstrates the effectiveness of combining neural networks with linguistic models, potentially marking a significant advancement in Persian pronoun resolution and paving the way for further research in this under-explored area.
5/20/2024
Robust Pronoun Use Fidelity with English LLMs: Are they Reasoning, Repeating, or Just Biased?
Vagrant Gautam, Eileen Bingert, Dawei Zhu, Anne Lauscher, Dietrich Klakow
0
0
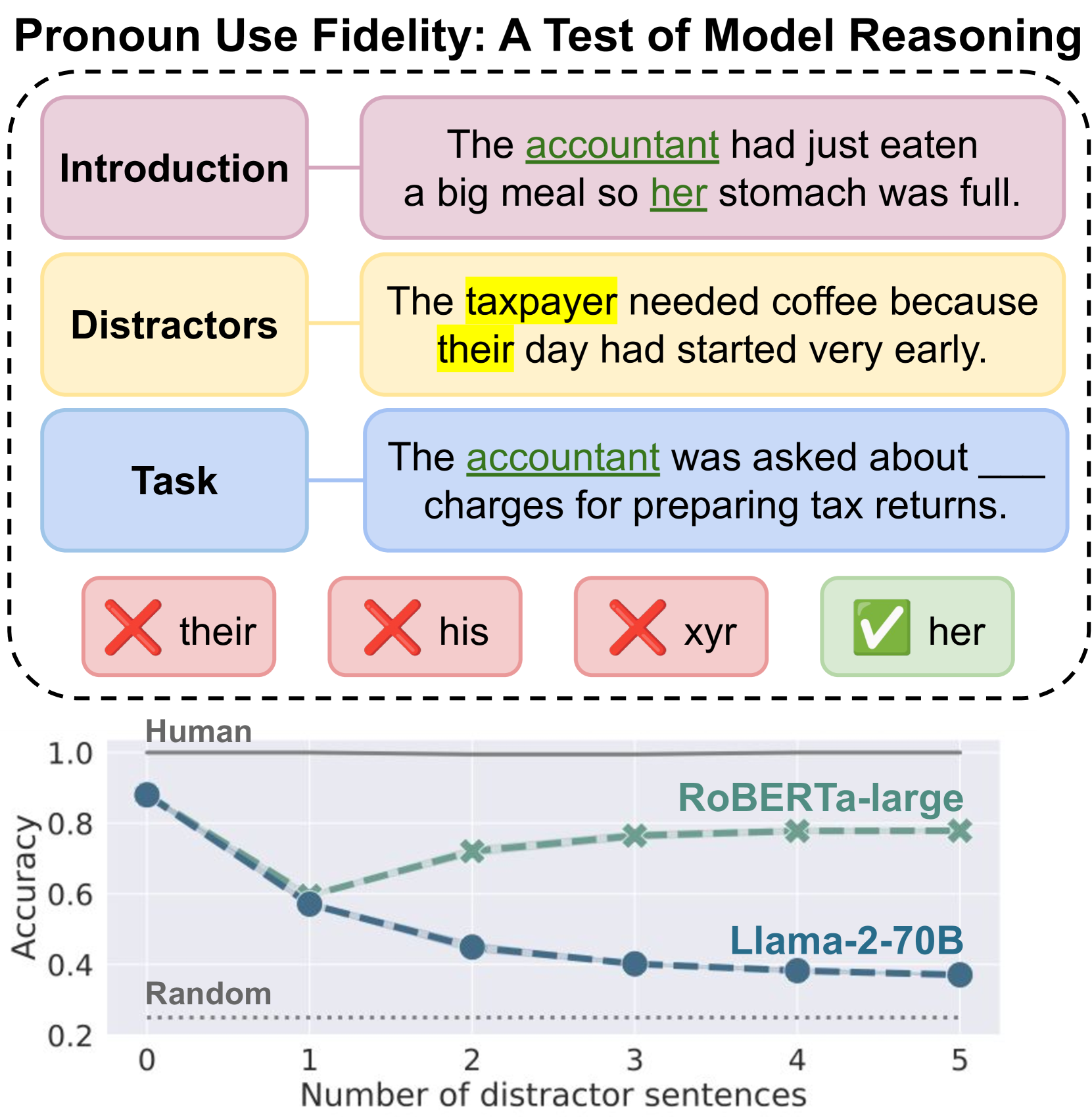
Robust, faithful and harm-free pronoun use for individuals is an important goal for language models as their use increases, but prior work tends to study only one or two of these characteristics at a time. To measure progress towards the combined goal, we introduce the task of pronoun fidelity: given a context introducing a co-referring entity and pronoun, the task is to reuse the correct pronoun later. We present RUFF, a carefully-designed dataset of over 5 million instances to measure robust pronoun fidelity in English, and we evaluate 37 popular large language models across architectures (encoder-only, decoder-only and encoder-decoder) and scales (11M-70B parameters). When an individual is introduced with a pronoun, models can mostly faithfully reuse this pronoun in the next sentence, but they are significantly worse with she/her/her, singular they and neopronouns. Moreover, models are easily distracted by non-adversarial sentences discussing other people; even one additional sentence with a distractor pronoun causes accuracy to drop on average by 34%. Our results show that pronoun fidelity is neither robust, nor due to reasoning, in a simple, naturalistic setting where humans achieve nearly 100% accuracy. We encourage researchers to bridge the gaps we find and to carefully evaluate reasoning in settings where superficial repetition might inflate perceptions of model performance.
5/3/2024
Investigating Markers and Drivers of Gender Bias in Machine Translations
Peter J Barclay (Edinburgh Napier University), Ashkan Sami (Edinburgh Napier University)
0
0
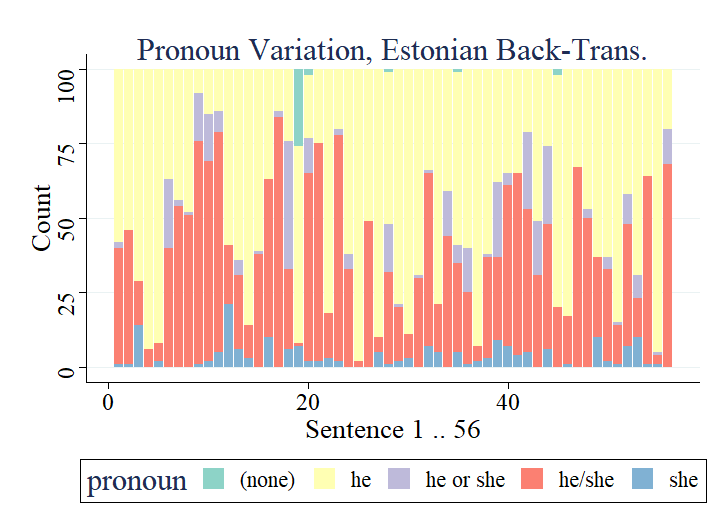
Implicit gender bias in Large Language Models (LLMs) is a well-documented problem, and implications of gender introduced into automatic translations can perpetuate real-world biases. However, some LLMs use heuristics or post-processing to mask such bias, making investigation difficult. Here, we examine bias in LLMss via back-translation, using the DeepL translation API to investigate the bias evinced when repeatedly translating a set of 56 Software Engineering tasks used in a previous study. Each statement starts with 'she', and is translated first into a 'genderless' intermediate language then back into English; we then examine pronoun-choice in the back-translated texts. We expand prior research in the following ways: (1) by comparing results across five intermediate languages, namely Finnish, Indonesian, Estonian, Turkish and Hungarian; (2) by proposing a novel metric for assessing the variation in gender implied in the repeated translations, avoiding the over-interpretation of individual pronouns, apparent in earlier work; (3) by investigating sentence features that drive bias; (4) and by comparing results from three time-lapsed datasets to establish the reproducibility of the approach. We found that some languages display similar patterns of pronoun use, falling into three loose groups, but that patterns vary between groups; this underlines the need to work with multiple languages. We also identify the main verb appearing in a sentence as a likely significant driver of implied gender in the translations. Moreover, we see a good level of replicability in the results, and establish that our variation metric proves robust despite an obvious change in the behaviour of the DeepL translation API during the course of the study. These results show that the back-translation method can provide further insights into bias in language models.
4/3/2024