Tree-based Ensemble Learning for Out-of-distribution Detection
2405.03060
0
0
🔎
Abstract
Being able to successfully determine whether the testing samples has similar distribution as the training samples is a fundamental question to address before we can safely deploy most of the machine learning models into practice. In this paper, we propose TOOD detection, a simple yet effective tree-based out-of-distribution (TOOD) detection mechanism to determine if a set of unseen samples will have similar distribution as of the training samples. The TOOD detection mechanism is based on computing pairwise hamming distance of testing samples' tree embeddings, which are obtained by fitting a tree-based ensemble model through in-distribution training samples. Our approach is interpretable and robust for its tree-based nature. Furthermore, our approach is efficient, flexible to various machine learning tasks, and can be easily generalized to unsupervised setting. Extensive experiments are conducted to show the proposed method outperforms other state-of-the-art out-of-distribution detection methods in distinguishing the in-distribution from out-of-distribution on various tabular, image, and text data.
Create account to get full access
Overview
- Determining whether test samples have a similar distribution as training samples is crucial before deploying machine learning models
- This paper proposes a simple and effective tree-based out-of-distribution (TOOD) detection mechanism to identify if unseen samples have a similar distribution to the training data
- The TOOD approach computes pairwise Hamming distance of testing samples' tree embeddings, obtained by fitting a tree-based ensemble model on the in-distribution training data
- The method is interpretable, robust, efficient, flexible, and can be generalized to unsupervised settings
- Extensive experiments show the proposed TOOD outperforms other state-of-the-art out-of-distribution detection methods
Plain English Explanation
Before using a machine learning model in the real world, it's important to ensure the new data it will analyze is similar to the data it was trained on. This helps avoid unexpected or unreliable results. The paper introduces a simple yet effective way to check if new data has a similar distribution to the original training data.
The approach, called TOOD detection, works by first training a tree-based machine learning model on the original training data. It then takes any new, unseen data samples and compares them to the training data by looking at the "tree embeddings" - a way of representing the data as a tree structure. The key idea is to calculate the Hamming distance, a measure of how different two tree structures are, between the new samples and the training data.
If the new samples have very different tree embeddings compared to the training data, it suggests they have a different distribution and may not be suitable for the model. This TOOD detection method is interpretable (easy to understand), robust, efficient, and can be used for different machine learning tasks, including unsupervised learning.
The paper shows through extensive experiments that TOOD outperforms other state-of-the-art techniques for detecting when new data is different from the original training data. This is an important step in safely deploying machine learning models in the real world.
Technical Explanation
The paper proposes a TOOD detection mechanism to determine if a set of unseen samples have a similar distribution to the training samples. The key idea is to compute the pairwise Hamming distance of the testing samples' tree embeddings, which are obtained by fitting a tree-based ensemble model (e.g., random forest) on the in-distribution training samples.
The TOOD detection approach is based on the intuition that if the testing samples have significantly different tree embeddings compared to the training samples, they are likely to have a different distribution and be considered out-of-distribution. The tree-based nature of the approach makes it interpretable and robust.
The paper conducts extensive experiments on various tabular, image, and text data to show that TOOD outperforms other state-of-the-art out-of-distribution detection methods in distinguishing in-distribution from out-of-distribution samples. The experiments also demonstrate the flexibility of TOOD to be applied to different machine learning tasks, including unsupervised settings.
Critical Analysis
The paper presents a well-designed and comprehensive study on the TOOD detection mechanism. However, the authors acknowledge some limitations and areas for further research. For example, the performance of TOOD may be affected by the quality and representativeness of the training data, which is a common challenge in out-of-distribution detection.
Additionally, the paper does not explore the robustness of TOOD to adversarial attacks, which is an important consideration for real-world deployment of the method. Further research could investigate the vulnerability of TOOD to adversarial perturbations and develop strategies to improve its security.
Overall, the TOOD detection approach appears to be a promising technique for identifying out-of-distribution samples, but additional research is needed to address its limitations and expand its applicability in various domains and settings.
Conclusion
The paper presents a novel TOOD detection mechanism that effectively identifies whether testing samples have a similar distribution to the training samples. This is a crucial step before deploying machine learning models in practice to ensure reliable and robust performance.
The TOOD approach is interpretable, efficient, and flexible, making it suitable for a wide range of machine learning tasks. The extensive experiments demonstrate the method's superior performance compared to other state-of-the-art out-of-distribution detection techniques.
This research contributes to the ongoing efforts in the field to develop robust and reliable machine learning systems that can be safely deployed in real-world applications. The TOOD detection mechanism is a valuable tool for practitioners and researchers to assess the suitability of their machine learning models before putting them into production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024
🧪
A View on Out-of-Distribution Identification from a Statistical Testing Theory Perspective
Alberto Caron, Chris Hicks, Vasilios Mavroudis
0
0
We study the problem of efficiently detecting Out-of-Distribution (OOD) samples at test time in supervised and unsupervised learning contexts. While ML models are typically trained under the assumption that training and test data stem from the same distribution, this is often not the case in realistic settings, thus reliably detecting distribution shifts is crucial at deployment. We re-formulate the OOD problem under the lenses of statistical testing and then discuss conditions that render the OOD problem identifiable in statistical terms. Building on this framework, we study convergence guarantees of an OOD test based on the Wasserstein distance, and provide a simple empirical evaluation.
5/13/2024
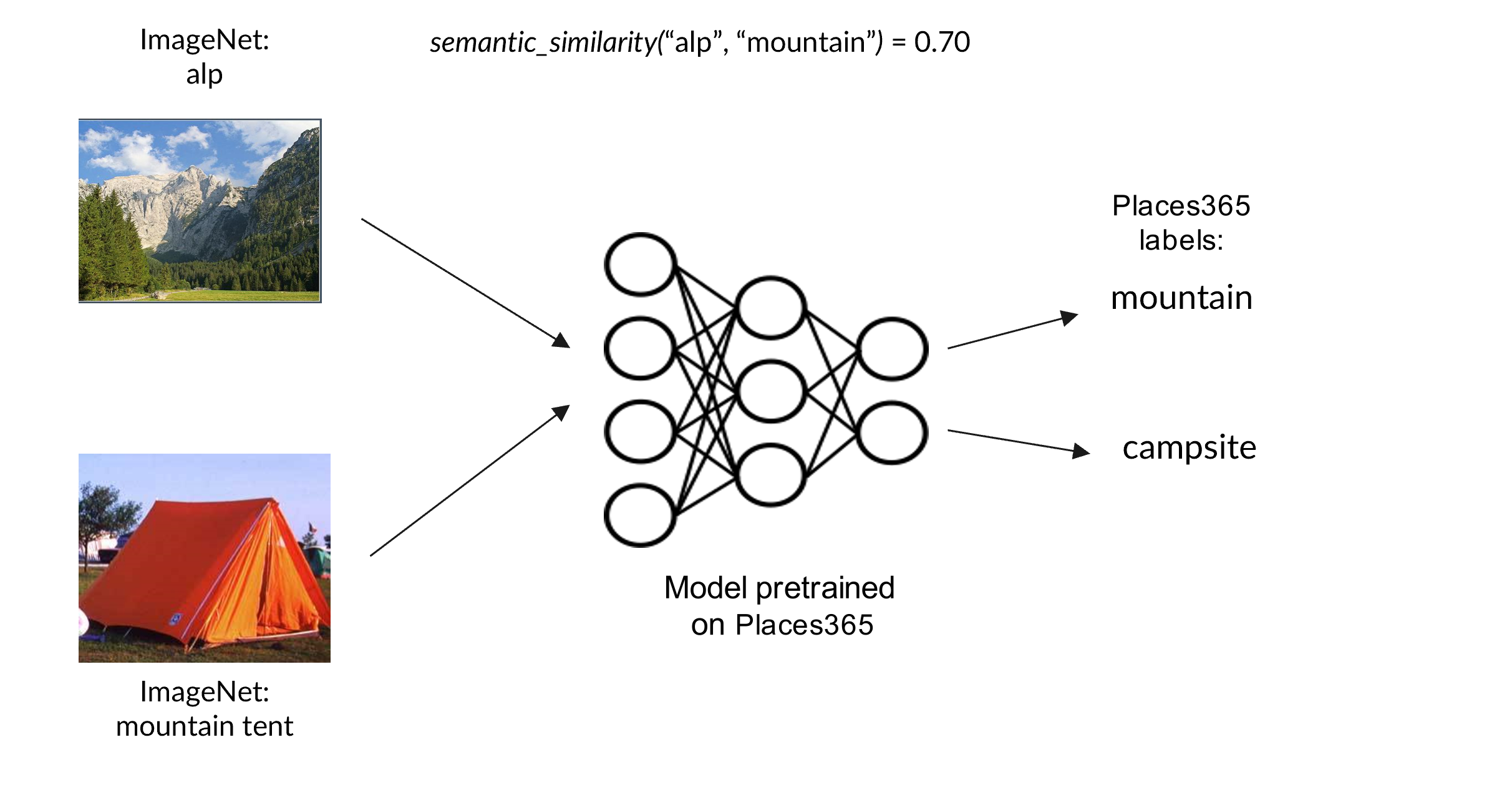
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
0
0
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
4/17/2024
Out-of-distribution Detection in Medical Image Analysis: A survey
Zesheng Hong, Yubiao Yue, Yubin Chen, Huanjie Lin, Yuanmei Luo, Mini Han Wang, Weidong Wang, Jialong Xu, Xiaoqi Yang, Zhenzhang Li, Sihong Xie
0
0
Computer-aided diagnostics has benefited from the development of deep learning-based computer vision techniques in these years. Traditional supervised deep learning methods assume that the test sample is drawn from the identical distribution as the training data. However, it is possible to encounter out-of-distribution samples in real-world clinical scenarios, which may cause silent failure in deep learning-based medical image analysis tasks. Recently, research has explored various out-of-distribution (OOD) detection situations and techniques to enable a trustworthy medical AI system. In this survey, we systematically review the recent advances in OOD detection in medical image analysis. We first explore several factors that may cause a distributional shift when using a deep-learning-based model in clinic scenarios, with three different types of distributional shift well defined on top of these factors. Then a framework is suggested to categorize and feature existing solutions, while the previous studies are reviewed based on the methodology taxonomy. Our discussion also includes evaluation protocols and metrics, as well as the challenge and a research direction lack of exploration.
4/30/2024