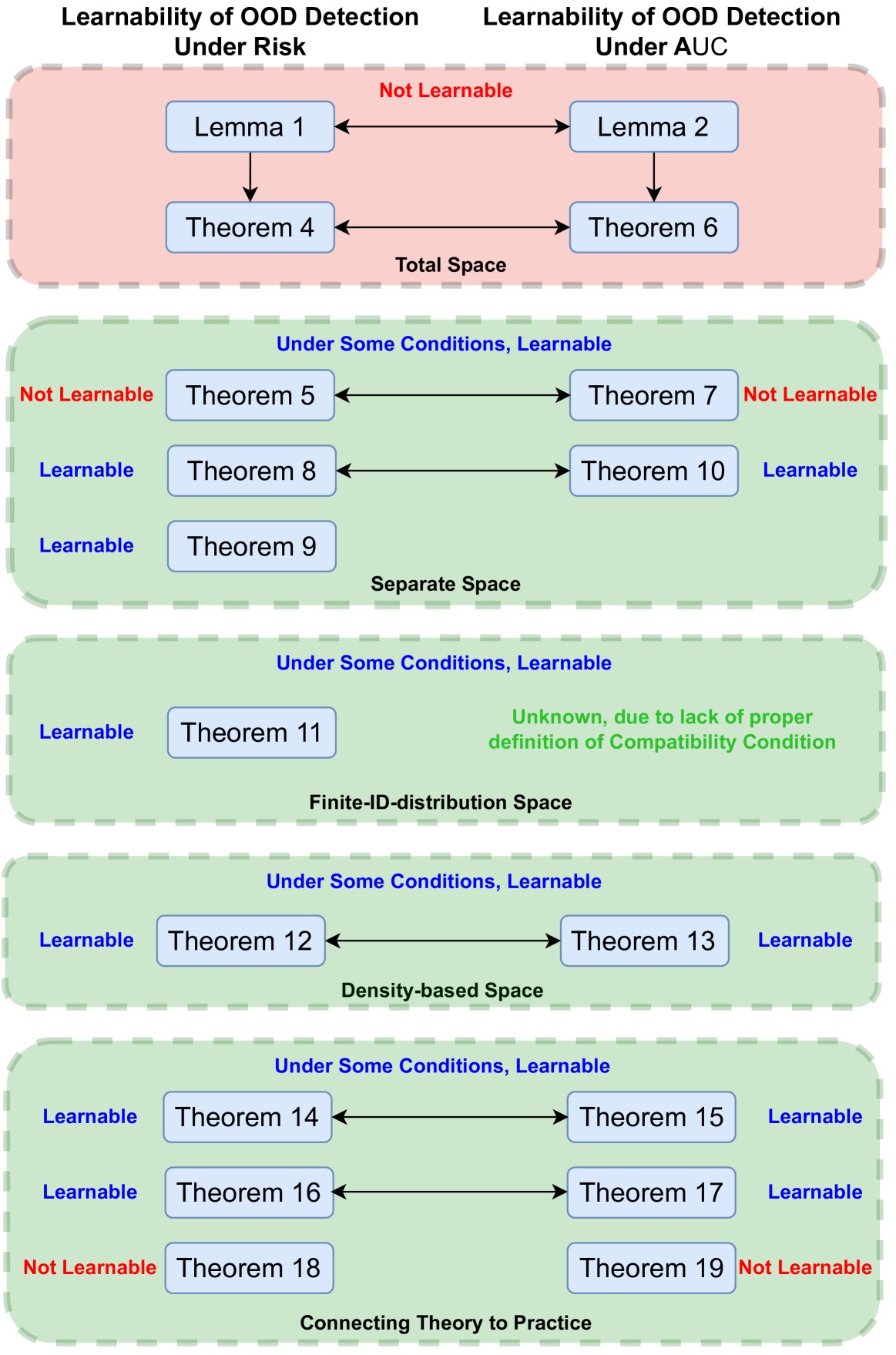
On the Learnability of Out-of-distribution Detection
2404.04865
0
0
Abstract
Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
Create account to get full access
Overview
- The paper investigates the learnability of out-of-distribution (OOD) detection, which is the ability to identify data that is significantly different from the training data.
- The authors provide theoretical and empirical insights into the challenges and limitations of learning OOD detectors, highlighting the fundamental trade-offs involved.
- The findings have implications for the development of more robust and reliable OOD detection systems, which are crucial for the safe deployment of machine learning models in real-world applications.
Plain English Explanation
The paper explores the challenges of teaching machines to identify data that is very different from the information they were originally trained on. This ability, known as out-of-distribution (OOD) detection, is essential for ensuring the safe and reliable use of machine learning models in real-world scenarios.
The researchers provide both theoretical and practical insights into the limitations and trade-offs involved in learning effective OOD detectors. They demonstrate that there are inherent challenges in this task, making it difficult to develop systems that can reliably identify unusual or unfamiliar data.
These findings have important implications for the development of more robust and trustworthy machine learning models. By understanding the fundamental limitations of OOD detection, researchers and practitioners can work towards creating systems that are better equipped to handle unexpected or anomalous data, reducing the risks associated with the deployment of these technologies in critical applications.
The paper's insights may also inspire further research into domain generalization via imprecise learning and negative label-guided OOD detection, as well as information-theoretic frameworks for OOD generalization, all of which aim to address the challenges of out-of-distribution detection.
Technical Explanation
The paper presents a theoretical and empirical investigation into the learnability of OOD detection, which is the ability to identify data that is significantly different from the training distribution. The authors show that there are fundamental trade-offs and limitations inherent in this task, making it challenging to develop reliable OOD detectors.
Theoretically, the paper establishes a connection between the learnability of OOD detection and the notion of uniform convergence, a key concept in statistical learning theory. The authors prove that the sample complexity of learning an OOD detector scales with the intrinsic dimensionality of the data, suggesting that high-dimensional data can pose significant challenges for OOD detection.
Empirically, the authors evaluate the performance of various OOD detection methods, including out-of-distribution data acquaintance via adversarial examples, on a range of benchmark datasets. Their results highlight the limitations of existing approaches and the need for more robust and generalized OOD detection techniques.
The paper's findings have important implications for the development of safe and reliable machine learning systems. By understanding the inherent challenges in OOD detection, researchers and practitioners can work towards creating more robust and trustworthy models that are better equipped to handle unexpected or anomalous data in real-world applications.
Critical Analysis
The paper provides valuable insights into the fundamental limitations of learning OOD detectors, but it also acknowledges several caveats and areas for further research.
One key limitation is the assumption of a specific data model, which may not always reflect the complex and diverse nature of real-world data. The authors suggest that relaxing these assumptions and exploring more general data distributions could lead to a better understanding of OOD detection in practical scenarios.
Additionally, the paper focuses on the sample complexity of learning OOD detectors, but it does not fully address the computational complexity of the task. In practice, the efficiency and scalability of OOD detection algorithms are also crucial considerations, especially for deployment in resource-constrained environments.
The authors also highlight the need for more comprehensive evaluation benchmarks and test cases to better assess the performance of OOD detection methods. The current suite of benchmark datasets may not capture the full range of challenges encountered in real-world applications, and developing more diverse and representative test suites could lead to further insights.
Despite these limitations, the paper's theoretical and empirical findings provide a valuable foundation for future research in this area. By exploring the fundamental trade-offs and challenges of OOD detection, the authors pave the way for the development of more robust and reliable machine learning systems that can better handle the complexities of the real world.
Conclusion
This paper delves into the theoretical and practical challenges of learning effective out-of-distribution (OOD) detectors, which are essential for ensuring the safe and reliable deployment of machine learning models in real-world applications. The authors establish a connection between the learnability of OOD detection and the notion of uniform convergence, highlighting the inherent trade-offs and limitations involved in this task.
The empirical results presented in the paper further underscore the difficulties in developing robust OOD detection systems, suggesting that the high-dimensional nature of data can pose significant challenges. These findings have important implications for the field of machine learning, inspiring future research into domain generalization, negative label-guided OOD detection, and information-theoretic frameworks that can address the fundamental limitations of OOD detection.
By shedding light on the challenges and trade-offs involved in learning OOD detectors, this paper lays the groundwork for the development of more robust and trustworthy machine learning systems that can reliably handle unexpected or anomalous data, ultimately paving the way for the safe and responsible deployment of these technologies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
A View on Out-of-Distribution Identification from a Statistical Testing Theory Perspective
Alberto Caron, Chris Hicks, Vasilios Mavroudis
0
0
We study the problem of efficiently detecting Out-of-Distribution (OOD) samples at test time in supervised and unsupervised learning contexts. While ML models are typically trained under the assumption that training and test data stem from the same distribution, this is often not the case in realistic settings, thus reliably detecting distribution shifts is crucial at deployment. We re-formulate the OOD problem under the lenses of statistical testing and then discuss conditions that render the OOD problem identifiable in statistical terms. Building on this framework, we study convergence guarantees of an OOD test based on the Wasserstein distance, and provide a simple empirical evaluation.
5/13/2024

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024
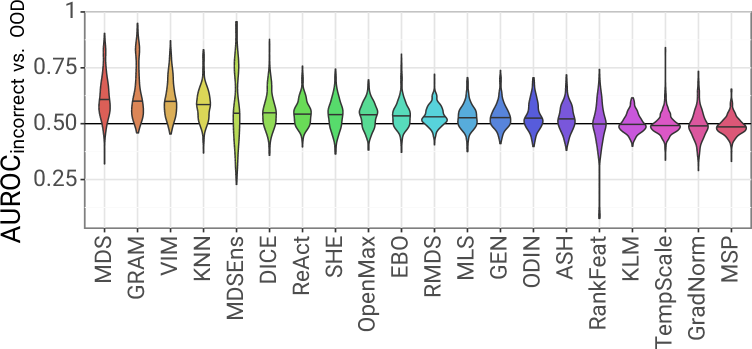
A noisy elephant in the room: Is your out-of-distribution detector robust to label noise?
Galadrielle Humblot-Renaux, Sergio Escalera, Thomas B. Moeslund
0
0
The ability to detect unfamiliar or unexpected images is essential for safe deployment of computer vision systems. In the context of classification, the task of detecting images outside of a model's training domain is known as out-of-distribution (OOD) detection. While there has been a growing research interest in developing post-hoc OOD detection methods, there has been comparably little discussion around how these methods perform when the underlying classifier is not trained on a clean, carefully curated dataset. In this work, we take a closer look at 20 state-of-the-art OOD detection methods in the (more realistic) scenario where the labels used to train the underlying classifier are unreliable (e.g. crowd-sourced or web-scraped labels). Extensive experiments across different datasets, noise types & levels, architectures and checkpointing strategies provide insights into the effect of class label noise on OOD detection, and show that poor separation between incorrectly classified ID samples vs. OOD samples is an overlooked yet important limitation of existing methods. Code: https://github.com/glhr/ood-labelnoise
4/3/2024
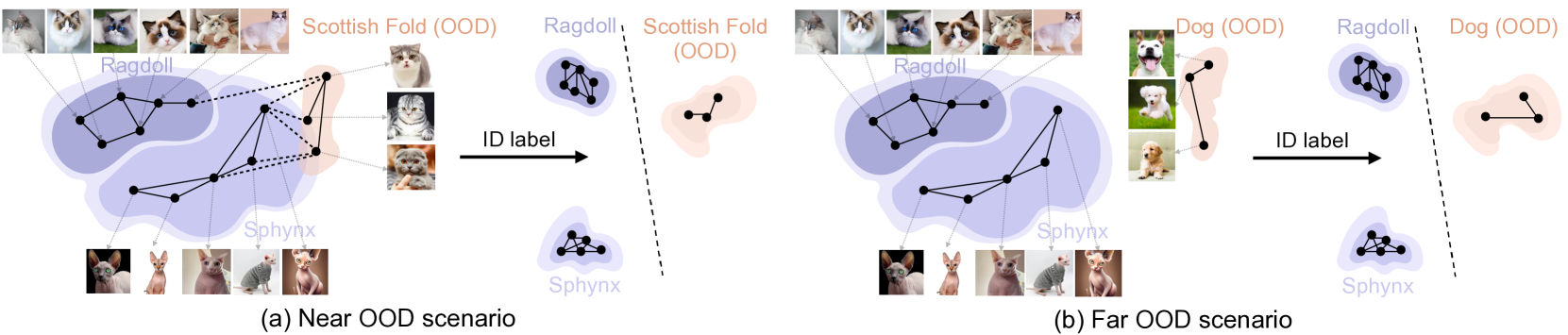
When and How Does In-Distribution Label Help Out-of-Distribution Detection?
Xuefeng Du, Yiyou Sun, Yixuan Li
0
0
Detecting data points deviating from the training distribution is pivotal for ensuring reliable machine learning. Extensive research has been dedicated to the challenge, spanning classical anomaly detection techniques to contemporary out-of-distribution (OOD) detection approaches. While OOD detection commonly relies on supervised learning from a labeled in-distribution (ID) dataset, anomaly detection may treat the entire ID data as a single class and disregard ID labels. This fundamental distinction raises a significant question that has yet to be rigorously explored: when and how does ID label help OOD detection? This paper bridges this gap by offering a formal understanding to theoretically delineate the impact of ID labels on OOD detection. We employ a graph-theoretic approach, rigorously analyzing the separability of ID data from OOD data in a closed-form manner. Key to our approach is the characterization of data representations through spectral decomposition on the graph. Leveraging these representations, we establish a provable error bound that compares the OOD detection performance with and without ID labels, unveiling conditions for achieving enhanced OOD detection. Lastly, we present empirical results on both simulated and real datasets, validating theoretical guarantees and reinforcing our insights. Code is publicly available at https://github.com/deeplearning-wisc/id_label.
5/30/2024